正在加载图片...
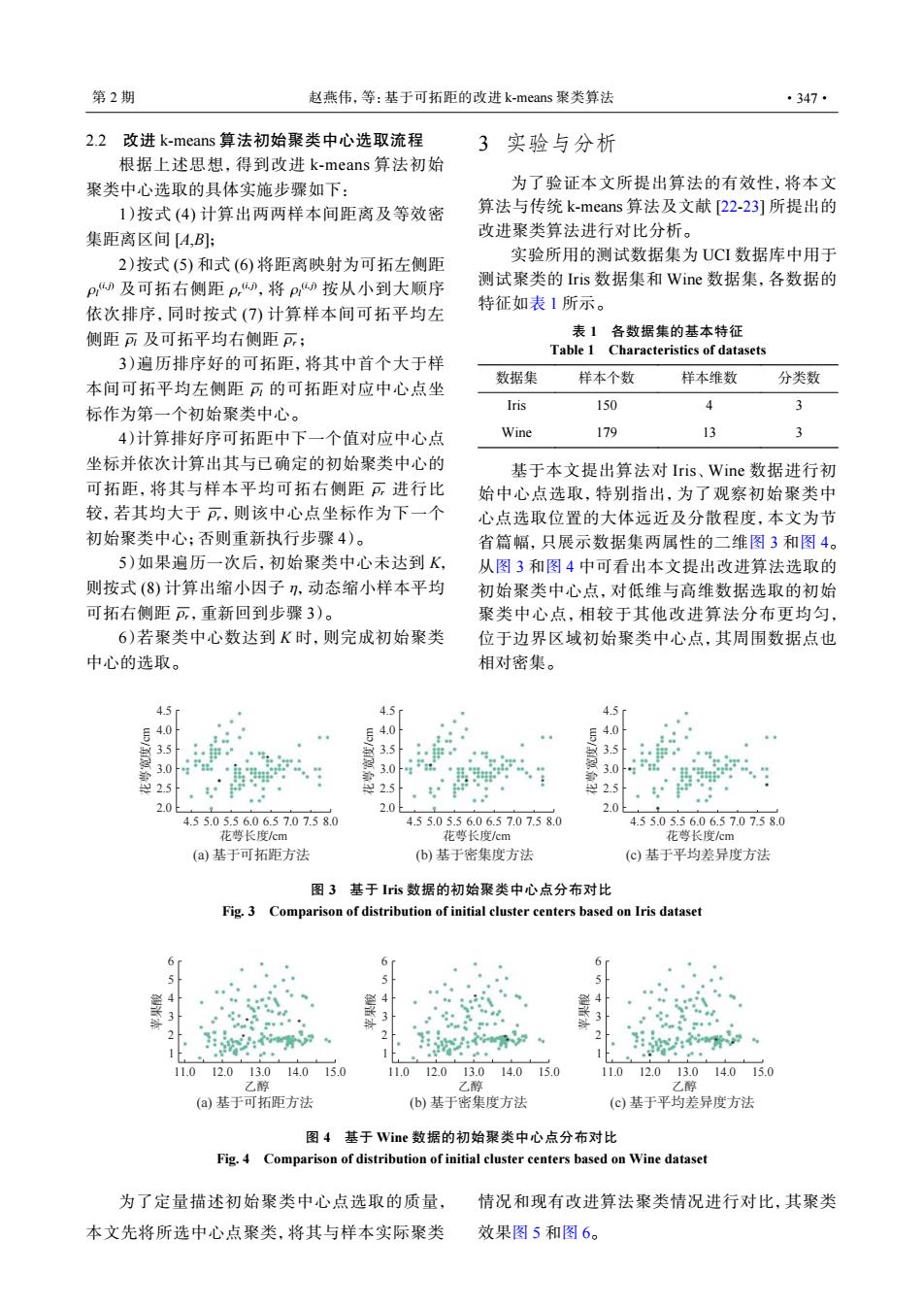
第2期 赵燕伟,等:基于可拓距的改进k-means聚类算法 ·347· 2.2改进k-means算法初始聚类中心选取流程 3实验与分析 根据上述思想,得到改进k-means算法初始 聚类中心选取的具体实施步骤如下: 为了验证本文所提出算法的有效性,将本文 1)按式(4)计算出两两样本间距离及等效密 算法与传统k-means算法及文献[22-23]所提出的 集距离区间[A,B]: 改进聚类算法进行对比分析。 2)按式(5)和式(6)将距离映射为可拓左侧距 实验所用的测试数据集为UCI数据库中用于 pD及可拓右侧距P,D,将p按从小到大顺序 测试聚类的Iris数据集和Wine数据集,各数据的 依次排序,同时按式(7)计算样本间可拓平均左 特征如表1所示。 侧距可及可拓平均右侧距p; 表1 各数据集的基本特征 Table 1 Characteristics of datasets 3)遍历排序好的可拓距,将其中首个大于样 数据集 样本维数 本间可拓平均左侧距可的可拓距对应中心点坐 样本个数 分类数 标作为第一个初始聚类中心。 Iris 150 4)计算排好序可拓距中下一个值对应中心点 Wine 179 3 坐标并依次计算出其与已确定的初始聚类中心的 基于本文提出算法对Iris、Wine数据进行初 可拓距,将其与样本平均可拓右侧距F进行比 始中心点选取,特别指出,为了观察初始聚类中 较,若其均大于可,则该中心点坐标作为下一个 心点选取位置的大体远近及分散程度,本文为节 初始聚类中心;否则重新执行步骤4)。 省篇幅,只展示数据集两属性的二维图3和图4。 5)如果遍历一次后,初始聚类中心未达到K, 从图3和图4中可看出本文提出改进算法选取的 则按式(8)计算出缩小因子,动态缩小样本平均 初始聚类中心点,对低维与高维数据选取的初始 可拓右侧距可,重新回到步骤3)。 聚类中心点,相较于其他改进算法分布更均匀, 6)若聚类中心数达到K时,则完成初始聚类 位于边界区域初始聚类中心点,其周围数据点也 中心的选取。 相对密集。 4.5r 4.5 4.5 840 号4.0 84.0 35 35 35 3.0 3.0 3.0 25 2.5 2.0 2.0上 2.0 4.55.05.56.06.57.07.58.0 4.55.05.56.06.57.07.58.0 4.55.05.56.06.57.07.58.0 花萼长度/cm 花萼长度/cm 花萼长度/cm (a)基于可拓距方法 (b)基于密集度方法 (c)基于平均差异度方法 图3基于Iis数据的初始聚类中心点分布对比 Fig.3 Comparison of distribution of initial cluster centers based on Iris dataset 6 6 6 5 5 5 …… 34 2 2 3 1 11.0 12.013.014.0 15.0 11.012.013.0 14.015.0 11.0 12.013.014.015.0 乙醇 乙醇 乙醇 (a)基于可拓距方法 (b)基于密集度方法 (c)基于平均差异度方法 图4基于Wine数据的初始聚类中心点分布对比 Fig.4 Comparison of distribution of initial cluster centers based on Wine dataset 为了定量描述初始聚类中心点选取的质量, 情况和现有改进算法聚类情况进行对比,其聚类 本文先将所选中心点聚类,将其与样本实际聚类 效果图5和图6。