正在加载图片...
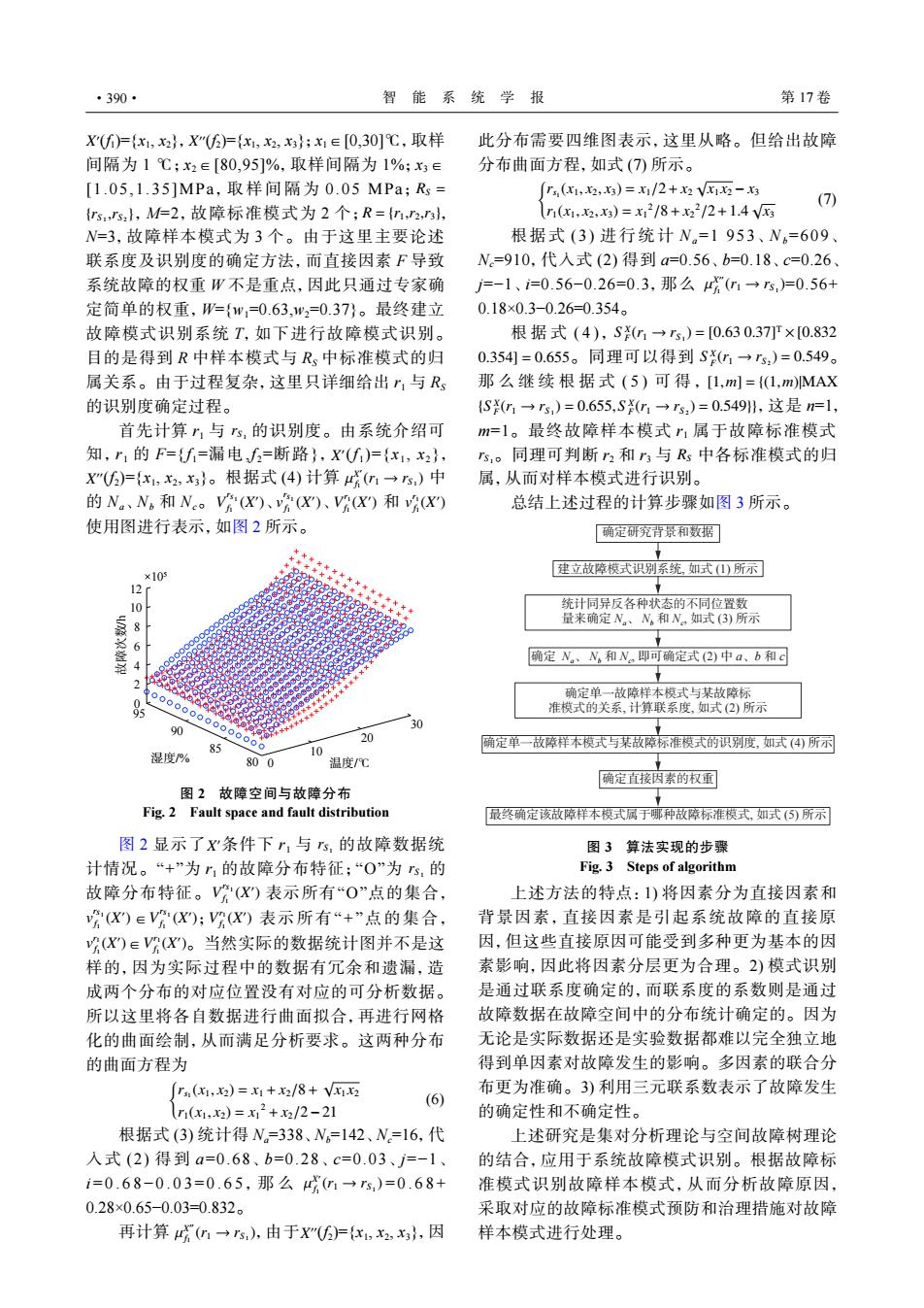
·390· 智能系统学报 第17卷 Xf卢{x,x2},X"5)={x,x2,x3};x1∈[0,30]℃,取样 此分布需要四维图表示,这里从略。但给出故障 间隔为1℃;x2∈[80,95]%,取样间隔为1%;x3∈ 分布曲面方程,如式()所示。 [1.05,1.35]MPa,取样间隔为0.05MPa;R= r(1,x2,x3)=1/2+2√1万-x3 {rssl,M仁2,故障标准模式为2个;R={,2,, n(x1,2,x3)=x2/8+x2/2+1.4V (7) W=3,故障样本模式为3个。由于这里主要论述 根据式(3)进行统计N。=1953、N=609 联系度及识别度的确定方法,而直接因素F导致 N=910,代入式(2)得到a=0.56、b=0.18、c=0.26 系统故障的权重W不是重点,因此只通过专家确 j=-1、=0.56-0.26=0.3,那么(r1→rs,=0.56+ 定简单的权重,W={w,=0.63,w2=0.37}。最终建立 0.18×0.3-0.26=0.354。 故障模式识别系统T,如下进行故障模式识别。 根据式(4),S1→rs,)=[0.630.37]r×[0.832 目的是得到R中样本模式与R、中标准模式的归 0.354=0.655。同理可以得到S¥1→rs:)=0.549。 属关系。由于过程复杂,这里只详细给出,与R 那么继续根据式(5)可得,[1,m={(1,m)MAX 的识别度确定过程。 {S(m1→s,)=0.655,S(→rs)=0.549H,这是n=1, 首先计算”1与s,的识别度。由系统介绍可 m=1。最终故障样本模式”1属于故障标准模式 知,r1的F={f=漏电f=断路},X(f)={x1,x2}, s,。同理可判断2和r3与R中各标准模式的归 X")={x,x2,x}。根据式(4)计算n→s)中 属,从而对样本模式进行识别。 的N.、N。和N。(X)、(X)、X)和(X) 总结上述过程的计算步骤如图3所示。 使用图进行表示,如图2所示。 确定研究背景和数据 ×109 建立故障模式识别系统,如式(1)所示 统计同异反各种状态的不同位置数 量来确定N、N和N。如式(3)所示 确定N,、N和N,即可确定式(2)中a、b和c 00 确定单一故障样本模式与某故障标 9 准模式的关系,计算联系度,如式(2)所示 % ● 确定单一故障样本模式与某敌障标准模式的识别度,如式(4)所示 湿度% 10 800 温度℃ 确定直接因素的权重 图2故障空间与故障分布 Fig.2 Fault space and fault distribution 最终确定该故障样本模式属于哪种故障标准模式,如式(⑤)所示 图2显示了X条件下r1与s,的故障数据统 图3算法实现的步骤 计情况。“+”为r1的故障分布特征;“O”为s,的 Fig.3 Steps of algorithm 故障分布特征。(X)表示所有“O”点的集合, 上述方法的特点:1)将因素分为直接因素和 %X)∈(X);(X)表示所有“+”点的集合, 背景因素,直接因素是引起系统故障的直接原 (X)EV(X)。当然实际的数据统计图并不是这 因,但这些直接原因可能受到多种更为基本的因 样的,因为实际过程中的数据有冗余和遗漏,造 素影响,因此将因素分层更为合理。2)模式识别 成两个分布的对应位置没有对应的可分析数据。 