正在加载图片...
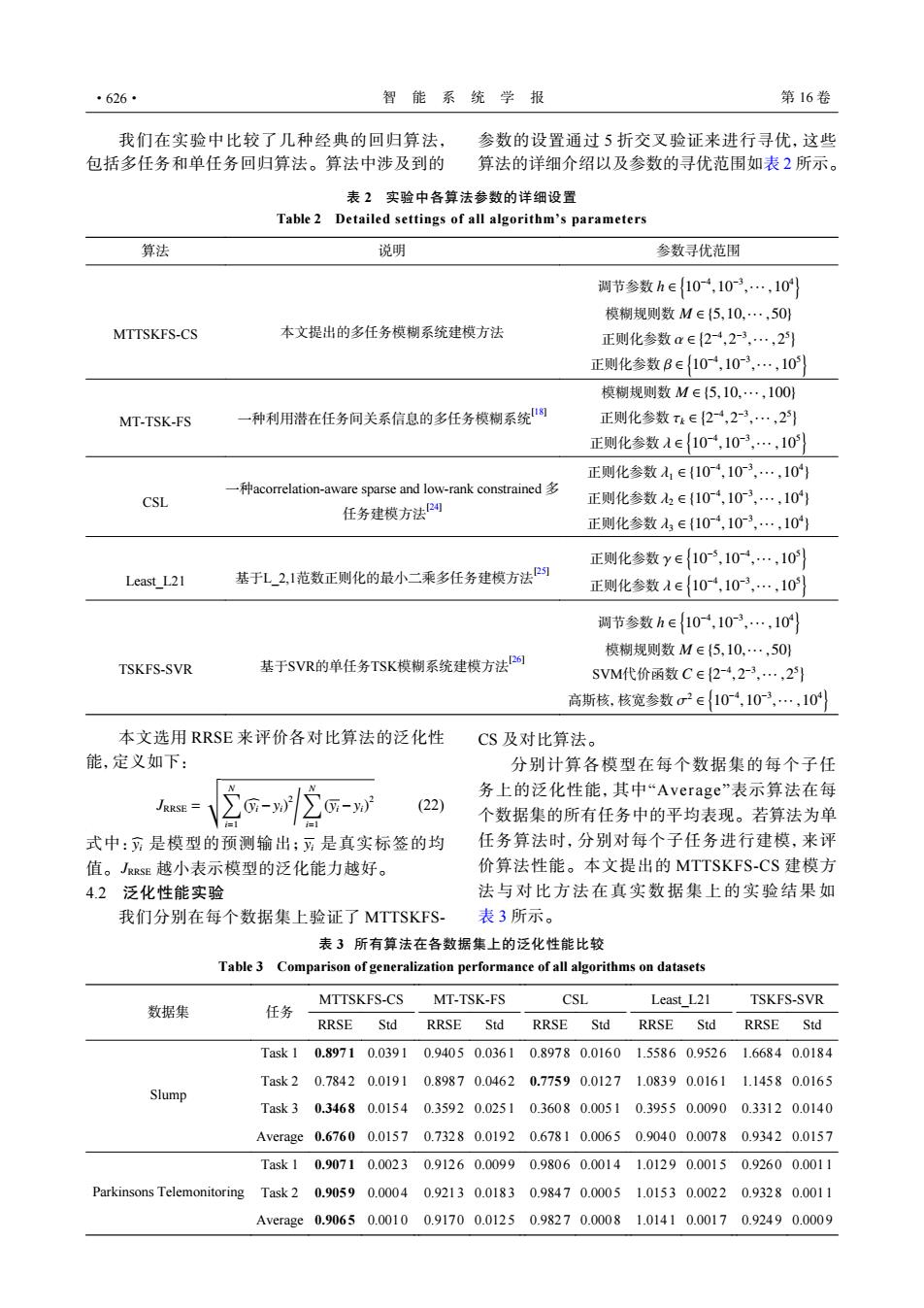
·626· 智能系统学报 第16卷 我们在实验中比较了几种经典的回归算法, 参数的设置通过5折交叉验证来进行寻优,这些 包括多任务和单任务回归算法。算法中涉及到的 算法的详细介绍以及参数的寻优范围如表2所示。 表2实验中各算法参数的详细设置 Table 2 Detailed settings of all algorithm's parameters 算法 说明 参数寻优范围 调节参数h∈{10,103,…,10 模糊规则数M∈{5,10,·,50) MTTSKFS-CS 本文提出的多任务模糊系统建模方法 正则化参数a∈{24,23,…,2 正则化参数B∈10,10-3,…,10 模糊规则数M∈{5,10·,1001 MT-TSK-FS 一种利用潜在任务间关系信息的多任务模糊系统 正则化参数t∈{2,23,…,2到 正则化参数A∈{10,103…,10) 正则化参数1∈{104,10-3,…,10 acorrelation-aware sparse and low-rank constrained CSL 正则化参数2∈{104,103,…,101 任务建模方法2网 正则化参数3∈{10,103,…,10 正则化参数y∈{10,10,…,10 Least_L21 基于L2,1范数正则化的最小二乘多任务建模方法P 正则化参数1∈{10,103,…,10 调节参数h∈{10,103,…,10) 模糊规则数M∈{5,10,·,50) TSKFS-SVR 基于SVR的单任务TSK模糊系统建模方法P阿 SVM代价函数Ce{2-4,23,…,2} 高斯核,核宽参数σ2∈104,103,…,10 本文选用RRSE来评价各对比算法的泛化性 CS及对比算法。 能,定义如下: 分别计算各模型在每个数据集的每个子任 务上的泛化性能,其中“Average”表示算法在每 JRRSE (22) 个数据集的所有任务中的平均表现。若算法为单 式中:是模型的预测输出;方是真实标签的均 任务算法时,分别对每个子任务进行建模,来评 值。RRSE越小表示模型的泛化能力越好。 价算法性能。本文提出的MTTSKFS-CS建模方 42泛化性能实验 法与对比方法在真实数据集上的实验结果如 我们分别在每个数据集上验证了MTTSKFS- 表3所示。 表3所有算法在各数据集上的泛化性能比较 Table 3 Comparison of generalization performance of all algorithms on datasets MTTSKFS-CS MT-TSK-FS TSKFS-SVR 数据集 CSL Least_L21 任务 RRSE Std RRSE Std RRSE Std RRSE Std RRSE Std Task10.89710.0391 0.94050.0361 0.89780.01601.55860.95261.66840.0184 Task20.78420.01910.89870.04620.77590.01271.08390.01611.14580.0165 Slump Task30.34680.01540.35920.02510.36080.00510.39550.00900.33120.0140 Average0.67600.01570.73280.01920.67810.00650.90400.00780.93420.0157 Task10.90710.00230.91260.00990.98060.00141.01290.00150.92600.0011 Parkinsons Telemonitoring Task 2 0.9059 0.0004 0.9213 0.0183 0.9847 0.0005 1.01530.00220.93280.0011 Average0.90650.00100.91700.01250.98270.00081.01410.00170.92490.0009我们在实验中比较了几种经典的回归算法, 包括多任务和单任务回归算法。算法中涉及到的 参数的设置通过 5 折交叉验证来进行寻优,这些 算法的详细介绍以及参数的寻优范围如表 2 所示。 