正在加载图片...
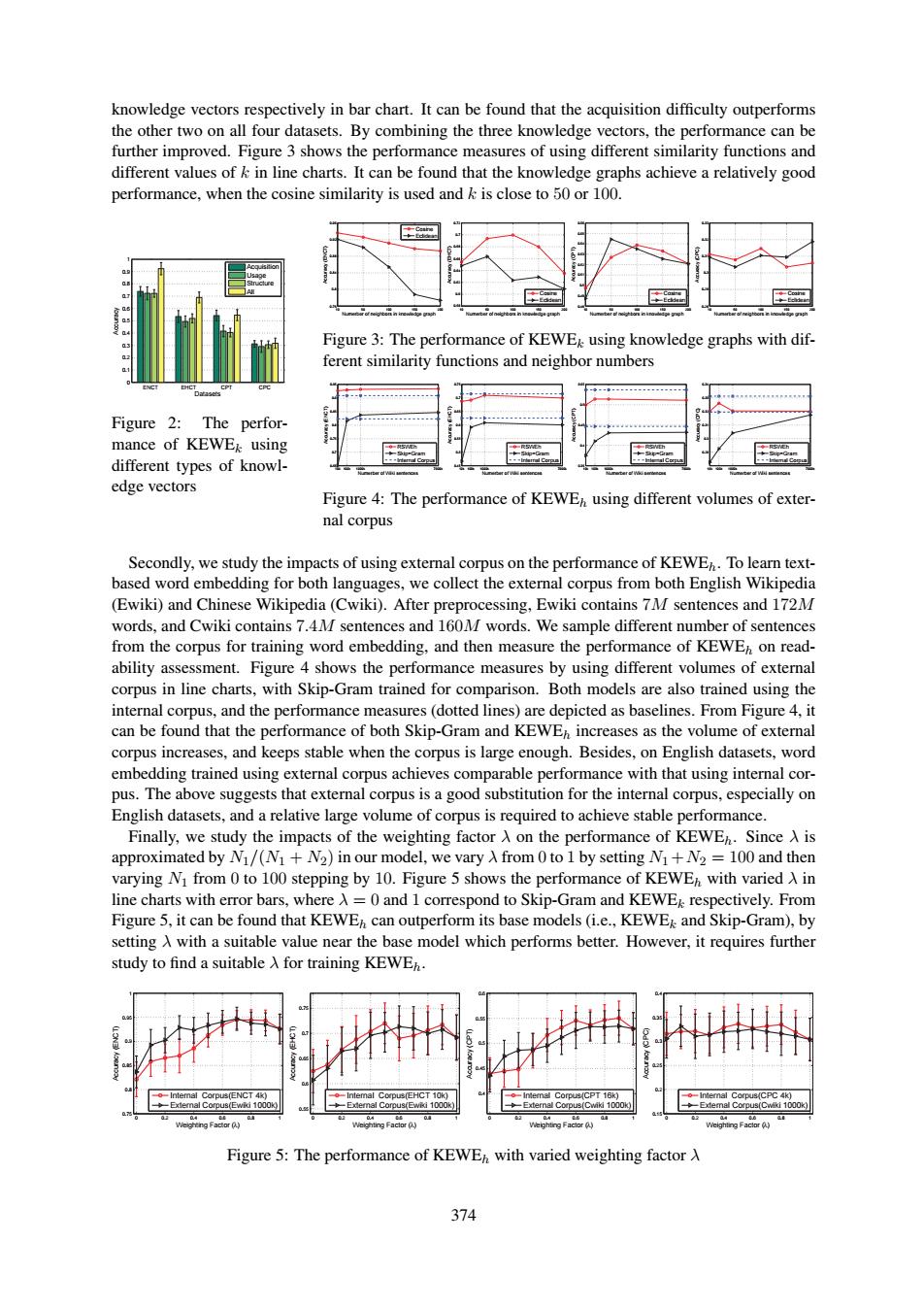
knowledge vectors respectively in bar chart.It can be found that the acquisition difficulty outperforms the other two on all four datasets.By combining the three knowledge vectors,the performance can be further improved.Figure 3 shows the performance measures of using different similarity functions and different values of k in line charts.It can be found that the knowledge graphs achieve a relatively good performance,when the cosine similarity is used and k is close to 50 or 100. a Figure 3:The performance of KEWEk using knowledge graphs with dif- ferent similarity functions and neighbor numbers Figure 2:The perfor- mance of KEWEk using different types of knowl- edge vectors Figure 4:The performance of KEWEh using different volumes of exter- nal corpus Secondly,we study the impacts of using external corpus on the performance of KEWE.To learn text- based word embedding for both languages,we collect the external corpus from both English Wikipedia (Ewiki)and Chinese Wikipedia(Cwiki).After preprocessing,Ewiki contains 7M sentences and 172M words,and Cwiki contains 7.4M sentences and 160M words.We sample different number of sentences from the corpus for training word embedding,and then measure the performance of KEWEh on read- ability assessment.Figure 4 shows the performance measures by using different volumes of external corpus in line charts,with Skip-Gram trained for comparison.Both models are also trained using the internal corpus,and the performance measures(dotted lines)are depicted as baselines.From Figure 4,it can be found that the performance of both Skip-Gram and KEWEh increases as the volume of external corpus increases,and keeps stable when the corpus is large enough.Besides,on English datasets,word embedding trained using external corpus achieves comparable performance with that using internal cor- pus.The above suggests that external corpus is a good substitution for the internal corpus,especially on English datasets,and a relative large volume of corpus is required to achieve stable performance. Finally,we study the impacts of the weighting factor A on the performance of KEWEh.Since A is approximated by Ni/(N1+N2)in our model,we vary X from 0 to 1 by setting Ni+N2=100 and then varying Ni from 0 to 100 stepping by 10.Figure 5 shows the performance of KEWEn with varied A in line charts with error bars,where A=0 and 1 correspond to Skip-Gram and KEWEk respectively.From Figure 5,it can be found that KEWEh can outperform its base models(i.e.,KEWEk and Skip-Gram),by setting A with a suitable value near the base model which performs better.However,it requires further study to find a suitable A for training KEWE. Intemal Corpus(ENCT 4k Corpus(EHCT 10k) mal Corpus(CPT 16k Exemal Corpus(Ewii 1000 nal Corpus(Ewii 1000 enaC0pus( Weigheing Factor 0.) Figure 5:The performance of KEWEh with varied weighting factor A 374374 knowledge vectors respectively in bar chart. It can be found that the acquisition difficulty outperforms the other two on all four datasets. By combining the three knowledge vectors, the performance can be further improved. Figure 3 shows the performance measures of using different similarity functions and different values of k in line charts. It can be found that the knowledge graphs achieve a relatively good performance, when the cosine similarity is used and k is close to 50 or 100. ENCT EHCT CPT CPC 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Datasets Accuracy Acquisition Usage Structure All Figure 2: The performance of KEWEk using different types of knowledge vectors 10 50 100 150 200 0.76 0.8 0.84 0.88 0.92 0.96 Numerber of