正在加载图片...
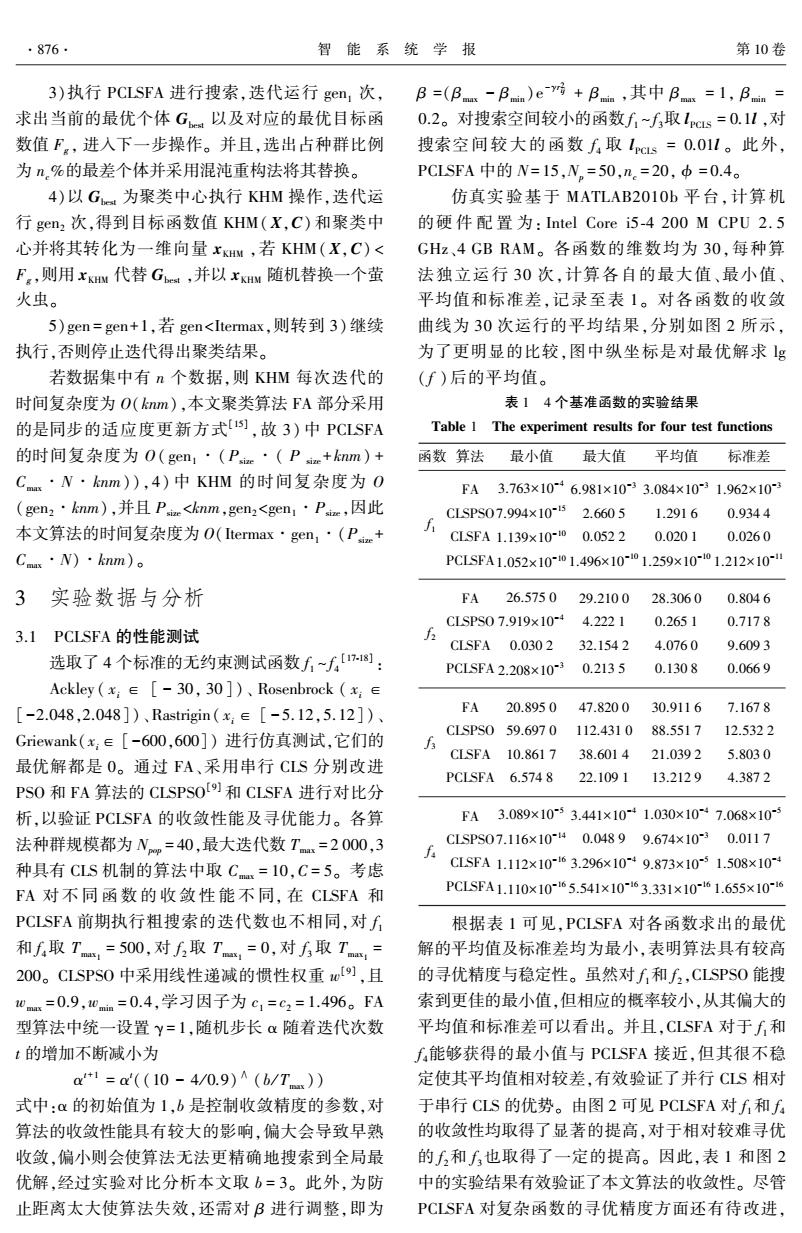
·876. 智能系统学报 第10卷 3)执行PCLSFA进行搜索,迭代运行gen,次,B=(B-B)er房+B,其中B=1,Ba= 求出当前的最优个体G以及对应的最优目标函 0.2。对搜索空间较小的函数f1~f取1cs=0.1l,对 数值F,进入下一步操作。并且,选出占种群比例 搜索空间较大的函数f取1cs=0.01l。此外, 为%的最差个体并采用混沌重构法将其替换。 PCLSFA中的N=15,N。=50,n.=20,中=0.4。 4)以G为聚类中心执行KHM操作,迭代运 仿真实验基于MATLAB201Ob平台,计算机 行gen2次,得到目标函数值KHM(X,C)和聚类中 的硬件配置为:Intel Core i5-4200MCPU2.5 心并将其转化为一维向量xKHM,若KHM(X,C)< GHz、4 GB RAM。各函数的维数均为30,每种算 F,则用xKM代替G,并以xKHM随机替换一个萤 法独立运行30次,计算各自的最大值、最小值、 火虫。 平均值和标准差,记录至表1。对各函数的收敛 5)gen=gen+1,若gen<Itermax,则转到3)继续 曲线为30次运行的平均结果,分别如图2所示, 执行,否则停止迭代得出聚类结果。 为了更明显的比较,图中纵坐标是对最优解求g 若数据集中有n个数据,则KHM每次迭代的 (f)后的平均值。 时间复杂度为O(knm),本文聚类算法FA部分采用 表14个基准函数的实验结果 的是同步的适应度更新方式,故3)中PCLSFA Table 1 The experiment results for four test functions 的时间复杂度为O(gen,·(Pic·(Pr+knm)+ 函数算法 最小值 最大值 平均值 标准差 Cms·N·knm),4)中KHM的时间复杂度为O FA3.763×1046.981×10-33.084×1031.962×10 (gen2·knm),并且Pe<khnm,gen,<gen1·Pc,因此 CLSPS07.994×1052.6605 1.2916 0.9344 本文算法的时间复杂度为O(Itermax·gen,·(Pc+ CLSFA1.139x10i00.0522 0.0201 0.0260 Cmax·N)·knm)。 PCLSFA1.052×10-01.496×10-01.259×10~01.212×101 3 实验数据与分析 FA 26.575029.2100 28.3060 0.8046 CLSPS07.919×10-4 4.2221 0.2651 0.7178 3.1 PCLSFA的性能测试 CLSEA 0.0302 32.1542 4.0760 9.6093 选取了4个标准的无约束测试函数f~f): PCLSFA2.208×10-3 0.2135 0.1308 0.0669 Ackley(x:∈[-30,30])、Rosenbrock(x∈ [-2.048,2.048])、Rastrigin(x:∈[-5.12,5.12])、 FA 20.8950 47.8200 30.9116 7.1678 CLSPS059.6970112.431088.5517 12.5322 Griewank(x:∈[-600,600])进行仿真测试,它们的 f CLSFA 10.8617 38.6014 21.0392 5.8030 最优解都是O。通过FA、采用串行CLS分别改进 PCLSFA 6.574 8 22.109113.21294.3872 PS0和FA算法的CLSPSOUS)和CLSFA进行对比分 析,以验证PCLSFA的收敛性能及寻优能力。各算 FA 3.089×1053.441×10+1.030×107.068×10-3 法种群规模都为Nm=40,最大迭代数T=2000,3 CLSPS07.116×1040.04899.674×10-30.0117 种具有CLS机制的算法中取Cmm=10,C=5。