正在加载图片...
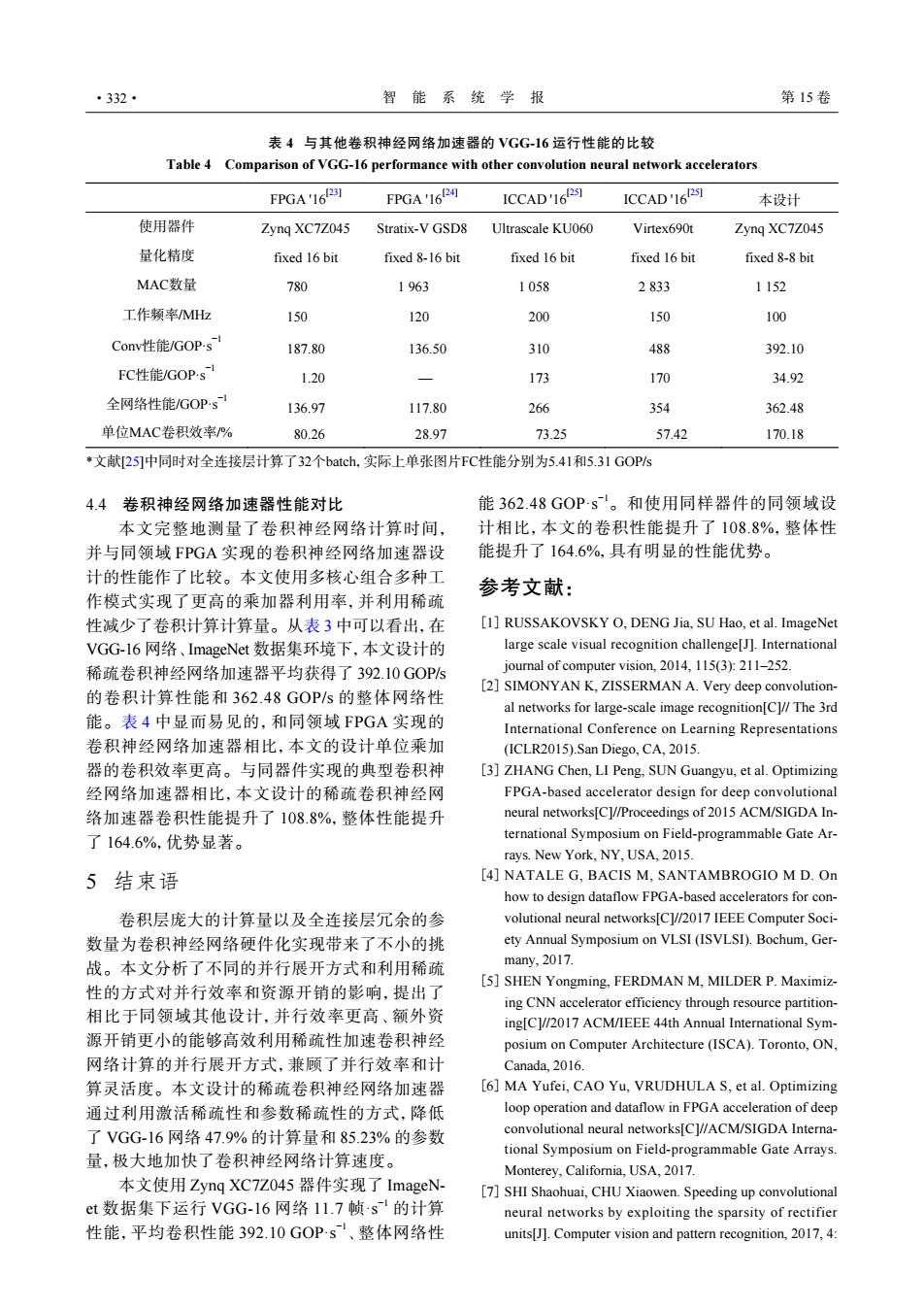
·332· 智能系统学报 第15卷 表4与其他卷积神经网络加速器的VGG-16运行性能的比较 Table 4 Comparison of VGG-16 performance with other convolution neural network accelerators FPGA'16R31 FPGA'16P周 ICCAD'16251 ICCAD'161251 本设计 使用器件 Zyng XC7Z045 Stratix-V GSD8 Ultrascale KU060 Virtex690t Zyng XC7Z045 量化精度 fixed 16 bit fixed 8-16 bit fixed 16 bit fixed 16 bit fixed 8-8 bit MAC数量 780 1963 1058 2833 1152 工作频率MHz 150 120 200 150 100 Conv性能/GOP-s 187.80 136.50 310 488 392.10 FC性能/GOPs 1.20 173 170 34.92 全网络性能/GOPs 136.97 117.80 266 354 362.48 单位MAC卷积效率/% 80.26 28.97 73.25 57.42 170.18 文献25]中同时对全连接层计算了32个batch.,实际上单张图片FC性能分别为5.41和5.31GOP/s 4.4卷积神经网络加速器性能对比 能362.48G0Ps。和使用同样器件的同领域设 本文完整地测量了卷积神经网络计算时间, 计相比,本文的卷积性能提升了108.8%,整体性 并与同领域FPGA实现的卷积神经网络加速器设 能提升了164.6%,具有明显的性能优势。 计的性能作了比较。本文使用多核心组合多种工 参考文献: 作模式实现了更高的乘加器利用率,并利用稀疏 性减少了卷积计算计算量。从表3中可以看出,在 [1]RUSSAKOVSKY O.DENG Jia.SU Hao,et al.ImageNet VGG-l6网络、ImageNet数据集环境下,本文设计的 large scale visual recognition challenge[J.International 稀疏卷积神经网络加速器平均获得了392.10GOPs journal of computer vision,2014,115(3):211-252. 的卷积计算性能和362.48GOP/s的整体网络性 [2]SIMONYAN K,ZISSERMAN A.Very deep convolution- al networks for large-scale image recognition[C]//The 3rd 能。表4中显而易见的,和同领域FPGA实现的 International Conference on Learning Representations 卷积神经网络加速器相比,本文的设计单位乘加 (ICLR2015).San Diego,CA,2015. 器的卷积效率更高。与同器件实现的典型卷积神 [3]ZHANG Chen,LI Peng,SUN Guangyu,et al.Optimizing 经网络加速器相比,本文设计的稀疏卷积神经网 FPGA-based accelerator design for deep convolutional 络加速器卷积性能提升了108.8%,整体性能提升 neural networks[Cl//Proceedings of 2015 ACM/SIGDA In- 了164.6%,优势显著。 ternational Symposium on Field-programmable Gate Ar- rays.New York,NY,USA,2015. 5结束语 [4]NATALE G,BACIS M,SANTAMBROGIO M D.On how to design dataflow FPGA-based accelerators for con- 卷积层庞大的计算量以及全连接层冗余的参 volutional neural networks[C]//2017 IEEE Computer Soci- 数量为卷积神经网络硬件化实现带来了不小的挑 ety Annual Symposium on VLSI(ISVLSI).Bochum,Ger- 战。