正在加载图片...
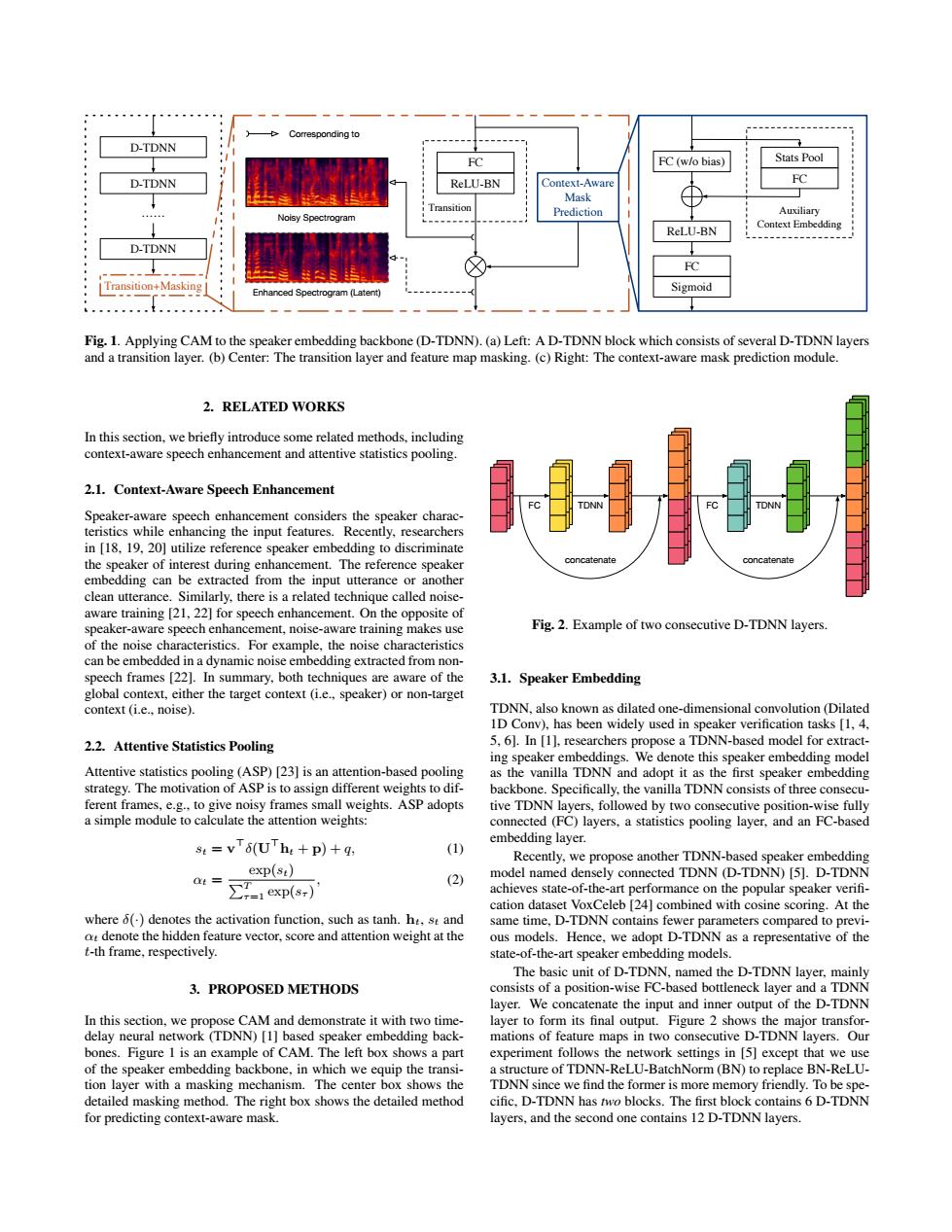
-Corresponding to D-TDNN FC FC (w/o bias) Stats Pool D-TDNN ReLU-BN Context-Aware FC Mask Transition Noisy Spectrogram Prediction Auxiliary ReLU-BN Context Embedding D-TDNN FC Transition+-Masking】 Enhanced Spectrogram (Latent) Sigmoid 。。。。。。 Fig.1.Applying CAM to the speaker embedding backbone(D-TDNN).(a)Left:A D-TDNN block which consists of several D-TDNN layers and a transition layer.(b)Center:The transition layer and feature map masking.(c)Right:The context-aware mask prediction module. 2.RELATED WORKS In this section,we briefly introduce some related methods,including context-aware speech enhancement and attentive statistics pooling. 2.1.Context-Aware Speech Enhancement Speaker-aware speech enhancement considers the speaker charac- teristics while enhancing the input features.Recently,researchers in [18,19,20]utilize reference speaker embedding to discriminate the speaker of interest during enhancement.The reference speaker H时 embedding can be extracted from the input utterance or another clean utterance.Similarly,there is a related technique called noise- aware training [21,22]for speech enhancement.On the opposite of speaker-aware speech enhancement,noise-aware training makes use Fig.2.Example of two consecutive D-TDNN layers. of the noise characteristics.For example,the noise characteristics can be embedded in a dynamic noise embedding extracted from non- speech frames [22].In summary,both techniques are aware of the 3.1.Speaker Embedding global context,either the target context (i.e.,speaker)or non-target context (i.e..noise). TDNN.also known as dilated one-dimensional convolution (Dilated 1D Conv),has been widely used in speaker verification tasks [1,4, 2.2.Attentive Statistics Pooling 5.61.In [1],researchers propose a TDNN-based model for extract- ing speaker embeddings.We denote this speaker embedding model Attentive statistics pooling (ASP)[23]is an attention-based pooling as the vanilla TDNN and adopt it as the first speaker embedding strategy.The motivation of ASP is to assign different weights to dif- backbone.Specifically,the vanilla TDNN consists of three consecu- ferent frames,e.g.,to give noisy frames small weights.ASP adopts tive TDNN layers.followed by two consecutive position-wise fully a simple module to calculate the attention weights: connected (FC)layers.a statistics pooling layer,and an FC-based s:=vT6(UThe +p)+q, embedding layer. (1) Recently,we propose another TDNN-based speaker embedding exp(st) ot= (2) model named densely connected TDNN (D-TDNN)[5].D-TDNN ∑T-1exp(s-) achieves state-of-the-art performance on the popular speaker verifi- cation dataset VoxCeleb [24]combined with cosine scoring.At the where 6()denotes the