考虑 斤C5FA1.112x10-3.296×10-9.873x10-51.508×10 FA对不同函数的收敛性能不同,在CLSFA和 PCLSFA1.110×10165.541×10~63.331×1061.655×10-6 PCLSFA前期执行粗搜索的迭代数也不相同,对f 根据表1可见,PCLSFA对各函数求出的最优 和f取T,=500,对6取T,=0,对取T,= 解的平均值及标准差均为最小,表明算法具有较高 200。CLSPS0中采用线性递减的惯性权重w),且 的寻优精度与稳定性。虽然对f和f,CLSPS0能搜 wmm=0.9,0mi=0.4,学习因子为c1=c2=1.496。FA 索到更佳的最小值,但相应的概率较小,从其偏大的 型算法中统一设置y=1,随机步长α随着迭代次数 平均值和标准差可以看出。并且,CLSFA对于f和 t的增加不断减小为 f,能够获得的最小值与PCLSFA接近,但其很不稳 a+1=a((10-4/0.9)A(b/T)) 定使其平均值相对较差,有效验证了并行CLS相对 式中:a的初始值为1,b是控制收敛精度的参数,对 于串行CLS的优势。由图2可见PCLSFA对f和f 算法的收敛性能具有较大的影响,偏大会导致早熟 的收敛性均取得了显著的提高,对于相对较难寻优 收敛,偏小则会使算法无法更精确地搜索到全局最 的f2和f也取得了一定的提高。因此,表1和图2 优解,经过实验对比分析本文取b=3。此外,为防 中的实验结果有效验证了本文算法的收敛性。尽管 止距离太大使算法失效,还需对B进行调整,即为 PCLSFA对复杂函数的寻优精度方面还有待改进3)执行 PCLSFA 进行搜索,迭代运行 gen1 次, 求出当前的最优个体 Gbest 以及对应的最优目标函 数值 Fg , 进入下一步操作。 并且,选出占种群比例 为 nc%的最差个体并采用混沌重构法将其替换。 4)以 Gbest 为聚类中心执行 KHM 操作,迭代运 行 gen2 次,得到目标函数值 KHM(X,C) 和聚类中 心并将其转化为一维向量 xKHM ,若 KHM(X,C) < Fg ,则用 xKHM 代替 Gbest ,并以 xKHM 随机替换一个萤 火虫。 5)gen = gen+1,若 gen<Itermax,则转到 3)继续 执行,否则停止迭代得出聚类结果。 若数据集中有 n 个数据,则 KHM 每次迭代的 时间复杂度为 O(knm),本文聚类算法 FA 部分采用 的是同步的适应度更新方式[15] ,故 3) 中 PCLSFA 的时间复杂度为 O( gen1 ∙(Psize ∙( P size +knm) + Cmax∙N∙knm)),4) 中 KHM 的时间复杂度为 O (gen2∙knm),并且 Psize<knm,gen2<gen1∙Psize,因此 本文算法的时间复杂度为 O(Itermax∙gen1∙(Psize + Cmax∙N)∙knm)。 3 实验数据与分析 3.1 PCLSFA 的性能测试 选取了 4 个标准的无约束测试函数 f 1 ~ f 4 [17⁃18] : Ackley ( xi ∈ [ - 30, 30 ])、 Rosenbrock ( xi ∈ [-2.048,2.048])、Rastrigin( xi ∈ [ - 5. 12,5. 12])、 Griewank(xi∈ [-600,600]) 进行仿真测试,它们的 最优解都是 0。 通过 FA、采用串行 CLS 分别改进 PSO 和 FA 算法的 CLSPSO [9] 和 CLSFA 进行对比分 析,以验证 PCLSFA 的收敛性能及寻优能力。 各算 法种群规模都为 Npop = 40,最大迭代数 Tmax = 2 000,3 种具有 CLS 机制的算法中取 Cmax = 10,C = 5。 考虑 FA 对 不 同 函 数 的 收 敛 性 能 不 同, 在 CLSFA 和 PCLSFA 前期执行粗搜索的迭代数也不相同,对 f 1 和 f 4取 Tmax1 = 500,对 f 2 取 Tmax1 = 0,对 f 3 取 Tmax1 = 200。 CLSPSO 中采用线性递减的惯性权重 w [9] ,且 wmax = 0.9,wmin = 0.4,学习因子为 c1 = c2 = 1.496。 