正在加载图片...
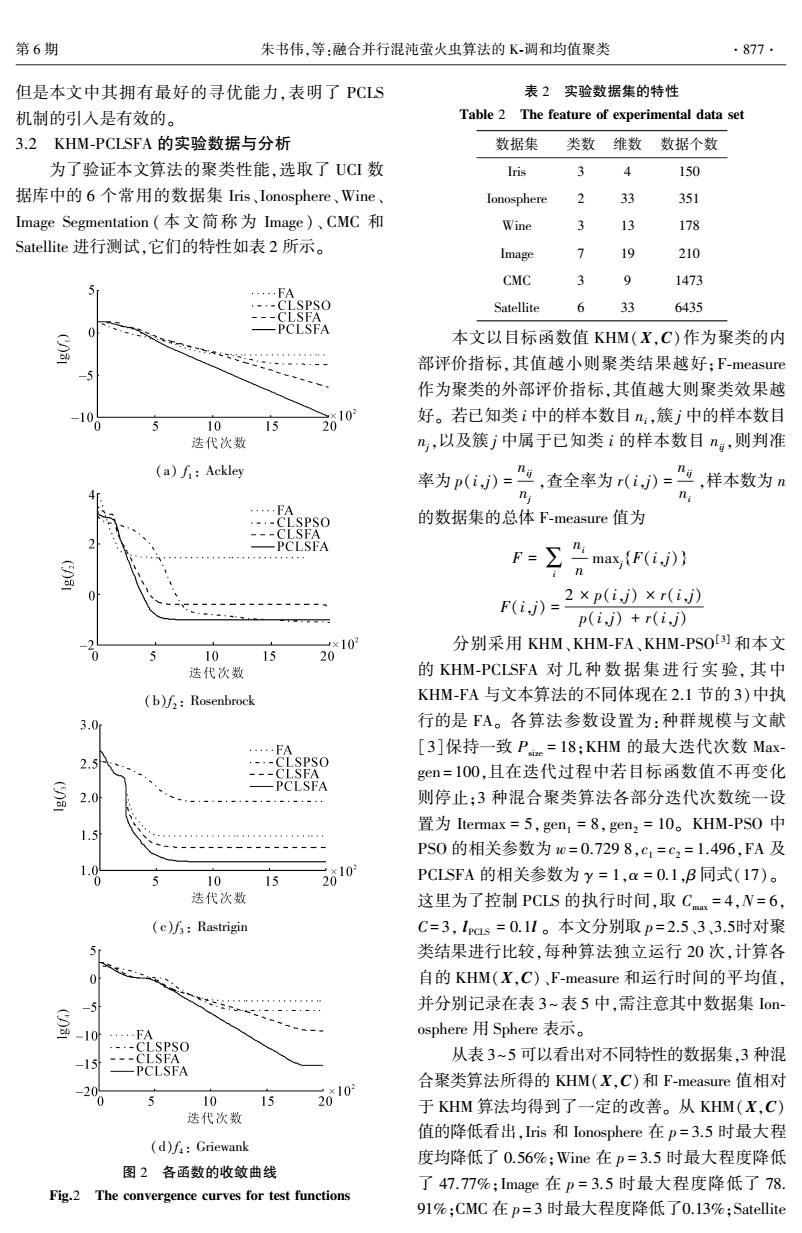
第6期 朱书伟,等:融合并行混沌莹火虫算法的K-调和均值聚类 ·877- 但是本文中其拥有最好的寻优能力,表明了PCLS 表2实验数据集的特性 机制的引入是有效的。 Table 2 The feature of experimental data set 3.2KHM-PCLSFA的实验数据与分析 数据集 类数 维数数据个数 为了验证本文算法的聚类性能,选取了UCI数 Iris 3 150 据库中的6个常用的数据集ris、Ionosphere、Wine Ionosphere 2 33 351 Image Segmentation(本文简称为Image)、CMC和 Wine 3 13 178 Satellite进行测试,它们的特性如表2所示。 Image 个 19 210 CMC 3 9 1473 LSPSO Satellite 6 33 6435 本文以目标函数值KHM(X,C)作为聚类的内 部评价指标,其值越小则聚类结果越好:F-measure 作为聚类的外部评价指标,其值越大则聚类效果越 10 好。若已知类i中的样本数目n:,簇中的样本数目 10 20 迭代次数 m,以及簇j中属于已知类i的样本数目n,则判准 (a)f:Ackley 率为p(i》=”,查全率为r(i》=,样本数为n 4 n n ,·,,FA SPSO 的数据集的总体F-measure值为 2 -PCLSFA F=∑ma,{F(i,} n 0 F(ij)= 2×p(i,j)×r(i,j) p(i,j)+r(i,j) 10 分别采用KHM、KHM-FA、KHM-PSO)和本文 10 15 20 迭代次数 的KHM-PCLSFA对几种数据集进行实验,其中 (b)f:Rosenbrock KHM-FA与文本算法的不同体现在2.1节的3)中执 3.0 行的是FA。各算法参数设置为:种群规模与文献 …FA [3]保持一致Pc=18;KHM的最大迭代次数Max 2.5 ·-.-CLSPSO gen=100,且在迭代过程中若目标函数值不再变化 -PCLSFA 则停止:3种混合聚类算法各部分迭代次数统一设 置为Itermax=5,gen1=8,gen2=10。KHM-PS0中 1.5 PS0的相关参数为0=0.7298,c1=c2=1.496,FA及 1.0 10 15 2010 PCLSFA的相关参数为y=1,a=0.1,B同式(17)。 迭代次数 这里为了控制PCLS的执行时间,取Cm=4,N=6, (c)f3:Rastrigin C=3,lcs=0.1l。本文分别取p=2.5、3、3.5时对聚 类结果进行比较,每种算法独立运行20次,计算各 自的KHM(X,C)、F-measure和运行时间的平均值, 并分别记录在表3~表5中,需注意其中数据集Ion -10 ·-FA osphere用Sphere表示。 .-·-CLSPSO ---CLSFA 从表3~5可以看出对不同特性的数据集,3种混 -15 —PCLSFA 合聚类算法所得的KHM(X,C)和F-measure值相对 -20 10 15 2010 于KHM算法均得到了一定的改善。从KHM(X,C) 送代次数 值的降低看出,Iis和Ionosphere在p=3.5时最大程 (d)f:Griewank 度均降低了0.56%;Wine在p=3.5时最大程度降低 图2各函数的收敛曲线 了47.77%;Image在p=3.5时最大程度降低了78. Fig.2 The convergence curves for test functions 91%;CMC在p=3时最大程度降低了0.13%:Satellite但是本文中其拥有最好的寻优能力,表明了 PCLS 机制的引入是有效的。 