正在加载图片...
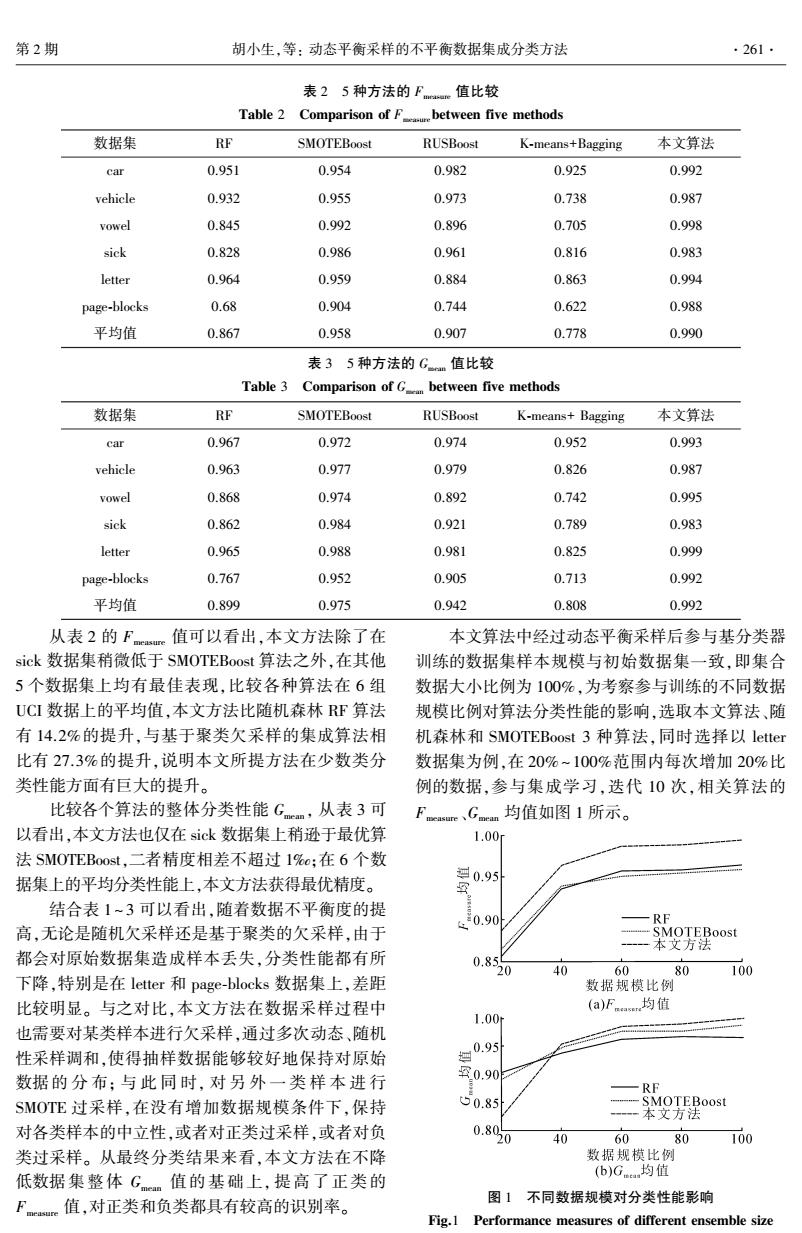
第2期 胡小生,等:动态平衡采样的不平衡数据集成分类方法 ·261- 表25种方法的Fe值比较 Table 2 Comparison of Fbetween five methods 数据集 RF SMOTEBoost RUSBoost K-means+Bagging 本文算法 car 0.951 0.954 0.982 0.925 0.992 vehicle 0.932 0.955 0.973 0.738 0.987 vowel 0.845 0.992 0.896 0.705 0.998 sick 0.828 0.986 0.961 0.816 0.983 letter 0.964 0.959 0.884 0.863 0.994 page-blocks 0.68 0.904 0.744 0.622 0.988 平均值 0.867 0.958 0.907 0.778 0.990 表35种方法的Gm值比较 Table 3 Comparison of G between five methods 数据集 RF SMOTEBoost RUSBoost K-means+Bagging 本文算法 car 0.967 0.972 0.974 0.952 0.993 vehicle 0.963 0.977 0.979 0.826 0.987 vowel 0.868 0.974 0.892 0.742 0.995 sick 0.862 0.984 0.921 0.789 0.983 letter 0.965 0.988 0.981 0.825 0.999 page-blocks 0.767 0.952 0.905 0.713 0.992 平均值 0.899 0.975 0.942 0.808 0.992 从表2的Fmeasure 值可以看出,本文方法除了在 本文算法中经过动态平衡采样后参与基分类器 sick数据集稍微低于SMOTEBoost算法之外,在其他 训练的数据集样本规模与初始数据集一致,即集合 5个数据集上均有最佳表现,比较各种算法在6组 数据大小比例为100%,为考察参与训练的不同数据 UCI数据上的平均值,本文方法比随机森林RF算法 规模比例对算法分类性能的影响,选取本文算法、随 有14.2%的提升,与基于聚类欠采样的集成算法相 机森林和SMOTEBoost3种算法,同时选择以letter 比有27.3%的提升,说明本文所提方法在少数类分 数据集为例,在20%~100%范围内每次增加20%比 类性能方面有巨大的提升。 例的数据,参与集成学习,迭代10次,相关算法的 比较各个算法的整体分类性能Gm,从表3可 Fcrc、Gmn均值如图1所示。 以看出,本文方法也仅在sick数据集上稍逊于最优算 1.00 法SMOTEBoost,二者精度相差不超过1%a;在6个数 据集上的平均分类性能上,本文方法获得最优精度。 0.95 结合表1~3可以看出,随着数据不平衡度的提 飞0.90 RF 高,无论是随机欠采样还是基于聚类的欠采样,由于 -SMOTEBoost 本文方法 都会对原始数据集造成样本丢失,分类性能都有所 0.85 0 40 60 80 100 下降,特别是在letter和page-blocks数据集上,差距 数据规模比例 比较明显。与之对比,本文方法在数据采样过程中 (a)Fa均值 1.00r 也需要对某类样本进行欠采样,通过多次动态、随机 性采样调和,使得抽样数据能够较好地保持对原始 g0.95 数据的分布:与此同时,对另外一类样本进行 罕0.90 —RF SMOTE过采样,在没有增加数据规模条件下,保持 50.85 ---SMOTEBoost 一一本文方法 对各类样本的中立性,或者对正类过采样,或者对负 0.800 40 60 80 100 类过采样。从最终分类结果来看,本文方法在不降 数据规模比例 低数据集整体G值的基础上,提高了正类的 (b)G均值 F。值,对正类和负类都具有较高的识别率。 