正在加载图片...
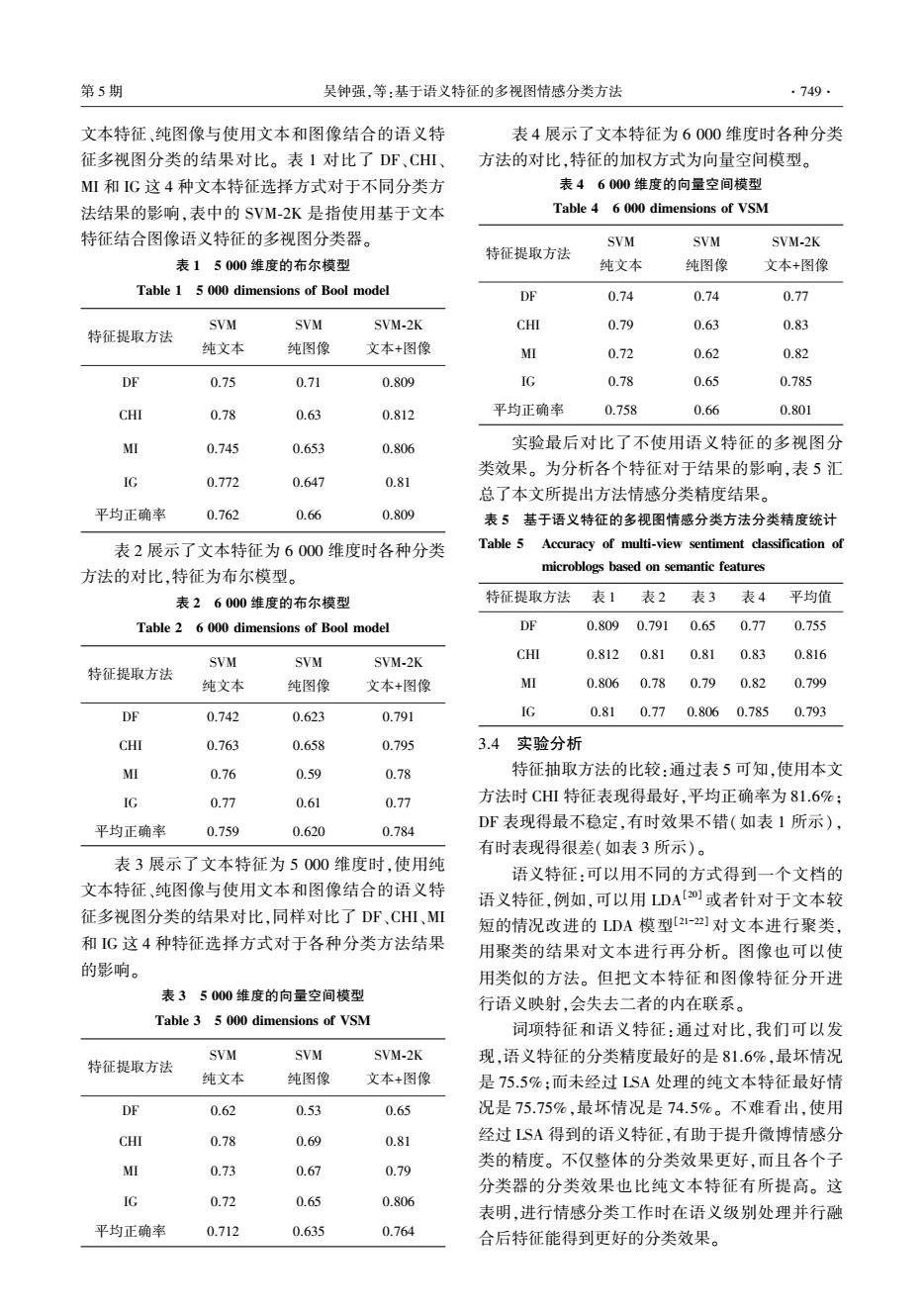
第5期 吴钟强,等:基于语义特征的多视图情感分类方法 .749 文本特征、纯图像与使用文本和图像结合的语义特 表4展示了文本特征为6000维度时各种分类 征多视图分类的结果对比。表1对比了DF、CHⅢ 方法的对比,特征的加权方式为向量空间模型。 MI和IG这4种文本特征选择方式对于不同分类方 表46000维度的向量空间模型 法结果的影响,表中的SVM-2K是指使用基于文本 Table 4 6 000 dimensions of VSM 特征结合图像语义特征的多视图分类器。 SVM SVM SVM-2K 特征提取方法 表15000维度的布尔模型 纯文本 纯图像 文本+图像 Table 1 5 000 dimensions of Bool model DF 0.74 0.74 0.77 SVM SVM SVM-2K CHI 0.79 0.63 0.83 特征提取方法 纯文本 纯图像 文本+图像 MI 0.72 0.62 0.82 DF 0.75 0.71 0.809 IG 0.78 0.65 0.785 CHI 0.78 0.63 0.812 平均正确率 0.758 0.66 0.801 MI 0.745 0.653 0.806 实验最后对比了不使用语义特征的多视图分 类效果。为分析各个特征对于结果的影响,表5汇 IG 0.772 0.647 0.81 总了本文所提出方法情感分类精度结果。 平均正确率 0.762 0.66 0.809 表5基于语义特征的多视图情感分类方法分类精度统计 表2展示了文本特征为6000维度时各种分类 Table 5 Accuracy of multi-view sentiment classification of 方法的对比,特征为布尔模型。 microblogs based on semantic features 表26000维度的布尔模型 特征提取方法 表1 表2 表3 表4 平均值 Table 2 6 000 dimensions of Bool model DE 0.809 0.791 0.65 0.77 0.755 SVM SVM SVM-2K CHI 0.812 0.81 0.81 0.83 0.816 特征提取方法 纯文本 纯图像 文本+图像 MI 0.806 0.78 0.79 0.82 0.799 DF 0.742 0.623 0.791 IG 0.81 0.77 0.8060.785 0.793 CHI 0.763 0.658 0.795 3.4 实验分析 MI 0.76 0.59 0.78 特征抽取方法的比较:通过表5可知,使用本文 IG 0.77 0.61 0.77 方法时CHⅢ特征表现得最好,平均正确率为81.6%; 平均正确率 0.759 0.620 0.784 DF表现得最不稳定,有时效果不错(如表1所示), 有时表现得很差(如表3所示)。 