2.2 改进 k-means 算法初始聚类中心选取流程 根据上述思想,得到改进 k-means 算法初始 聚类中心选取的具体实施步骤如下: 1)按式 (4) 计算出两两样本间距离及等效密 集距离区间 [A,B]; ρl (i, j) ρr (i, j) ρl (i, j) ρl ρr 2)按式 (5) 和式 (6) 将距离映射为可拓左侧距 及可拓右侧距 ,将 按从小到大顺序 依次排序,同时按式 (7) 计算样本间可拓平均左 侧距 及可拓平均右侧距 ; ρl 3)遍历排序好的可拓距,将其中首个大于样 本间可拓平均左侧距 的可拓距对应中心点坐 标作为第一个初始聚类中心。 ρr ρr 4)计算排好序可拓距中下一个值对应中心点 坐标并依次计算出其与已确定的初始聚类中心的 可拓距,将其与样本平均可拓右侧距 进行比 较,若其均大于 ,则该中心点坐标作为下一个 初始聚类中心;否则重新执行步骤 4)。 η ρr 5)如果遍历一次后,初始聚类中心未达到 K, 则按式 (8) 计算出缩小因子 ,动态缩小样本平均 可拓右侧距 ,重新回到步骤 3)。 6)若聚类中心数达到 K 时,则完成初始聚类 中心的选取。 3 实验与分析 为了验证本文所提出算法的有效性,将本文 算法与传统 k-means 算法及文献 [22-23] 所提出的 改进聚类算法进行对比分析。 实验所用的测试数据集为 UCI 数据库中用于 测试聚类的 Iris 数据集和 Wine 数据集,各数据的 特征如表 1 所示。 表 1 各数据集的基本特征 Table 1 Characteristics of datasets 数据集 样本个数 样本维数 分类数 Iris 150 4 3 Wine 179 13 3 基于本文提出算法对 Iris、Wine 数据进行初 始中心点选取,特别指出,为了观察初始聚类中 心点选取位置的大体远近及分散程度,本文为节 省篇幅,只展示数据集两属性的二维图 3 和图 4。 从图 3 和图 4 中可看出本文提出改进算法选取的 初始聚类中心点,对低维与高维数据选取的初始 聚类中心点,相较于其他改进算法分布更均匀, 位于边界区域初始聚类中心点,其周围数据点也 相对密集。 (a) 基于可拓距方法 4.5 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 4.0 3.5 3.0 花萼宽度/cm 花萼长度/cm 2.5 2.0 (c) 基于平均差异度方法 4.5 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 4.0 3.5 3.0 花萼宽度/cm 花萼长度/cm 2.5 2.0 (b) 基于密集度方法 4.5 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 4.0 3.5 3.0 花萼宽度/cm 花萼长度/cm 2.5 2.0 图 3 基于 Iris 数据的初始聚类中心点分布对比 Fig. 3 Comparison of distribution of initial cluster centers based on Iris dataset (a) 基于可拓距方法 6 11.0 12.0 13.0 14.0 15.0 5 4 3 苹果酸 乙醇 2 1 (b) 基于密集度方法 6 11.0 12.0 13.0 14.0 15.0 5 4 3 苹果酸 乙醇 2 1 (c) 基于平均差异度方法 6 11.0 12.0 13.0 14.0 15.0 5 4 3 苹果酸 乙醇 2 1 图 4 基于 Wine 数据的初始聚类中心点分布对比 Fig. 4 Comparison of distribution of initial cluster centers based on Wine dataset 为了定量描述初始聚类中心点选取的质量, 本文先将所选中心点聚类,将其与样本实际聚类 情况和现有改进算法聚类情况进行对比,其聚类 效果图 5 和图 6。 第 2 期 赵燕伟,等:基于可拓距的改进 k-means 聚类算法 ·347·