正在加载图片...
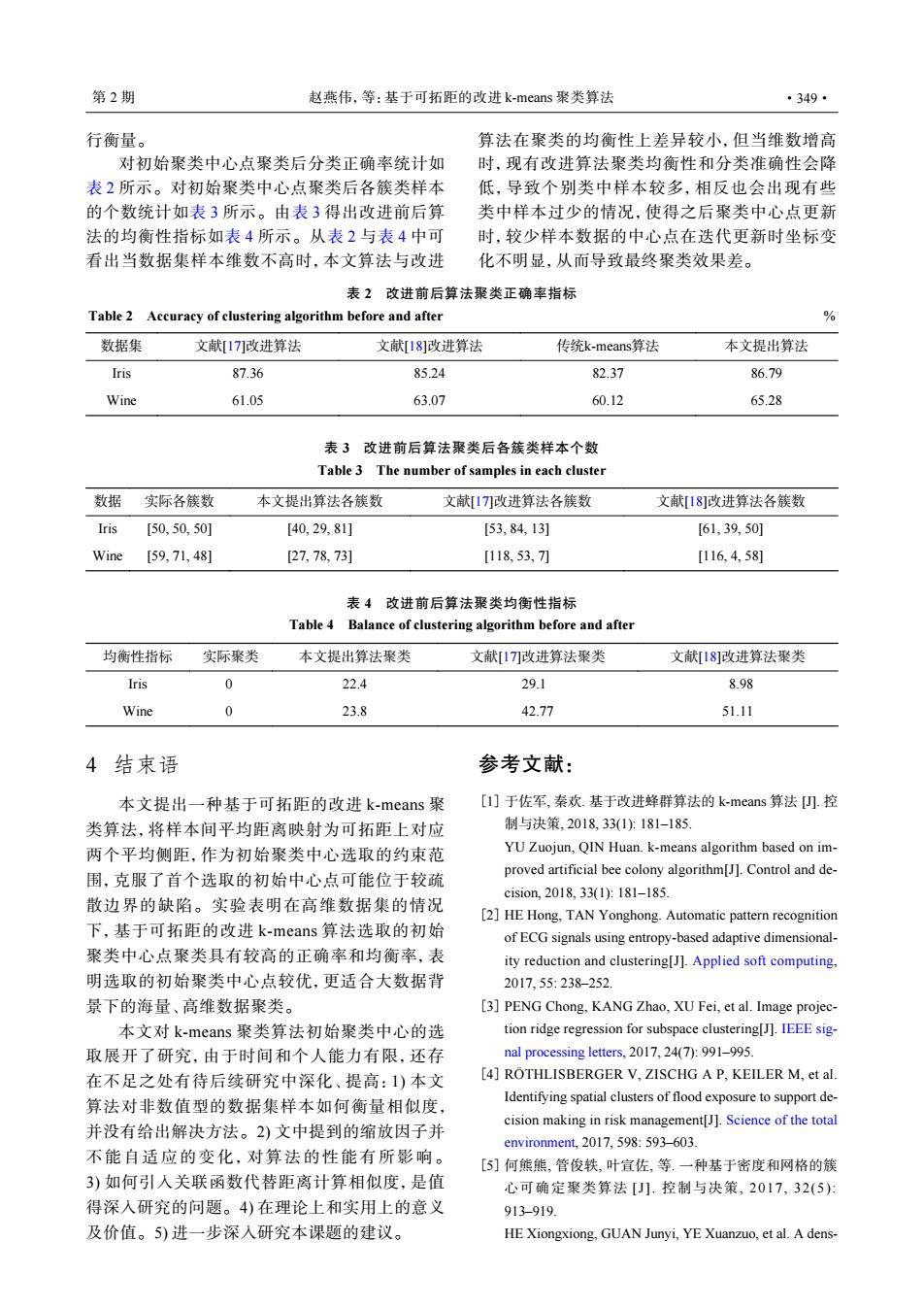
第2期 赵燕伟,等:基于可拓距的改进k-means聚类算法 ·349· 行衡量。 算法在聚类的均衡性上差异较小,但当维数增高 对初始聚类中心点聚类后分类正确率统计如 时,现有改进算法聚类均衡性和分类准确性会降 表2所示。对初始聚类中心点聚类后各簇类样本 低,导致个别类中样本较多,相反也会出现有些 的个数统计如表3所示。由表3得出改进前后算 类中样本过少的情况,使得之后聚类中心点更新 法的均衡性指标如表4所示。从表2与表4中可 时,较少样本数据的中心点在迭代更新时坐标变 看出当数据集样本维数不高时,本文算法与改进 化不明显,从而导致最终聚类效果差。 表2改进前后算法聚类正确率指标 Table 2 Accuracy of clustering algorithm before and after % 数据集 文献[17改进算法 文献[18]改进算法 传统k-means?算法 本文提出算法 Iris 87.36 85.24 82.37 86.79 Wine 61.05 63.07 60.12 65.28 表3改进前后算法聚类后各簇类样本个数 Table 3 The number of samples in each cluster 数据 实际各簇数 本文提出算法各簇数 文献[1刀改进算法各簇数 文献[18]改进算法各簇数 Iris [50,50,50] [40,29,81] [53,84,13] [61,39,50] Wine [59,71,48] [27,78,73] [118,53,7刀 [116,4,58] 表4改进前后算法聚类均衡性指标 Table 4 Balance of clustering algorithm before and after 均衡性指标 实际聚类 本文提出算法聚类 文献[17刀改进算法聚类 文献[18]改进算法聚类 Iris 0 22.4 29.1 8.98 Wine 0 23.8 42.77 51.11 4结束语 参考文献: 本文提出一种基于可拓距的改进k-means聚 [1]于佐军,秦欢.基于改进蜂群算法的k-means算法).控 类算法,将样本间平均距离映射为可拓距上对应 制与决策,2018,33(1)181-185. 两个平均侧距,作为初始聚类中心选取的约束范 YU Zuojun,QIN Huan.k-means algorithm based on im- 围,克服了首个选取的初始中心点可能位于较疏 proved artificial bee colony algorithm[J].Control and de- cision,2018,33(1):181-185 散边界的缺陷。实验表明在高维数据集的情况 [2]HE Hong,TAN Yonghong.Automatic pattern recognition 下,基于可拓距的改进k-means算法选取的初始 of ECG signals using entropy-based adaptive dimensional- 聚类中心点聚类具有较高的正确率和均衡率,表 ity reduction and clustering[J].Applied soft computing, 明选取的初始聚类中心点较优,更适合大数据背 2017,55:238-252 景下的海量、高维数据聚类。 [3]PENG Chong,KANG Zhao,XU Fei,et al.Image projec- 本文对k-means聚类算法初始聚类中心的选 tion ridge regression for subspace clustering[J].IEEE sig- 取展开了研究,由于时间和个人能力有限,还存 nal processing letters,2017,24(7):991-995. 在不足之处有待后续研究中深化、提高:1)本文 [4]ROTHLISBERGER V,ZISCHG A P,KEILER M,et al. 算法对非数值型的数据集样本如何衡量相似度, Identifying spatial clusters of flood exposure to support de- cision making in risk management[J].Science of the total 并没有给出解决方法。2)文中提到的缩放因子并 environment,2017,598:593-603 不能自适应的变化,对算法的性能有所影响。 [5]何熊熊,管俊轶,叶宣佐,等.一种基于密度和网格的簇 3)如何引人关联函数代替距离计算相似度,是值 心可确定聚类算法[J].控制与决策,2017,32(5): 得深人研究的问题。4)在理论上和实用上的意义 913-919. 及价值。5)进一步深入研究本课题的建议。 HE Xiongxiong,GUAN Junyi,YE Xuanzuo,et al.A dens-行衡量。 对初始聚类中心点聚类后分类正确率统计如 表 2 所示。对初始聚类中心点聚类后各簇类样本 的个数统计如表 3 所示。由表 3 得出改进前后算 法的均衡性指标如表 4 所示。从表 2 与表 4 中可 看出当数据集样本维数不高时,本文算法与改进 算法在聚类的均衡性上差异较小,但当维数增高 时,现有改进算法聚类均衡性和分类准确性会降 低,导致个别类中样本较多,相反也会出现有些 类中样本过少的情况,使得之后聚类中心点更新 时,较少样本数据的中心点在迭代更新时坐标变 化不明显,从而导致最终聚类效果差。 表 2 改进前后算法聚类正确率指标 Table 2 Accuracy of clustering algorithm before and after % 数据集 文献[17]改进算法 文献[18]改进算法 传统k-means算法 本文提出算法 Iris 87.36 85.24 82.37 86.79 Wine 61.05 63.07 60.12 65.28 表 3 改进前后算法聚类后各簇类样本个数 Table 3 The number of samples in each cluster 数据 实际各簇数 本文提出算法各簇数 文献[17]改进算法各簇数 文献[18]改进算法各簇数 Iris [50, 50, 50] [40, 29, 81] [53, 84, 13] [61, 39, 50] Wine [59, 71, 48] [27, 78, 73] [118, 53, 7] [116, 4, 58] 表 4 改进前后算法聚类均衡性指标 Table 4 Balance of clustering algorithm before and after 均衡性指标 实际聚类 本文提出算法聚类 文献[17]改进算法聚类 文献[18]改进算法聚类 Iris 0 22.4 29.1 8.98 Wine 0 23.8 42.77 51.11 4 结束语 本文提出一种基于可拓距的改进 k-means 聚 类算法,将样本间平均距离映射为可拓距上对应 两个平均侧距,作为初始聚类中心选取的约束范 围,克服了首个选取的初始中心点可能位于较疏 散边界的缺陷。