表3展示了文本特征为5000维度时,使用纯 语义特征:可以用不同的方式得到一个文档的 文本特征、纯图像与使用文本和图像结合的语义特 语义特征,例如,可以用DA[20或者针对于文本较 征多视图分类的结果对比,同样对比了DF、CHⅢ、MI 短的情况改进的LDA模型[2I-]对文本进行聚类, 和IG这4种特征选择方式对于各种分类方法结果 用聚类的结果对文本进行再分析。图像也可以使 的影响。 用类似的方法。但把文本特征和图像特征分开进 表35000维度的向量空间模型 行语义映射,会失去二者的内在联系。 Table 3 5 000 dimensions of VSM 词项特征和语义特征:通过对比,我们可以发 SVM SVM SVM-2K 现,语义特征的分类精度最好的是81.6%,最坏情况 特征提取方法 纯文本 纯图像 文本+图像 是75.5%:而未经过LSA处理的纯文本特征最好情 DF 0.62 0.53 0.65 况是75.75%,最坏情况是74.5%。不难看出,使用 CHI 0.78 0.69 0.81 经过LSA得到的语义特征,有助于提升微博情感分 MI 类的精度。不仅整体的分类效果更好,而且各个子 0.73 0.67 0.79 分类器的分类效果也比纯文本特征有所提高。这 IG 0.72 0.65 0.806 表明,进行情感分类工作时在语义级别处理并行融 平均正确率 0.712 0.635 0.764 合后特征能得到更好的分类效果。文本特征、纯图像与使用文本和图像结合的语义特 征多视图分类的结果对比。 表 1 对比了 DF、CHI、 MI 和 IG 这 4 种文本特征选择方式对于不同分类方 法结果的影响,表中的 SVM⁃2K 是指使用基于文本 特征结合图像语义特征的多视图分类器。 表 1 5 000 维度的布尔模型 Table 1 5 000 dimensions of Bool model 特征提取方法 SVM 纯文本 SVM 纯图像 SVM⁃2K 文本+图像 DF 0.75 0.71 0.809 CHI 0.78 0.63 0.812 MI 0.745 0.653 0.806 IG 0.772 0.647 0.81 平均正确率 0.762 0.66 0.809 表 2 展示了文本特征为 6 000 维度时各种分类 方法的对比,特征为布尔模型。 表 2 6 000 维度的布尔模型 Table 2 6 000 dimensions of Bool model 特征提取方法 SVM 纯文本 SVM 纯图像 SVM⁃2K 文本+图像 DF 0.742 0.623 0.791 CHI 0.763 0.658 0.795 MI 0.76 0.59 0.78 IG 0.77 0.61 0.77 平均正确率 0.759 0.620 0.784 表 3 展示了文本特征为 5 000 维度时,使用纯 文本特征、纯图像与使用文本和图像结合的语义特 征多视图分类的结果对比,同样对比了 DF、CHI、MI 和 IG 这 4 种特征选择方式对于各种分类方法结果 的影响。 