正在加载图片...
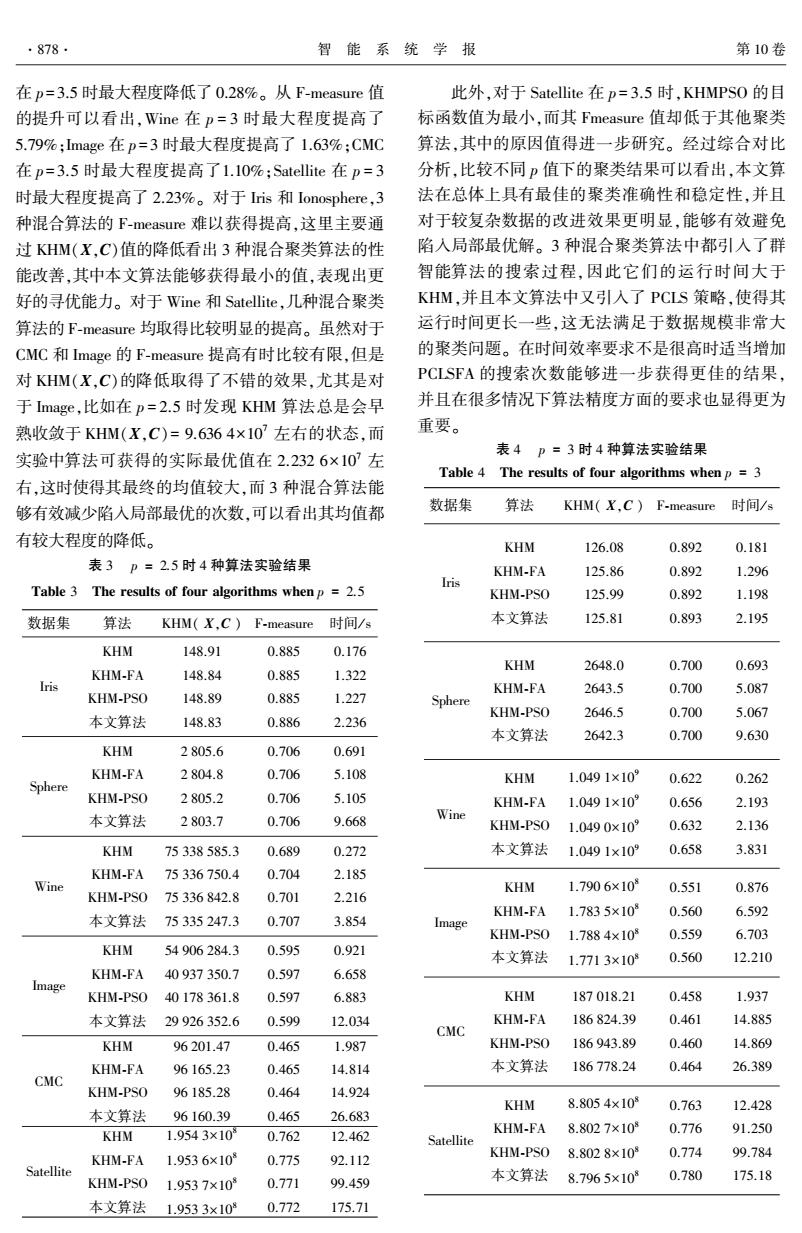
·878 智能系统学报 第10卷 在p=3.5时最大程度降低了0.28%。从F-measure值 此外,对于Satellite在p=3.5时,KHMPS0的目 的提升可以看出,Wine在p=3时最大程度提高了 标函数值为最小,而其Fmeasure值却低于其他聚类 5.79%;mage在p=3时最大程度提高了1.63%:CMC 算法,其中的原因值得进一步研究。经过综合对比 在p=3.5时最大程度提高了1.10%;Satellite在p=3 分析,比较不同p值下的聚类结果可以看出,本文算 时最大程度提高了2.23%。对于Iis和lonosphere,3 法在总体上具有最佳的聚类准确性和稳定性,并且 种混合算法的F-measure难以获得提高,这里主要通 对于较复杂数据的改进效果更明显,能够有效避免 过KHM(X,C)值的降低看出3种混合聚类算法的性 陷入局部最优解。3种混合聚类算法中都引入了群 能改善,其中本文算法能够获得最小的值,表现出更 智能算法的搜索过程,因此它们的运行时间大于 好的寻优能力。对于Wine和Satellite,几种混合聚类 KHM,并且本文算法中又引入了PCLS策略,使得其 算法的F-measure均取得比较明显的提高。虽然对于 运行时间更长一些,这无法满足于数据规模非常大 CMC和Image的F-measure提高有时比较有限,但是 的聚类问题。在时间效率要求不是很高时适当增加 对KHM(X,C)的降低取得了不错的效果,尤其是对 PCLSFA的搜索次数能够进一步获得更佳的结果, 于Image,比如在p=2.5时发现KHM算法总是会早 并且在很多情况下算法精度方面的要求也显得更为 熟收敛于KHM(X,C)=9.6364×10'左右的状态,而 重要。 表4p=3时4种算法实验结果 实验中算法可获得的实际最优值在2.2326×10'左 Table 4 The results of four algorithms when p=3 右,这时使得其最终的均值较大,而3种混合算法能 够有效减少陷入局部最优的次数,可以看出其均值都 数据集 算法 KHM(X.C) F-measure 时间/s 有较大程度的降低。 KHM 126.08 0.892 0.181 表3p=2.5时4种算法实验结果 KHM-FA 125.86 0.892 1.296 Iris Table 3 The results of four algorithms when p 2.5 KHM-PSO 125.99 0.892 1.198 数据集 算法 KHM(X,C F-measure 时间/s 本文算法 125.81 0.893 2.195 KHM 148.91 0.885 0.176 KHM 2648.0 0.700 0.693 KHM-FA 148.84 0.885 1.322 KHM-FA 2643.5 0.700 5.087 KHM-PSO 148.89 0.885 1.227 Sphere KHM-PSO 2646.5 0.700 5.067 本文算法 148.83 0.886 2.236 本文算法 2642.3 0.700 9.630 KHM 2805.6 0.706 0.691 KHM-FA 2804.8 0.706 5.108 KHM 1.0491×10 0.622 0.262 Sphere KHM-PSO 2805.2 0.706 5.105 KHM-FA 1.0491×10 0.656 2.193 本文算法 2803.7 0.706 9.668 Wine KHM-PSO 1.0490×109 0.632 2.136 KHM 75338585.3 0.689 0.272 本文算法 1.0491×109 0.658 3.831 KHM-FA 75336750.4 0.704 2.185 Wine KHM 1.7906×10 0.551 