activation function,such as tanh.ht,st and same time,D-TDNN contains fewer parameters compared to previ- at denote the hidden feature vector,score and attention weight at the ous models.Hence,we adopt D-TDNN as a representative of the t-th frame,respectively. state-of-the-art speaker embedding models. The basic unit of D-TDNN,named the D-TDNN layer,mainly 3.PROPOSED METHODS consists of a position-wise FC-based bottleneck layer and a TDNN layer.We concatenate the input and inner output of the D-TDNN In this section,we propose CAM and demonstrate it with two time- layer to form its final output.Figure 2 shows the major transfor- delay neural network (TDNN)[1]based speaker embedding back- mations of feature maps in two consecutive D-TDNN layers.Our bones.Figure 1 is an example of CAM.The left box shows a part experiment follows the network settings in [5]except that we use of the speaker embedding backbone,in which we equip the transi- a structure of TDNN-ReLU-BatchNorm(BN)to replace BN-ReLU- tion layer with a masking mechanism.The center box shows the TDNN since we find the former is more memory friendly.To be spe- detailed masking method.The right box shows the detailed method cific,D-TDNN has two blocks.The first block contains 6 D-TDNN for predicting context-aware mask. layers,and the second one contains 12 D-TDNN layers.Stats Pool FC Auxiliary Context Embedding Sigmoid ReLU-BN FC FC (w/o bias) Context-Aware Mask Prediction FC ReLU-BN Transition Corresponding to Enhanced Spectrogram (Latent) Noisy Spectrogram D-TDNN Transition+Masking D-TDNN …… D-TDNN Fig. 1. Applying CAM to the speaker embedding backbone (D-TDNN). (a) Left: A D-TDNN block which consists of several D-TDNN layers and a transition layer. (b) Center: The transition layer and feature map masking. (c) Right: The context-aware mask prediction module. 2. RELATED WORKS In this section, we briefly introduce some related methods, including context-aware speech enhancement and attentive statistics pooling. 2.1. Context-Aware Speech Enhancement Speaker-aware speech enhancement considers the speaker characteristics while enhancing the input features. Recently, researchers in [18, 19, 20] utilize reference speaker embedding to discriminate the speaker of interest during enhancement. The reference speaker embedding can be extracted from the input utterance or another clean utterance. Similarly, there is a related technique called noiseaware training [21, 22] for speech enhancement. On the opposite of speaker-aware speech enhancement, noise-aware training makes use of the noise characteristics. For example, the noise characteristics can be embedded in a dynamic noise embedding extracted from nonspeech frames [22]. In summary, both techniques are aware of the global context, either the target context (i.e., speaker) or non-target context (i.e., noise). 