本文分析了不同的并行展开方式和利用稀疏 many,2017. 性的方式对并行效率和资源开销的影响,提出了 [5]SHEN Yongming,FERDMAN M,MILDER P.Maximiz- ing CNN accelerator efficiency through resource partition- 相比于同领域其他设计,并行效率更高、额外资 ing[C]//2017 ACM/IEEE 44th Annual International Sym- 源开销更小的能够高效利用稀疏性加速卷积神经 posium on Computer Architecture(ISCA).Toronto,ON, 网络计算的并行展开方式,兼顾了并行效率和计 Canada,2016. 算灵活度。本文设计的稀疏卷积神经网络加速器 [6]MA Yufei,CAO Yu,VRUDHULA S,et al.Optimizing 通过利用激活稀疏性和参数稀疏性的方式,降低 loop operation and dataflow in FPGA acceleration of deep 了VGG-16网络47.9%的计算量和85.23%的参数 convolutional neural networks[C]//ACM/SIGDA Interna- tional Symposium on Field-programmable Gate Arrays. 量,极大地加快了卷积神经网络计算速度。 Monterey,California,USA,2017. 本文使用Zynq XC7Z045器件实现了ImageN- [7]SHI Shaohuai,CHU Xiaowen.Speeding up convolutional et数据集下运行VGG-16网络11.7帧·s的计算 neural networks by exploiting the sparsity of rectifier 性能,平均卷积性能392.10GOPs、整体网络性 units[J].Computer vision and pattern recognition,2017,4:4.4 卷积神经网络加速器性能对比 本文完整地测量了卷积神经网络计算时间, 并与同领域 FPGA 实现的卷积神经网络加速器设 计的性能作了比较。本文使用多核心组合多种工 作模式实现了更高的乘加器利用率,并利用稀疏 性减少了卷积计算计算量。从表 3 中可以看出,在 VGG-16 网络、ImageNet 数据集环境下,本文设计的 稀疏卷积神经网络加速器平均获得了 392.10 GOP/s 的卷积计算性能和 362.48 GOP/s 的整体网络性 能。表 4 中显而易见的,和同领域 FPGA 实现的 卷积神经网络加速器相比,本文的设计单位乘加 器的卷积效率更高。与同器件实现的典型卷积神 经网络加速器相比,本文设计的稀疏卷积神经网 络加速器卷积性能提升了 108.8%,整体性能提升 了 164.6%,优势显著。 5 结束语 卷积层庞大的计算量以及全连接层冗余的参 数量为卷积神经网络硬件化实现带来了不小的挑 战。本文分析了不同的并行展开方式和利用稀疏 性的方式对并行效率和资源开销的影响,提出了 相比于同领域其他设计,并行效率更高、额外资 源开销更小的能够高效利用稀疏性加速卷积神经 网络计算的并行展开方式,兼顾了并行效率和计 算灵活度。本文设计的稀疏卷积神经网络加速器 通过利用激活稀疏性和参数稀疏性的方式,降低 了 VGG-16 网络 47.9% 的计算量和 85.23% 的参数 量,极大地加快了卷积神经网络计算速度。 本文使用 Zynq XC7Z045 器件实现了 ImageNet 数据集下运行 VGG-16 网络 11.7 帧·s −1 的计算 性能,平均卷积性能 392.10 GOP·s−1、整体网络性 能 362.48 GOP·s−1。和使用同样器件的同领域设 计相比,本文的卷积性能提升了 108.8%,整体性 能提升了 164.6%,具有明显的性能优势。 