0.876 KHM-PSO 75336842.8 0.701 2.216 KHM-FA 1.7835×10 0.560 6.592 本文算法 75335247.3 0.707 3.854 Image KHM-PSO 1.7884×108 0.559 6.703 KHM 54906284.3 0.595 0.921 本文算法 1.7713×108 0.560 12.210 KHM-FA 40937350.7 0.597 6.658 Image KHM-PSO 40178361.8 0.597 6.883 KHM 187018.21 0.458 1.937 本文算法29926352.6 0.599 12.034 KHM-FA 186824.39 0.461 14.885 CMC KHM 96201.47 0.465 1.987 KHM-PSO 186943.89 0.460 14.869 KHM-FA 96165.23 0.465 14.814 本文算法 186778.24 0.464 26.389 CMC KHM-PSO 96185.28 0.464 14.924 KHM 8.8054×103 0.763 12.428 本文算法 96160.39 0.465 26.683 KHM-FA 8.8027×108 KHM 1.9543×10i 0.762 12.462 0.776 91.250 Satellite 1.9536×10 KHM-PSO 8.8028×109 0.774 99.784 KHM-FA 0.775 92.112 Satellite 本文算法 8.7965×108 0.780 175.18 KHM-PSO 1.9537×10 0.771 99.459 本文算法1.9533×108 0.772 175.71在 p = 3.5 时最大程度降低了 0.28%。 从 F⁃measure 值 的提升可以看出,Wine 在 p = 3 时最大程度提高了 5.79%;Image 在 p = 3 时最大程度提高了 1.63%;CMC 在 p = 3.5 时最大程度提高了1.10%;Satellite 在 p = 3 时最大程度提高了 2.23%。 对于 Iris 和 Ionosphere,3 种混合算法的 F⁃measure 难以获得提高,这里主要通 过 KHM(X,C)值的降低看出 3 种混合聚类算法的性 能改善,其中本文算法能够获得最小的值,表现出更 好的寻优能力。 对于 Wine 和 Satellite,几种混合聚类 算法的 F⁃measure 均取得比较明显的提高。 虽然对于 CMC 和 Image 的 F⁃measure 提高有时比较有限,但是 对 KHM(X,C)的降低取得了不错的效果,尤其是对 于 Image,比如在 p = 2.5 时发现 KHM 算法总是会早 熟收敛于 KHM(X,C)= 9.636 4×10 7 左右的状态,而 实验中算法可获得的实际最优值在 2.232 6×10 7 左 右,这时使得其最终的均值较大,而 3 种混合算法能 够有效减少陷入局部最优的次数,可以看出其均值都 有较大程度的降低。 表 3 p = 2.5 时 4 种算法实验结果 Table 3 The results of four algorithms when p = 2.5 数据集 算法 KHM( X,C ) F⁃measure 时间/ s Iris KHM KHM⁃FA KHM⁃PSO 本文算法 148.91 148.84 148.89 148.83 0.885 0.885 0.885 0.886 0.176 1.322 1.227 2.236 Sphere KHM KHM⁃FA KHM⁃PSO 本文算法 2 805.6 2 804.8 2 805.2 2 803.7 0.706 0.706 0.706 0.706 0.691 5.108 5.105 9.668 Wine KHM KHM⁃FA KHM⁃PSO 本文算法 