表 3 5 000 维度的向量空间模型 Table 3 5 000 dimensions of VSM 特征提取方法 SVM 纯文本 SVM 纯图像 SVM⁃2K 文本+图像 DF 0.62 0.53 0.65 CHI 0.78 0.69 0.81 MI 0.73 0.67 0.79 IG 0.72 0.65 0.806 平均正确率 0.712 0.635 0.764 表 4 展示了文本特征为 6 000 维度时各种分类 方法的对比,特征的加权方式为向量空间模型。 表 4 6 000 维度的向量空间模型 Table 4 6 000 dimensions of VSM 特征提取方法 SVM 纯文本 SVM 纯图像 SVM⁃2K 文本+图像 DF 0.74 0.74 0.77 CHI 0.79 0.63 0.83 MI 0.72 0.62 0.82 IG 0.78 0.65 0.785 平均正确率 0.758 0.66 0.801 实验最后对比了不使用语义特征的多视图分 类效果。 为分析各个特征对于结果的影响,表 5 汇 总了本文所提出方法情感分类精度结果。 表 5 基于语义特征的多视图情感分类方法分类精度统计 Table 5 Accuracy of multi⁃view sentiment classification of microblogs based on semantic features 特征提取方法 表 1 表 2 表 3 表 4 平均值 DF 0.809 0.791 0.65 0.77 0.755 CHI 0.812 0.81 0.81 0.83 0.816 MI 0.806 0.78 0.79 0.82 0.799 IG 0.81 0.77 0.806 0.785 0.793 3.4 实验分析 特征抽取方法的比较:通过表 5 可知,使用本文 方法时 CHI 特征表现得最好,平均正确率为 81.6%; DF 表现得最不稳定,有时效果不错(如表 1 所示), 有时表现得很差(如表 3 所示)。 语义特征:可以用不同的方式得到一个文档的 语义特征,例如,可以用 LDA [20] 或者针对于文本较 短的情况改进的 LDA 模型[21-22] 对文本进行聚类, 用聚类的结果对文本进行再分析。 图像也可以使 用类似的方法。 但把文本特征和图像特征分开进 行语义映射,会失去二者的内在联系。 词项特征和语义特征:通过对比,我们可以发 现,语义特征的分类精度最好的是 81.6%,最坏情况 是 75.5%;而未经过 LSA 处理的纯文本特征最好情 况是 75.75%,最坏情况是 74.5%。 不难看出,使用 经过 LSA 得到的语义特征,有助于提升微博情感分 类的精度。 不仅整体的分类效果更好,而且各个子 分类器的分类效果也比纯文本特征有所提高。 这 表明,进行情感分类工作时在语义级别处理并行融 合后特征能得到更好的分类效果。 第 5 期 吴钟强,等:基于语义特征的多视图情感分类方法 ·749·