实验表明在高维数据集的情况 下,基于可拓距的改进 k-means 算法选取的初始 聚类中心点聚类具有较高的正确率和均衡率,表 明选取的初始聚类中心点较优,更适合大数据背 景下的海量、高维数据聚类。 本文对 k-means 聚类算法初始聚类中心的选 取展开了研究,由于时间和个人能力有限,还存 在不足之处有待后续研究中深化、提高:1) 本文 算法对非数值型的数据集样本如何衡量相似度, 并没有给出解决方法。2) 文中提到的缩放因子并 不能自适应的变化,对算法的性能有所影响。 3) 如何引入关联函数代替距离计算相似度,是值 得深入研究的问题。4) 在理论上和实用上的意义 及价值。5) 进一步深入研究本课题的建议。 参考文献: 于佐军, 秦欢. 基于改进蜂群算法的 k-means 算法 [J]. 控 制与决策, 2018, 33(1): 181–185. YU Zuojun, QIN Huan. k-means algorithm based on improved artificial bee colony algorithm[J]. Control and decision, 2018, 33(1): 181–185. [1] HE Hong, TAN Yonghong. Automatic pattern recognition of ECG signals using entropy-based adaptive dimensionality reduction and clustering[J]. Applied soft computing, 2017, 55: 238–252. [2] PENG Chong, KANG Zhao, XU Fei, et al. Image projection ridge regression for subspace clustering[J]. IEEE signal processing letters, 2017, 24(7): 991–995. [3] RÖTHLISBERGER V, ZISCHG A P, KEILER M, et al. Identifying spatial clusters of flood exposure to support decision making in risk management[J]. Science of the total environment, 2017, 598: 593–603. [4] 何熊熊, 管俊轶, 叶宣佐, 等. 一种基于密度和网格的簇 心可确定聚类算法 [J]. 控制与决策, 2017, 32(5): 913–919. HE Xiongxiong, GUAN Junyi, YE Xuanzuo, et al. A dens- [5] 第 2 期 赵燕伟,等:基于可拓距的改进 k-means 聚类算法 ·349·