3.2 KHM⁃PCLSFA 的实验数据与分析 为了验证本文算法的聚类性能,选取了 UCI 数 据库中的 6 个常用的数据集 Iris、Ionosphere、Wine、 Image Segmentation ( 本文简称 为 Image)、 CMC 和 Satellite 进行测试,它们的特性如表 2 所示。 (a) f 1 : Ackley (b)f 2 : Rosenbrock (c)f 3 : Rastrigin (d)f 4 : Griewank 图 2 各函数的收敛曲线 Fig.2 The convergence curves for test functions 表 2 实验数据集的特性 Table 2 The feature of experimental data set 数据集 类数 维数 数据个数 Iris 3 4 150 Ionosphere 2 33 351 Wine 3 13 178 Image 7 19 210 CMC 3 9 1473 Satellite 6 33 6435 本文以目标函数值 KHM(X,C)作为聚类的内 部评价指标,其值越小则聚类结果越好;F⁃measure 作为聚类的外部评价指标,其值越大则聚类效果越 好。 若已知类 i 中的样本数目 ni,簇 j 中的样本数目 nj,以及簇 j 中属于已知类 i 的样本数目 nij,则判准 率为 p(i,j) = nij nj ,查全率为 r(i,j) = nij ni ,样本数为 n 的数据集的总体 F⁃measure 值为 F = ∑i ni n maxj {F(i,j)} F(i,j) = 2 × p(i,j) × r(i,j) p(i,j) + r(i,j) 分别采用 KHM、KHM⁃FA、KHM⁃PSO [3] 和本文 的 KHM⁃PCLSFA 对 几 种 数 据 集 进 行 实 验, 其 中 KHM⁃FA 与文本算法的不同体现在 2.1 节的 3)中执 行的是 FA。 各算法参数设置为:种群规模与文献 [3]保持一致 Psize = 18;KHM 的最大迭代次数 Max⁃ gen = 100,且在迭代过程中若目标函数值不再变化 则停止;3 种混合聚类算法各部分迭代次数统一设 置为 Itermax = 5, gen1 = 8, gen2 = 10。 KHM⁃PSO 中 PSO 的相关参数为 w = 0.729 8,c1 = c2 = 1.496,FA 及 PCLSFA 的相关参数为 γ = 1,α = 0.1,β 同式(17)。 这里为了控制 PCLS 的执行时间,取 Cmax = 4,N = 6, C= 3, lPCLS = 0.1l 。 本文分别取 p = 2.5、3、3.5时对聚 类结果进行比较,每种算法独立运行 20 次,计算各 自的 KHM(X,C)、F⁃measure 和运行时间的平均值, 并分别记录在表 3~表 5 中,需注意其中数据集 Ion⁃ osphere 用 Sphere 表示。 从表 3~5 可以看出对不同特性的数据集,3 种混 合聚类算法所得的 KHM(X,C)和 F⁃measure 值相对 于 KHM 算法均得到了一定的改善。 从 KHM(X,C) 值的降低看出,Iris 和 Ionosphere 在 p = 3.5 时最大程 度均降低了 0.56%;Wine 在 p = 3.5 时最大程度降低 了 47.77%;Image 在 p = 3.5 时最大程度降低了 78. 91%;CMC 在 p = 3 时最大程度降低了0.13%;Satellite 第 6 期 朱书伟,等:融合并行混沌萤火虫算法的 K⁃调和均值聚类 ·877·