正在加载图片...
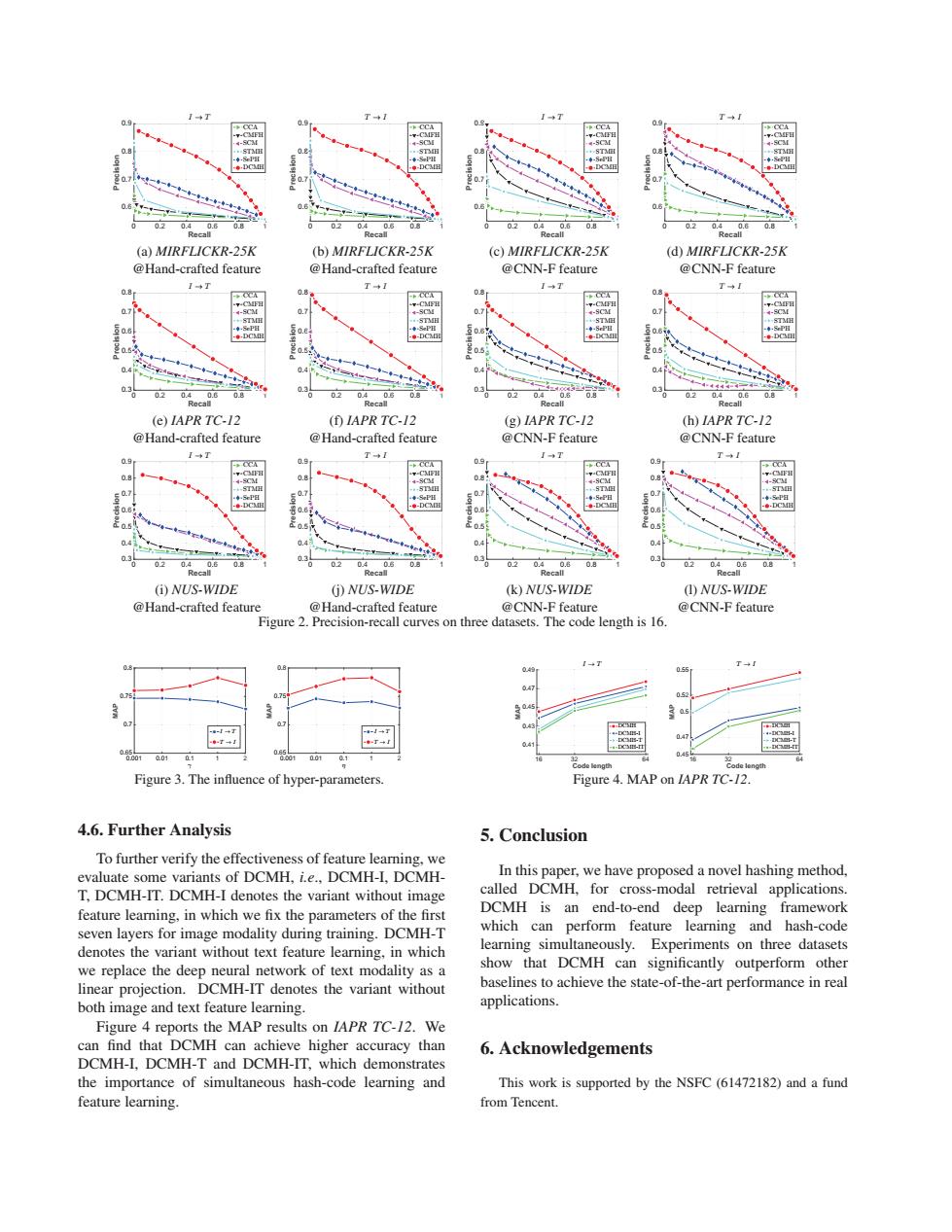
0 09 02 0.8 02 08 0.2 08 a.2 0.8 (a)MIRFLICKR-25K (b)MIRFLICKR-25K (c)MIRFLICKR-25K (d)MIRFLICKR-25K @Hand-crafted feature @Hand-crafted feature @CNN-F feature @CNN-F feature ◆T T+1 T◆I 0.8 08 05 0.4 04 04 一 03 0.2 0.8 0.36 0立0 30 03 4 02 0.8 (e)IAPR TC-12 (f)IAPR TC-12 (g)IAPR TC-12 (h)IAPR TC-12 @Hand-crafted feature @Hand-crafted feature @CNN-F feature @CNN-F feature T+1 1→T T+1 0.9 09 09 0.8 08 0.7 07 -e-DC e-DC 0.6 左05 04 04 0.3 0.3 03 0.8 0.2 08 02 0.8 (NUS-WIDE (i)NUS-WIDE (k)NUS-WIDE (①)NUS-WIDE @Hand-crafted feature @Hand-crafted feature @CNN-F feature @CNN-F feature Figure 2.Precision-recall curves on three datasets.The code length is 16. 07 + .01 0.45 Code length Code length Figure 3.The influence of hyper-parameters. Figure 4.MAP on IAPR TC-/2. 4.6.Further Analysis 5.Conclusion To further verify the effectiveness of feature learning,we evaluate some variants of DCMH,i.e..DCMH-I,DCMH- In this paper,we have proposed a novel hashing method, T.DCMH-IT.DCMH-I denotes the variant without image called DCMH,for cross-modal retrieval applications. feature learning,in which we fix the parameters of the first DCMH is an end-to-end deep learning framework seven layers for image modality during training.DCMH-T which can perform feature learning and hash-code denotes the variant without text feature learning,in which learning simultaneously.Experiments on three datasets we replace the deep neural network of text modality as a show that DCMH can significantly outperform other linear projection.DCMH-IT denotes the variant without baselines to achieve the state-of-the-art performance in real both image and text feature learning applications. Figure 4 reports the MAP results on IAPR TC-12.We can find that DCMH can achieve higher accuracy than 6.Acknowledgements DCMH-I.DCMH-T and DCMH-IT.which demonstrates the importance of simultaneous hash-code learning and This work is supported by the NSFC(61472182)and a fund feature learning. from Tencent.0 0.2 0.4 0.6 0.8 1 Recall 0.6 0.7 0.8 0.9 Precision (a) MIRFLICKR-25K @Hand-crafted feature 0 0.2 0.4 0.6 0.8 1 Recall 0.6 0.7 0.8 0.9 Precision (b) MIRFLICKR-25K @Hand-crafted feature 0 0.2 0.4 0.6 0.8 1 Recall 0.6 0.7 0.8 0.9 Precision (c) MIRFLICKR-25K @CNN-F feature 0 0.2 0.4 0.6 0.8 1 Recall 0.6 0.7 0.8 0.9 Precision (d) MIRFLICKR-25K @CNN-F feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 Precision (e) IAPR TC-12 @Hand-crafted feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 Precision (f) IAPR TC-12 @Hand-crafted feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 Precision (g) IAPR TC-12 @CNN-F feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 Precision (h) IAPR TC-12 @CNN-F feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Precision (i) NUS-WIDE @Hand-crafted feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Precision (j) NUS-WIDE @Hand-crafted feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Precision (k) NUS-WIDE @CNN-F feature 0 0.2 0.4 0.6 0.8 1 Recall 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Precision (l) NUS-WIDE @CNN-F feature Figure 2. Precision-recall curves on three datasets. The code length is 16. 0.001 0.01 0.1 1 2 0.65 0.7 0.75 0.8 MAP 0.001 0.01 0.1 1 2 0.65 0.7 0.75 0.8 MAP Figure 3. The influence of hyper-parameters. 4.6. Further Analysis To further verify the effectiveness of feature learning, we evaluate some variants of DCMH, i.e., DCMH-I, DCMHT, DCMH-IT. DCMH-I denotes the variant without image feature learning, in which we fix the parameters of the first seven layers for image modality during training. DCMH-T denotes the variant without text feature learning, in which we replace the deep neural network of text modality as a linear projection. DCMH-IT denotes the variant without both image and text feature learning. Figure 4 reports the MAP results on IAPR TC-12. We can find that DCMH can achieve higher accuracy than DCMH-I, DCMH-T and DCMH-IT, which demonstrates the importance of simultaneous hash-code learning and feature learning. 16 32 64 Code length 0.41 0.43 0.45 0.47 0.49 MAP 16 32 64 Code length 0.45 0.47 0.5 0.52 0.55 MAP Figure 4. MAP on IAPR TC-12. 5. Conclusion In this paper, we have proposed a novel hashing method, called DCMH, for cross-modal retrieval applications. DCMH is an end-to-end deep learning framework which can perform feature learning and hash-code learning simultaneously. Experiments on three datasets show that DCMH can significantly outperform other baselines to achieve the state-of-the-art performance in real applications. 6. Acknowledgements This work is supported by the NSFC (61472182) and a fund from Tencent.����������������������������������������������������������������������������������������������