正在加载图片...
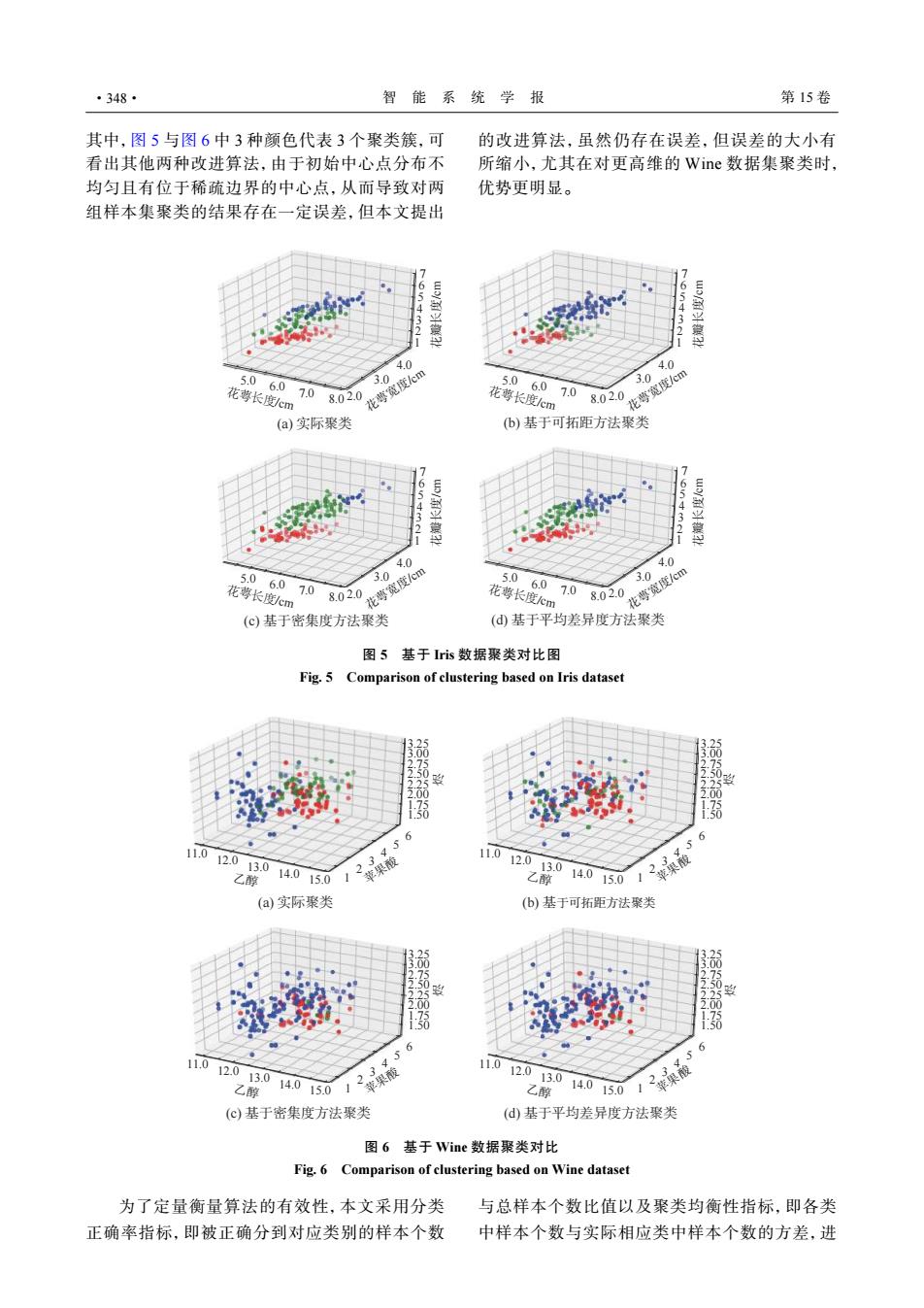
·348· 智能系统学报 第15卷 其中,图5与图6中3种颜色代表3个聚类簇,可 的改进算法,虽然仍存在误差,但误差的大小有 看出其他两种改进算法,由于初始中心点分布不 所缩小,尤其在对更高维的Wine数据集聚类时, 均匀且有位于稀疏边界的中心点,从而导致对两 优势更明显。 组样本集聚类的结果存在一定误差,但本文提出 654321 654 321 4.0 4.0 5.0 6.0 花萼宽度cm 3.0 5.0 花萼长度/c 7.08.02. 6.0 3.0 花萼长度cm 7.0 020花普0暖@ (a)实际聚类 (b)基于可拓距方法聚类 6543 765 43 2 21 4.0 4.0 5.0 3.0 6.0 花萼宽度cm 5.0 3.0 花萼长度cm 7.0 6.0 8.02. 花萼长度em 7.0 8.02. 花萼宽度/cm (c)基于密集度方法聚 (d基于平均差异度方法聚类 图5基于Iris数据聚类对比图 Fig.5 Comparison of clustering based on Iris dataset 13.25 00 222, 11.012.0 3¥6 13.0 11.012.0 13.0 乙醇 1401502线梁 (a)实际聚类 (b)基于可拓距方法聚类 1 50 11.0 12.0 11.0 12.0 13.0 13.0 乙醇 1050了20 乙醇 14.015.0 (c)基于密集度方法聚类 (d)基于平均差异度方法聚类 图6基于Wine数据聚类对比 Fig.6 Comparison of clustering based on Wine dataset 为了定量衡量算法的有效性,本文采用分类 与总样本个数比值以及聚类均衡性指标,即各类 正确率指标,即被正确分到对应类别的样本个数 中样本个数与实际相应类中样本个数的方差,进其中,图 5 与图 6 中 3 种颜色代表 3 个聚类簇,可 看出其他两种改进算法,由于初始中心点分布不 均匀且有位于稀疏边界的中心点,从而导致对两 组样本集聚类的结果存在一定误差,但本文提出 的改进算法,虽然仍存在误差,但误差的大小有 所缩小,尤其在对更高维的 Wine 数据集聚类时, 优势更明显。 (a) 实际聚类 7 6 5 4 3 2 1 花瓣长度/cm 花萼长度/cm 8.0 2.0 7.0 6.0 5.0 3.0 花萼宽度/cm 4.0 (b) 基于可拓距方法聚类 7 6 5 4 3 2 1 花瓣长度/cm 花萼长度/cm 8.0 2.0 7.0 6.0 5.0 3.0 花萼宽度/cm 4.0 (c) 基于密集度方法聚类 7 6 5 4 3 2 1 花瓣长度/cm 花萼长度/cm 8.0 2.0 7.0 6.0 5.0 3.0 花萼宽度/cm 4.0 (d) 基于平均差异度方法聚类 7 6 5 4 3 2 1 花瓣长度/cm 花萼长度/cm 8.0 2.0 7.0 6.0 5.0 3.0 花萼宽度/cm 4.0 图 5 基于 Iris 数据聚类对比图 Fig. 5 Comparison of clustering based on Iris dataset (a) 实际聚类 3.25 3.00 2.75 2.50 2.25 2.00 1.75 1.50 烬 乙醇 15.0 1 14.0 13.0 12.0 11.0 3 2 苹果酸 6 5 4 (b) 基于可拓距方法聚类 3.25 3.00 2.75 2.50 2.25 2.00 1.75 1.50 烬 乙醇 15.0 1 14.0 13.0 12.0 11.0 3 2 苹果酸 6 5 4 (c) 基于密集度方法聚类 3.25 3.00 2.75 2.50 2.25 2.00 1.75 1.50 烬 乙醇 15.0 1 14.0 13.0 12.0 11.0 3 2 苹果酸 6 5 4 (d) 基于平均差异度方法聚类 3.25 3.00 2.75 2.50 2.25 2.00 1.75 1.50 烬 乙醇 15.0 1 14.0 13.0 12.0 11.0 3 2 苹果酸 6 5 4 图 6 基于 Wine 数据聚类对比 Fig. 6 Comparison of clustering based on Wine dataset 为了定量衡量算法的有效性,本文采用分类 正确率指标,即被正确分到对应类别的样本个数 与总样本个数比值以及聚类均衡性指标,即各类 中样本个数与实际相应类中样本个数的方差,进 ·348· 智 能 系 统 学 报 第 15 卷