75 338 585.3 75 336 750.4 75 336 842.8 75 335 247.3 0.689 0.704 0.701 0.707 0.272 2.185 2.216 3.854 Image KHM KHM⁃FA KHM⁃PSO 本文算法 54 906 284.3 40 937 350.7 40 178 361.8 29 926 352.6 0.595 0.597 0.597 0.599 0.921 6.658 6.883 12.034 CMC KHM KHM⁃FA KHM⁃PSO 本文算法 96 201.47 96 165.23 96 185.28 96 160.39 0.465 0.465 0.464 0.465 1.987 14.814 14.924 26.683 Satellite KHM KHM⁃FA KHM⁃PSO 本文算法 1.954 3×10 8 1.953 6×10 8 1.953 7×10 8 1.953 3×10 8 0.762 0.775 0.771 0.772 12.462 92.112 99.459 175.71 此外,对于 Satellite 在 p = 3.5 时,KHMPSO 的目 标函数值为最小,而其 Fmeasure 值却低于其他聚类 算法,其中的原因值得进一步研究。 经过综合对比 分析,比较不同 p 值下的聚类结果可以看出,本文算 法在总体上具有最佳的聚类准确性和稳定性,并且 对于较复杂数据的改进效果更明显,能够有效避免 陷入局部最优解。 3 种混合聚类算法中都引入了群 智能算法的搜索过程,因此它们的运行时间大于 KHM,并且本文算法中又引入了 PCLS 策略,使得其 运行时间更长一些,这无法满足于数据规模非常大 的聚类问题。 在时间效率要求不是很高时适当增加 PCLSFA 的搜索次数能够进一步获得更佳的结果, 并且在很多情况下算法精度方面的要求也显得更为 重要。 表 4 p = 3 时 4 种算法实验结果 Table 4 The results of four algorithms when p = 3 数据集 算法 KHM( X,C ) F⁃measure 时间/ s Iris KHM KHM⁃FA KHM⁃PSO 本文算法 126.08 125.86 125.99 125.81 0.892 0.892 0.892 0.893 0.181 1.296 1.198 2.195 Sphere KHM KHM⁃FA KHM⁃PSO 本文算法 2648.0 2643.5 2646.5 2642.3 0.700 0.700 0.700 0.700 0.693 5.087 5.067 9.630 Wine KHM KHM⁃FA KHM⁃PSO 本文算法 1.049 1×10 9 1.049 1×10 9 1.049 0×10 9 1.049 1×10 9 0.622 0.656 0.632 0.658 0.262 2.193 2.136 3.831 Image KHM KHM⁃FA KHM⁃PSO 本文算法 1.790 6×10 8 1.783 5×10 8 1.788 4×10 8 1.771 3×10 8 0.551 0.560 0.559 0.560 0.876 6.592 6.703 12.210 CMC KHM KHM⁃FA KHM⁃PSO 本文算法 187 018.21 186 824.39 186 943.89 186 778.24 0.458 0.461 0.460 0.464 1.937 14.885 14.869 26.389 Satellite KHM KHM⁃FA KHM⁃PSO 本文算法 8.805 4×10 8 8.802 7×10 8 8.802 8×10 8 8.796 5×10 8 0.763 0.776 0.774 0.780 12.428 91.250 99.784 175.18 ·878· 智 能 系 统 学 报 第 10 卷