2.2. Attentive Statistics Pooling Attentive statistics pooling (ASP) [23] is an attention-based pooling strategy. The motivation of ASP is to assign different weights to different frames, e.g., to give noisy frames small weights. ASP adopts a simple module to calculate the attention weights: st = v >δ(U >ht + p) + q, (1) αt = exp(st) PT τ=1 exp(sτ ) , (2) where δ(·) denotes the activation function, such as tanh. ht, st and αt denote the hidden feature vector, score and attention weight at the t-th frame, respectively. 3. PROPOSED METHODS In this section, we propose CAM and demonstrate it with two timedelay neural network (TDNN) [1] based speaker embedding backbones. Figure 1 is an example of CAM. The left box shows a part of the speaker embedding backbone, in which we equip the transition layer with a masking mechanism. The center box shows the detailed masking method. The right box shows the detailed method for predicting context-aware mask. FC TDNN concatenate FC TDNN concatenate Fig. 2. Example of two consecutive D-TDNN layers. 3.1. Speaker Embedding TDNN, also known as dilated one-dimensional convolution (Dilated 1D Conv), has been widely used in speaker verification tasks [1, 4, 5, 6]. In [1], researchers propose a TDNN-based model for extracting speaker embeddings. We denote this speaker embedding model as the vanilla TDNN and adopt it as the first speaker embedding backbone. Specifically, the vanilla TDNN consists of three consecutive TDNN layers, followed by two consecutive position-wise fully connected (FC) layers, a statistics pooling layer, and an FC-based embedding layer. Recently, we propose another TDNN-based speaker embedding model named densely connected TDNN (D-TDNN) [5]. D-TDNN achieves state-of-the-art performance on the popular speaker verifi- cation dataset VoxCeleb [24] combined with cosine scoring. At the same time, D-TDNN contains fewer parameters compared to previous models. Hence, we adopt D-TDNN as a representative of the state-of-the-art speaker embedding models. The basic unit of D-TDNN, named the D-TDNN layer, mainly consists of a position-wise FC-based bottleneck layer and a TDNN layer. We concatenate the input and inner output of the D-TDNN layer to form its final output. Figure 2 shows the major transformations of feature maps in two consecutive D-TDNN layers. Our experiment follows the network settings in [5] except that we use a structure of TDNN-ReLU-BatchNorm (BN) to replace BN-ReLUTDNN since we find the former is more memory friendly. To be specific, D-TDNN has two blocks. The first block contains 6 D-TDNN layers, and the second one contains 12 D-TDNN layers