参考文献: RUSSAKOVSKY O, DENG Jia, SU Hao, et al. ImageNet large scale visual recognition challenge[J]. International journal of computer vision, 2014, 115(3): 211–252. [1] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]// The 3rd International Conference on Learning Representations (ICLR2015).San Diego, CA, 2015. [2] ZHANG Chen, LI Peng, SUN Guangyu, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks[C]//Proceedings of 2015 ACM/SIGDA International Symposium on Field-programmable Gate Arrays. New York, NY, USA, 2015. [3] NATALE G, BACIS M, SANTAMBROGIO M D. On how to design dataflow FPGA-based accelerators for convolutional neural networks[C]//2017 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). Bochum, Germany, 2017. [4] SHEN Yongming, FERDMAN M, MILDER P. Maximizing CNN accelerator efficiency through resource partitioning[C]//2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA). Toronto, ON, Canada, 2016. [5] MA Yufei, CAO Yu, VRUDHULA S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks[C]//ACM/SIGDA International Symposium on Field-programmable Gate Arrays. Monterey, California, USA, 2017. [6] SHI Shaohuai, CHU Xiaowen. Speeding up convolutional neural networks by exploiting the sparsity of rectifier units[J]. Computer vision and pattern recognition, 2017, 4: [7] 表 4 与其他卷积神经网络加速器的 VGG-16 运行性能的比较 Table 4 Comparison of VGG-16 performance with other convolution neural network accelerators FPGA '16[23] FPGA '16[24] ICCAD '16[25] ICCAD '16[25] 本设计 使用器件 Zynq XC7Z045 Stratix-V GSD8 Ultrascale KU060 Virtex690t Zynq XC7Z045 量化精度 fixed 16 bit fixed 8-16 bit fixed 16 bit fixed 16 bit fixed 8-8 bit MAC数量 780 1 963 1 058 2 833 1 152 工作频率/MHz 150 120 200 150 100 Conv性能/GOP·s−1 187.80 136.50 310 488 392.10 FC性能/GOP·s−1 1.20 — 173 170 34.92 全网络性能/GOP·s−1 136.97 117.80 266 354 362.48 单位MAC卷积效率/% 80.26 28.97 73.25 57.42 170.18 *文献[25]中同时对全连接层计算了32个batch,实际上单张图片FC性能分别为5.41和5.31 GOP/s ·332· 智 能 系 统 学 报 第 15 卷