neighbors in knowledge graph Accuracy (ENCT) Cosine Eclidean 10 50 100 150 200 0.58 0.6 0.62 0.64 0.66 0.68 0.7 0.72 Numerber of neighbors in knowledge graph Accuracy (EHCT) Cosine Eclidean 10 50 100 150 200 0.48 0.49 0.5 0.51 0.52 0.53 0.54 0.55 0.56 Numerber of neighbors in knowledge graph Accuracy (CPT) Cosine Eclidean 10 50 100 150 200 0.28 0.29 0.3 0.31 0.32 0.33 Numerber of neighbors in knowledge graph Accuracy (CPC) Cosine Eclidean Figure 3: The performance of KEWEk using knowledge graphs with different similarity functions and neighbor numbers 10k 100k 1000k 7000k 0.65 0.7 0.75 0.8 0.85 0.9 0.95 Numerber of Wiki sentences Accuracy (ENCT) RSWEh Skip−Gram Internal Corpus 10k 100k 1000k 7000k 0.45 0.5 0.55 0.6 0.65 0.7 0.75 Numerber of Wiki sentences Accuracy (EHCT) RSWEh Skip−Gram Internal Corpus 10k 100k 1000k 7000k 0.35 0.4 0.45 0.5 0.55 Numerber of Wiki sentences Accuracy (CPT) RSWEh Skip−Gram Internal Corpus 10k 100k 1000k 7000k 0.29 0.3 0.31 0.32 0.33 0.34 Numerber of Wiki sentences Accuracy (CPC) RSWEh Skip−Gram Internal Corpus Figure 4: The performance of KEWEh using different volumes of external corpus Secondly, we study the impacts of using external corpus on the performance of KEWEh. To learn textbased word embedding for both languages, we collect the external corpus from both English Wikipedia (Ewiki) and Chinese Wikipedia (Cwiki). After preprocessing, Ewiki contains 7M sentences and 172M words, and Cwiki contains 7.4M sentences and 160M words. We sample different number of sentences from the corpus for training word embedding, and then measure the performance of KEWEh on readability assessment. Figure 4 shows the performance measures by using different volumes of external corpus in line charts, with Skip-Gram trained for comparison. Both models are also trained using the internal corpus, and the performance measures (dotted lines) are depicted as baselines. From Figure 4, it can be found that the performance of both Skip-Gram and KEWEh increases as the volume of external corpus increases, and keeps stable when the corpus is large enough. Besides, on English datasets, word embedding trained using external corpus achieves comparable performance with that using internal corpus. The above suggests that external corpus is a good substitution for the internal corpus, especially on English datasets, and a relative large volume of corpus is required to achieve stable performance. Finally, we study the impacts of the weighting factor λ on the performance of KEWEh. Since λ is approximated by N1/(N1 + N2) in our model, we vary λ from 0 to 1 by setting N1+N2 = 100 and then varying N1 from 0 to 100 stepping by 10. Figure 5 shows the performance of KEWEh with varied λ in line charts with error bars, where λ = 0 and 1 correspond to Skip-Gram and KEWEk respectively. From Figure 5, it can be found that KEWEh can outperform its base models (i.e., KEWEk and Skip-Gram), by setting λ with a suitable value near the base model which performs better. However, it requires further study to find a suitable λ for training KEWEh. 0 0.2 0.4 0.6 0.8 1 0.75 0.8 0.85 0.9 0.95 1 Weighting Factor (λ) Accuracy (ENCT) Internal Corpus(ENCT 4k) External Corpus(Ewiki 1000k) 0 0.2 0.4 0.6 0.8 1 0.55 0.6 0.65 0.7 0.75 Weighting Factor (λ) Accuracy (EHCT) Internal Corpus(EHCT 10k) External Corpus(Ewiki 1000k) 0 0.2 0.4 0.6 0.8 1 0.4 0.45 0.5 0.55 0.6 Weighting Factor (λ) Accuracy (CPT) Internal Corpus(CPT 16k) External Corpus(Cwiki 1000k) 0 0.2 0.4 0.6 0.8 1 0.15 0.2 0.25 0.3 0.35 0.4 Weighting Factor (λ) Accuracy (CPC) Internal Corpus(CPC 4k) External Corpus(Cwiki 1000k) Figure 5: The performance of KEWEh with varied weighting factor λ