是通过联系度确定的,而联系度的系数则是通过 所以这里将各自数据进行曲面拟合,再进行网格 故障数据在故障空间中的分布统计确定的。因为 化的曲面绘制,从而满足分析要求。这两种分布 无论是实际数据还是实验数据都难以完全独立地 的曲面方程为 得到单因素对故障发生的影响。多因素的联合分 r(1,x)=x1+x2/8+V 布更为准确。3)利用三元联系数表示了故障发生 (6) r(x1,2)=x2+x2/2-21 的确定性和不确定性。 根据式(3)统计得N。=338、N。=142、N=16,代 上述研究是集对分析理论与空间故障树理论 入式(2)得到a=0.68、b=0.28、c=0.03、j=-1、 的结合,应用于系统故障模式识别。根据故障标 i=0.68-0.03=0.65,那么m1→s,)=0.68+ 准模式识别故障样本模式,从而分析故障原因, 0.28×0.65-0.03=0.832。 采取对应的故障标准模式预防和治理措施对故障 再计算(→rs,),由于X()={x1,x2,x},因 样本模式进行处理。X ′ X ′′ RS = {rS 1 ,rS 2 } R = {r1,r2,r3} (f1 )={x1 , x2}, (f2 )={x1 , x2 , x3};x1∈[0,30]℃,取样 间隔为 1 ℃;x2∈[80,95]%,取样间隔为 1%;x3∈ [1.05,1.35]MPa,取样间隔为 0.05 MPa; ,M=2,故障标准模式为 2 个 ; , N=3,故障样本模式为 3 个。由于这里主要论述 联系度及识别度的确定方法,而直接因素 F 导致 系统故障的权重 W 不是重点,因此只通过专家确 定简单的权重,W={w1=0.63,w2=0.37}。最终建立 故障模式识别系统 T,如下进行故障模式识别。 目的是得到 R 中样本模式与 RS 中标准模式的归 属关系。由于过程复杂,这里只详细给出 r1 与 RS 的识别度确定过程。 rS 1 X ′ X ′′ µ X ′ f1 (r1 → rS 1 ) V rS 1 f1 (X ′ ) v rS 1 f1 (X ′ ) V r1 f1 (X ′ ) v r1 f1 (X ′ ) 首先计算 r1 与 的识别度。由系统介绍可 知 ,r 1 的 F={f 1=漏电,f 2=断路}, (f 1 )={x 1 , x 2 }, (f2 )={x1 , x2 , x3}。根据式 (4) 计算 中 的 Na、Nb 和 Nc。 、 、 和 使用图进行表示,如图 2 所示。 0 10 20 30 80 85 90 95 0 2 4 6 8 10 12 ×105 故障次数/h 湿度/% 温度/℃ 图 2 故障空间与故障分布 Fig. 2 Fault space and fault distribution X ′ rS 1 rS 1 V rS 1 f1 (X ′ ) v rS 1 f1 (X ′ ) V rS 1 f1 (X ′ ) V r1 f1 (X ′ ) v r1 f1 (X ′ ) V r1 f1 (X ′ ) 图 2 显示了 条件下 r1 与 的故障数据统 计情况。“+”为 r1 的故障分布特征;“O”为 的 故障分布特征。 表示所有“O”点的集合, ∈ ; 表示所有“+”点的集合, ∈ 。当然实际的数据统计图并不是这 样的,因为实际过程中的数据有冗余和遗漏,造 成两个分布的对应位置没有对应的可分析数据。 所以这里将各自数据进行曲面拟合,再进行网格 化的曲面绘制,从而满足分析要求。