图1不同数据规模对分类性能影响 Fig.1 Performance measures of different ensemble size表 2 5 种方法的 Fmeasure 值比较 Table 2 Comparison of Fmeasurebetween five methods 数据集 RF SMOTEBoost RUSBoost K⁃means+Bagging 本文算法 car 0.951 0.954 0.982 0.925 0.992 vehicle 0.932 0.955 0.973 0.738 0.987 vowel 0.845 0.992 0.896 0.705 0.998 sick 0.828 0.986 0.961 0.816 0.983 letter 0.964 0.959 0.884 0.863 0.994 page⁃blocks 0.68 0.904 0.744 0.622 0.988 平均值 0.867 0.958 0.907 0.778 0.990 表 3 5 种方法的 Gmean 值比较 Table 3 Comparison of Gmean between five methods 数据集 RF SMOTEBoost RUSBoost K⁃means+ Bagging 本文算法 car 0.967 0.972 0.974 0.952 0.993 vehicle 0.963 0.977 0.979 0.826 0.987 vowel 0.868 0.974 0.892 0.742 0.995 sick 0.862 0.984 0.921 0.789 0.983 letter 0.965 0.988 0.981 0.825 0.999 page⁃blocks 0.767 0.952 0.905 0.713 0.992 平均值 0.899 0.975 0.942 0.808 0.992 从表 2 的 Fmeasure 值可以看出,本文方法除了在 sick 数据集稍微低于 SMOTEBoost 算法之外,在其他 5 个数据集上均有最佳表现,比较各种算法在 6 组 UCI 数据上的平均值,本文方法比随机森林 RF 算法 有 14.2%的提升,与基于聚类欠采样的集成算法相 比有 27.3%的提升,说明本文所提方法在少数类分 类性能方面有巨大的提升。 比较各个算法的整体分类性能 Gmean , 从表 3 可 以看出,本文方法也仅在 sick 数据集上稍逊于最优算 法 SMOTEBoost,二者精度相差不超过 1‰;在 6 个数 据集上的平均分类性能上,本文方法获得最优精度。 结合表 1 ~ 3 可以看出,随着数据不平衡度的提 高,无论是随机欠采样还是基于聚类的欠采样,由于 都会对原始数据集造成样本丢失,分类性能都有所 下降,特别是在 letter 和 page⁃blocks 数据集上,差距 比较明显。 与之对比,本文方法在数据采样过程中 也需要对某类样本进行欠采样,通过多次动态、随机 性采样调和,使得抽样数据能够较好地保持对原始 数据的 分 布; 与 此 同 时, 对 另 外 一 类 样 本 进 行 SMOTE 过采样,在没有增加数据规模条件下,保持 对各类样本的中立性,或者对正类过采样,或者对负 类过采样。 从最终分类结果来看,本文方法在不降 低数据集整体 Gmean 值的基础上, 提高了正类的 Fmeasure 值,对正类和负类都具有较高的识别率。 本文算法中经过动态平衡采样后参与基分类器 训练的数据集样本规模与初始数据集一致,即集合 数据大小比例为 100%,为考察参与训练的不同数据 规模比例对算法分类性能的影响,选取本文算法、随 机森林和 SMOTEBoost 3 种算法,同时选择以 letter 数据集为例,在 20% ~ 100%范围内每次增加 20%比 例的数据,参与集成学习,迭代 10 次,相关算法的 Fmeasure、Gmean 均值如图 1 所示。 图 1 不同数据规模对分类性能影响 Fig.1 Performance measures of different ensemble size 第 2 期 胡小生,等: 动态平衡采样的不平衡数据集成分类方法 ·261·