FA 型算法中统一设置 γ = 1,随机步长 α 随着迭代次数 t 的增加不断减小为 α t+1 = α t ((10 - 4 / 0.9) ∧ (b / Tmax)) 式中:α 的初始值为 1,b 是控制收敛精度的参数,对 算法的收敛性能具有较大的影响,偏大会导致早熟 收敛,偏小则会使算法无法更精确地搜索到全局最 优解,经过实验对比分析本文取 b = 3。 此外,为防 止距离太大使算法失效,还需对 β 进行调整,即为 β =(β max - β min )e -γr 2 ij + β min ,其中 β max = 1, β min = 0.2。 对搜索空间较小的函数 f 1 ~ f 3取 lPCLS = 0.1l ,对 搜索空间较大的函数 f 4 取 lPCLS = 0.01l 。 此外, PCLSFA 中的 N= 15,Np = 50,nc = 20, ϕ = 0.4。 仿真实验基于 MATLAB2010b 平台,计算机 的硬 件 配 置 为: Intel Core i5⁃4 200 M CPU 2. 5 GHz、4 GB RAM。 各函数的维数均为 30,每种算 法独立运行 30 次,计算各自的最大值、最小值、 平均值和标准差,记录至表 1。 对各函数的收敛 曲线为 30 次运行的平均结果,分别如图 2 所示, 为了更明显的比较,图中纵坐标是对最优解求 lg ( f )后的平均值。 表 1 4 个基准函数的实验结果 Table 1 The experiment results for four test functions 函数 算法 最小值 最大值 平均值 标准差 f 1 FA CLSPSO CLSFA PCLSFA 3.763×10 -4 7.994×10 -15 1.139×10 -10 1.052×10 -10 6.981×10 -3 2.660 5 0.052 2 1.496×10 -10 3.084×10 -3 1.291 6 0.020 1 1.259×10 -10 1.962×10 -3 0.934 4 0.026 0 1.212×10 -11 f 2 FA CLSPSO CLSFA PCLSFA 26.575 0 7.919×10 -4 0.030 2 2.208×10 -3 29.210 0 4.222 1 32.154 2 0.213 5 28.306 0 0.265 1 4.076 0 0.130 8 0.804 6 0.717 8 9.609 3 0.066 9 f 3 FA CLSPSO CLSFA PCLSFA 20.895 0 59.697 0 10.861 7 6.574 8 47.820 0 112.431 0 38.601 4 22.109 1 30.911 6 88.551 7 21.039 2 13.212 9 7.167 8 12.532 2 5.803 0 4.387 2 f 4 FA CLSPSO CLSFA PCLSFA 3.089×10 -5 7.116×10 -14 1.112×10 -16 1.110×10 -16 3.441×10 -4 0.048 9 3.296×10 -4 5.541×10 -16 1.030×10 -4 9.674×10 -3 9.873×10 -5 3.331×10 -16 7.068×10 -5 0.011 7 1.508×10 -4 1.655×10 -16 根据表 1 可见,PCLSFA 对各函数求出的最优 解的平均值及标准差均为最小,表明算法具有较高 的寻优精度与稳定性。 虽然对 f 1和 f 2 ,CLSPSO 能搜 索到更佳的最小值,但相应的概率较小,从其偏大的 平均值和标准差可以看出。 并且,CLSFA 对于 f 1和 f 4能够获得的最小值与 PCLSFA 接近,但其很不稳 定使其平均值相对较差,有效验证了并行 CLS 相对 于串行 CLS 的优势。 由图 2 可见 PCLSFA 对 f 1和 f 4 的收敛性均取得了显著的提高,对于相对较难寻优 的 f 2和 f 3也取得了一定的提高。 因此,表 1 和图 2 中的实验结果有效验证了本文算法的收敛性。 尽管 PCLSFA 对复杂函数的寻优精度方面还有待改进, ·876· 智 能 系 统 学 报 第 10 卷