正在加载图片...
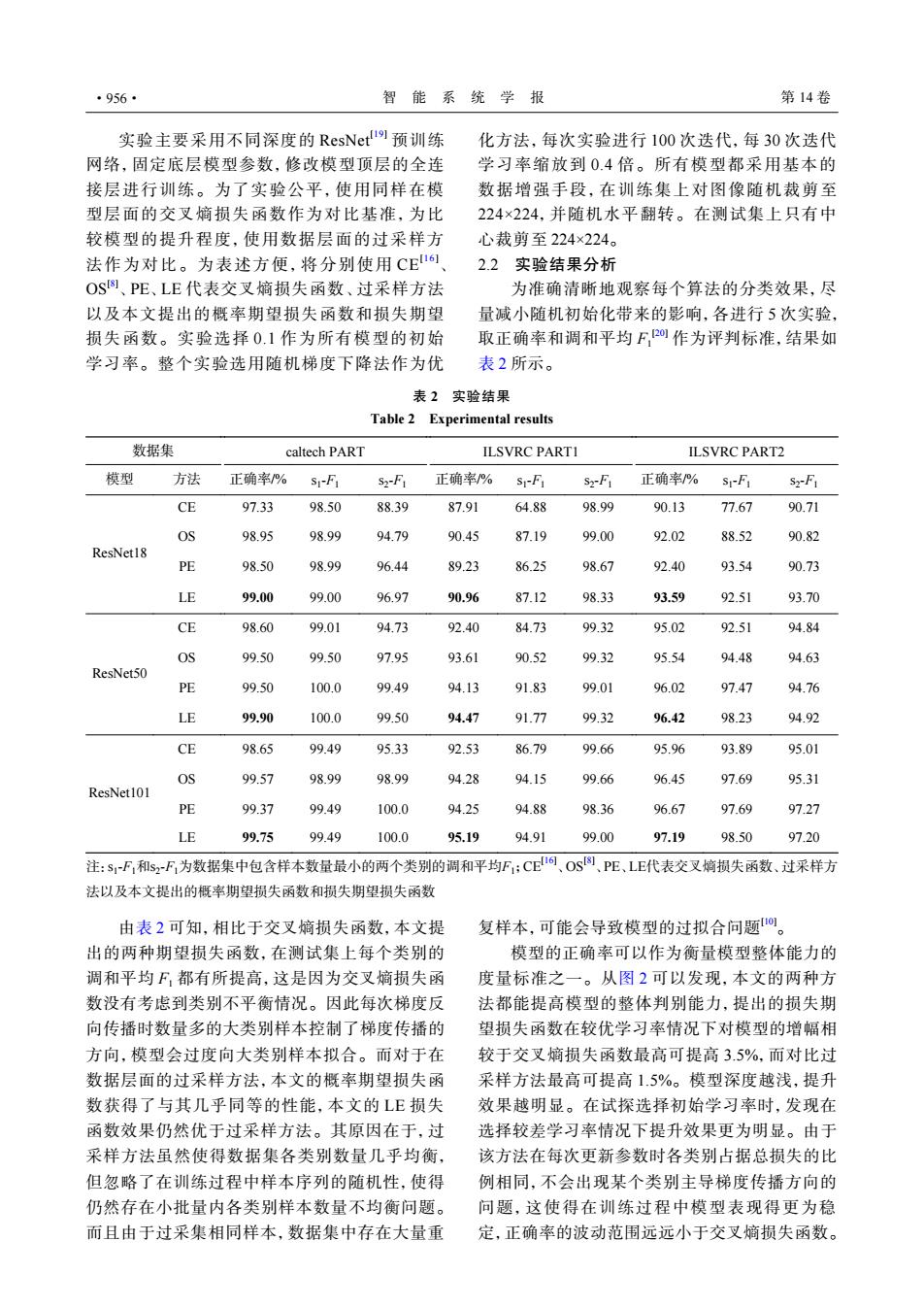
·956· 智能系统学报 第14卷 实验主要采用不同深度的ResNet!,预训练 化方法,每次实验进行100次迭代,每30次迭代 网络,固定底层模型参数,修改模型顶层的全连 学习率缩放到0.4倍。所有模型都采用基本的 接层进行训练。为了实验公平,使用同样在模 数据增强手段,在训练集上对图像随机裁剪至 型层面的交叉嫡损失函数作为对比基准,为比 224×224,并随机水平翻转。在测试集上只有中 较模型的提升程度,使用数据层面的过采样方 心裁剪至224×224。 法作为对比。为表述方便,将分别使用CE161 2.2实验结果分析 OS图、PE、LE代表交叉嫡损失函数、过采样方法 为准确清晰地观察每个算法的分类效果,尽 以及本文提出的概率期望损失函数和损失期望 量减小随机初始化带来的影响,各进行5次实验, 损失函数。实验选择0.1作为所有模型的初始 取正确率和调和平均F2作为评判标准,结果如 学习率。整个实验选用随机梯度下降法作为优 表2所示。 表2实验结果 Table 2 Experimental results 数据集 caltech PART ILSVRC PARTI ILSVRC PART2 模型 方法 正确率% SI-F1 S2-F1 正确率% S-F1 s2-F1 正确率/% sI-FI S-F1 CE 97.33 98.50 88.39 87.91 64.88 98.99 90.13 77.67 90.71 OS 98.95 98.99 94.79 90.45 87.19 99.00 92.02 88.52 90.82 ResNet18 PE 98.50 98.99 96.44 89.23 86.25 98.67 92.40 93.54 90.73 LE 99.00 99.00 96.97 90.96 87.12 98.33 93.59 92.51 93.70 CE 98.60 99.01 94.73 92.40 84.73 99.32 95.02 92.51 94.84 OS 99.50 99.50 97.95 93.61 90.52 99.32 95.54 94.48 94.63 ResNet50 PE 99.50 100.0 99.49 94.13 91.83 99.01 96.02 97.47 94.76 LE 99.90 100.0 99.50 94.47 91.77 99.32 96.42 98.23 94.92 CE 98.65 99.49 95.33 92.53 86.79 99.66 95.96 93.89 95.01 OS 99.57 98.99 98.99 94.28 94.15 99.66 96.45 97.69 95.31 ResNet101 PE 99.37 99.49 100.0 94.25 94.88 98.36 96.67 97.69 97.27 LE 99.75 99.49 100.0 95.19 94.91 99.00 97.19 98.50 97.20 注:s-F和s2F,为数据集中包含样本数量最小的两个类别的调和平均F:CE16、Os⑧、PE、LE代表交叉嫡损失函数、过采样方 法以及本文提出的概率期望损失函数和损失期望损失函数 由表2可知,相比于交叉嫡损失函数,本文提 复样本,可能会导致模型的过拟合问题。 