这两种分布 的曲面方程为 { rs1 (x1 , x2) = x1 + x2/8+ √ x1 x2 r1(x1 , x2) = x1 2 + x2/2−21 (6) µ X ′ f1 (r1 → rS 1 ) 根据式 (3) 统计得 Na=338、Nb=142、Nc=16,代 入式 (2) 得到 a=0.68、b=0.28、c=0.03、j=−1、 i =0.68−0.03=0.65 ,那么 =0.68+ 0.28×0.65−0.03=0.832。 µ X ′′ f1 (r1 → rS 1 ) X 再计算 ′′ ,由于 (f2 )={x1 , x2 , x3},因 此分布需要四维图表示,这里从略。但给出故障 分布曲面方程,如式 (7) 所示。 { rs1 (x1 , x2 , x3) = x1/2+ x2 √ x1 x2 − x3 r1(x1 , x2 , x3) = x1 2 /8+ x2 2 /2+1.4 √ x3 (7) µ X ′′ f1 (r1 → rS 1 ) 根 据 式 (3) 进行统 计 Na=1 953、 Nb=609、 Nc=910,代入式 (2) 得到 a=0.56、b=0.18、c=0.26、 j=−1、i=0.56−0.26=0.3,那么 =0.56+ 0.18×0.3−0.26=0.354。 S X F (r1 → rS 1 ) = [0.63 0.37]T ×[0.832 0.354] = 0.655 S X F (r1 → rS 2 ) = 0.549 [1,m] = {(1,m)|MAX {S X F (r1 → rS 1 ) = 0.655,S X F (r1 → rS 2 ) = 0.549}} rS 1 RS 根 据 式 (4) , 。同理可以得到 。 那么继续根据 式 ( 5 ) 可得, ,这是 n=1, m=1。最终故障样本模式 r1 属于故障标准模式 。同理可判断 r2 和 r3 与 中各标准模式的归 属,从而对样本模式进行识别。 总结上述过程的计算步骤如图 3 所示。 确定研究背景和数据 建立故障模式识别系统, 如式 (1) 所示 统计同异反各种状态的不同位置数 量来确定 Na、 Nb 和 Nc , 如式 (3) 所示 确定单一故障样本模式与某故障标 准模式的关系, 计算联系度, 如式 (2) 所示 确定单一故障样本模式与某故障标准模式的识别度, 如式 (4) 所示 确定 Na、 Nb 和 Nc , 即可确定式 (2) 中 a、b 和 c 确定直接因素的权重 最终确定该故障样本模式属于哪种故障标准模式, 如式 (5) 所示 图 3 算法实现的步骤 Fig. 3 Steps of algorithm 上述方法的特点:1) 将因素分为直接因素和 背景因素,直接因素是引起系统故障的直接原 因,但这些直接原因可能受到多种更为基本的因 素影响,因此将因素分层更为合理。2) 模式识别 是通过联系度确定的,而联系度的系数则是通过 故障数据在故障空间中的分布统计确定的。因为 无论是实际数据还是实验数据都难以完全独立地 得到单因素对故障发生的影响。多因素的联合分 布更为准确。3) 利用三元联系数表示了故障发生 的确定性和不确定性。 上述研究是集对分析理论与空间故障树理论 的结合,应用于系统故障模式识别。根据故障标 准模式识别故障样本模式,从而分析故障原因, 采取对应的故障标准模式预防和治理措施对故障 样本模式进行处理。 ·390· 智 能 系 统 学 报 第 17 卷