表 2 实验中各算法参数的详细设置 Table 2 Detailed settings of all algorithm’s parameters 算法 说明 参数寻优范围 MTTSKFS-CS 本文提出的多任务模糊系统建模方法 h ∈ { 10−4 ,10−3 ,··· ,104 } M ∈ {5,10,··· ,50} α ∈ { 2 −4 ,2 −3 ,··· ,2 5 } β ∈ { 10−4 ,10−3 ,··· ,105 } 调节参数 模糊规则数 正则化参数 正则化参数 MT-TSK-FS 一种利用潜在任务间关系信息的多任务模糊系统[18] M ∈ {5,10,··· ,100} τk ∈ { 2 −4 ,2 −3 ,··· ,2 5 } λ ∈ { 10−4 ,10−3 ,··· ,105 } 模糊规则数 正则化参数 正则化参数 CSL 一种acorrelation-aware sparse and low-rank constrained 多 任务建模方法[24] λ1 ∈ {10−4 ,10−3 ,··· ,104 } λ2 ∈ {10−4 ,10−3 ,··· ,104 } λ3 ∈ {10−4 ,10−3 ,··· ,104 } 正则化参数 正则化参数 正则化参数 Least_L21 基于L_2,1范数正则化的最小二乘多任务建模方法[25] γ ∈ { 10−5 ,10−4 ,··· ,105 } λ ∈ { 10−4 ,10−3 ,··· ,105 } 正则化参数 正则化参数 TSKFS-SVR 基于SVR的单任务TSK模糊系统建模方法[26] h ∈ { 10−4 ,10−3 ,··· ,104 } M ∈ {5,10,··· ,50} C ∈ { 2 −4 ,2 −3 ,··· ,2 5 } σ 2 ∈ { 10−4 ,10−3 ,··· ,104 } 调节参数 模糊规则数 SVM代价函数 高斯核,核宽参数 本文选用 RRSE 来评价各对比算法的泛化性 能,定义如下: JRRSE = vt∑N i=1 (byi −yi) 2 /∑N i=1 (yi −yi) 2 (22) byi yi JRRSE 式中: 是模型的预测输出; 是真实标签的均 值。 越小表示模型的泛化能力越好。 4.2 泛化性能实验 我们分别在每个数据集上验证了 MTTSKFSCS 及对比算法。 分别计算各模型在每个数据集的每个子任 务上的泛化性能,其中“Average”表示算法在每 个数据集的所有任务中的平均表现。若算法为单 任务算法时,分别对每个子任务进行建模,来评 价算法性能。本文提出的 MTTSKFS-CS 建模方 法与对比方法在真实数据集上的实验结果如 表 3 所示。 表 3 所有算法在各数据集上的泛化性能比较 Table 3 Comparison of generalization performance of all algorithms on datasets 数据集 任务 MTTSKFS-CS MT-TSK-FS CSL Least_L21 TSKFS-SVR RRSE Std RRSE Std RRSE Std RRSE Std RRSE Std Slump Task 1 0.897 1 0.0391 0.940 5 0.0361 0.897 8 0.016 0 1.5586 0.952 6 1.6684 0.018 4 Task 2 0.784 2 0.0191 0.898 7 0.0462 0.775 9 0.012 7 1.0839 0.016 1 1.1458 0.016 5 Task 3 0.346 8 0.0154 0.359 2 0.0251 0.360 8 0.005 1 0.3955 0.009 0 0.3312 0.014 0 Average 0.676 0 0.0157 0.732 8 0.0192 0.678 1 0.006 5 0.9040 0.007 8 0.9342 0.015 7 Parkinsons Telemonitoring Task 1 0.907 1 0.0023 0.912 6 0.0099 0.980 6 0.001 4 1.0129 0.001 5 0.9260 0.001 1 Task 2 0.905 9 0.0004 0.921 3 0.0183 0.984 7 0.000 5 1.0153 0.002 2 0.9328 0.001 1 Average 0.906 5 0.0010 0.917 0 0.0125 0.982 7 0.000 8 1.0141 0.001 7 0.9249 0.000 9 ·626· 智 能 系 统 学 报 第 16 卷