出的两种期望损失函数,在测试集上每个类别的 模型的正确率可以作为衡量模型整体能力的 调和平均F,都有所提高,这是因为交叉嫡损失函 度量标准之一。从图2可以发现,本文的两种方 数没有考虑到类别不平衡情况。因此每次梯度反 法都能提高模型的整体判别能力,提出的损失期 向传播时数量多的大类别样本控制了梯度传播的 望损失函数在较优学习率情况下对模型的增幅相 方向,模型会过度向大类别样本拟合。而对于在 较于交叉嫡损失函数最高可提高3.5%,而对比过 数据层面的过采样方法,本文的概率期望损失函 采样方法最高可提高1.5%。模型深度越浅,提升 数获得了与其几乎同等的性能,本文的LE损失 效果越明显。在试探选择初始学习率时,发现在 函数效果仍然优于过采样方法。其原因在于,过 选择较差学习率情况下提升效果更为明显。由于 采样方法虽然使得数据集各类别数量几乎均衡, 该方法在每次更新参数时各类别占据总损失的比 但忽略了在训练过程中样本序列的随机性,使得 例相同,不会出现某个类别主导梯度传播方向的 仍然存在小批量内各类别样本数量不均衡问题。 问题,这使得在训练过程中模型表现得更为稳 而且由于过采集相同样本,数据集中存在大量重 定,正确率的波动范围远远小于交叉熵损失函数。实验主要采用不同深度的 ResNet[19] 预训练 网络,固定底层模型参数,修改模型顶层的全连 接层进行训练。为了实验公平,使用同样在模 型层面的交叉熵损失函数作为对比基准,为比 较模型的提升程度,使用数据层面的过采样方 法作为对比。为表述方便,将分别使用 CE[16] 、 OS[8] 、PE、LE 代表交叉熵损失函数、过采样方法 以及本文提出的概率期望损失函数和损失期望 损失函数。实验选择 0.1 作为所有模型的初始 学习率。整个实验选用随机梯度下降法作为优 化方法,每次实验进行 100 次迭代,每 30 次迭代 学习率缩放到 0.4 倍。所有模型都采用基本的 数据增强手段,在训练集上对图像随机裁剪至 224×224,并随机水平翻转。在测试集上只有中 心裁剪至 224×224。 2.2 实验结果分析 为准确清晰地观察每个算法的分类效果,尽 量减小随机初始化带来的影响,各进行 5 次实验, 取正确率和调和平均 F1 [20] 作为评判标准,结果如 表 2 所示。 表 2 实验结果 Table 2 Experimental results 数据集 caltech PART ILSVRC PART1 ILSVRC PART2 模型 方法 正确率/% s1 -F1 s2 -F1 正确率/% s1 -F1 s2 -F1 正确率/% s1 -F1 s2 -F1 ResNet18 CE 97.33 98.50 88.39 87.91 64.88 98.99 90.13 77.67 90.71 OS 98.95 98.99 94.79 90.45 87.19 99.00 92.02 88.52 90.82 PE 98.50 98.99 96.44 89.23 86.25 98.67 92.40 93.54 90.73 LE 99.00 99.00 96.97 90.96 87.12 98.33 93.59 92.51 93.70 ResNet50 CE 98.60 99.01 94.73 92.40 84.73 99.32 95.02 92.51 94.84 OS 99.50 99.50 97.95 93.61 90.52 99.32 95.54 94.48 94.63 PE 99.50 100.0 99.49 94.13 91.83 99.01 96.02 97.47 94.76 LE 99.90 100.0 99.50 94.47 91.77 99.32 96.42 98.23 94.92 ResNet101 CE 98.65 99.49 95.33 92.53 86.79 99.66 95.96 93.89 95.01 OS 99.57 98.99 98.99 94.28 94.15 99.66 96.45 97.69 95.31 PE 99.37 99.49 100.0 94.25 94.88 98.36 96.67 97.69 97.27 LE 99.75 99.49 100.0 95.19 94.91 99.00 97.19 98.50 97.20 注:s1 -F1和s2 -F1为数据集中包含样本数量最小的两个类别的调和平均F1;CE[16] 、OS[8] 、PE、LE代表交叉熵损失函数、过采样方 法以及本文提出的概率期望损失函数和损失期望损失函数 由表 2 可知,相比于交叉熵损失函数,本文提 出的两种期望损失函数,在测试集上每个类别的 调和平均 F1 都有所提高,这是因为交叉熵损失函 数没有考虑到类别不平衡情况。因此每次梯度反 向传播时数量多的大类别样本控制了梯度传播的 方向,模型会过度向大类别样本拟合。而对于在 数据层面的过采样方法,本文的概率期望损失函 数获得了与其几乎同等的性能,本文的 LE 损失 函数效果仍然优于过采样方法。其原因在于,过 采样方法虽然使得数据集各类别数量几乎均衡, 但忽略了在训练过程中样本序列的随机性,使得 仍然存在小批量内各类别样本数量不均衡问题。 而且由于过采集相同样本,数据集中存在大量重 复样本,可能会导致模型的过拟合问题[10]。 模型的正确率可以作为衡量模型整体能力的 度量标准之一。从图 2 可以发现,本文的两种方 法都能提高模型的整体判别能力,提出的损失期 望损失函数在较优学习率情况下对模型的增幅相 较于交叉熵损失函数最高可提高 3.5%,而对比过 采样方法最高可提高 1.5%。模型深度越浅,提升 效果越明显。在试探选择初始学习率时,发现在 选择较差学习率情况下提升效果更为明显。由于 该方法在每次更新参数时各类别占据总损失的比 例相同,不会出现某个类别主导梯度传播方向的 问题,这使得在训练过程中模型表现得更为稳 定,正确率的波动范围远远小于交叉熵损失函数。 ·956· 智 能 系 统 学 报 第 14 卷