正在加载图片...
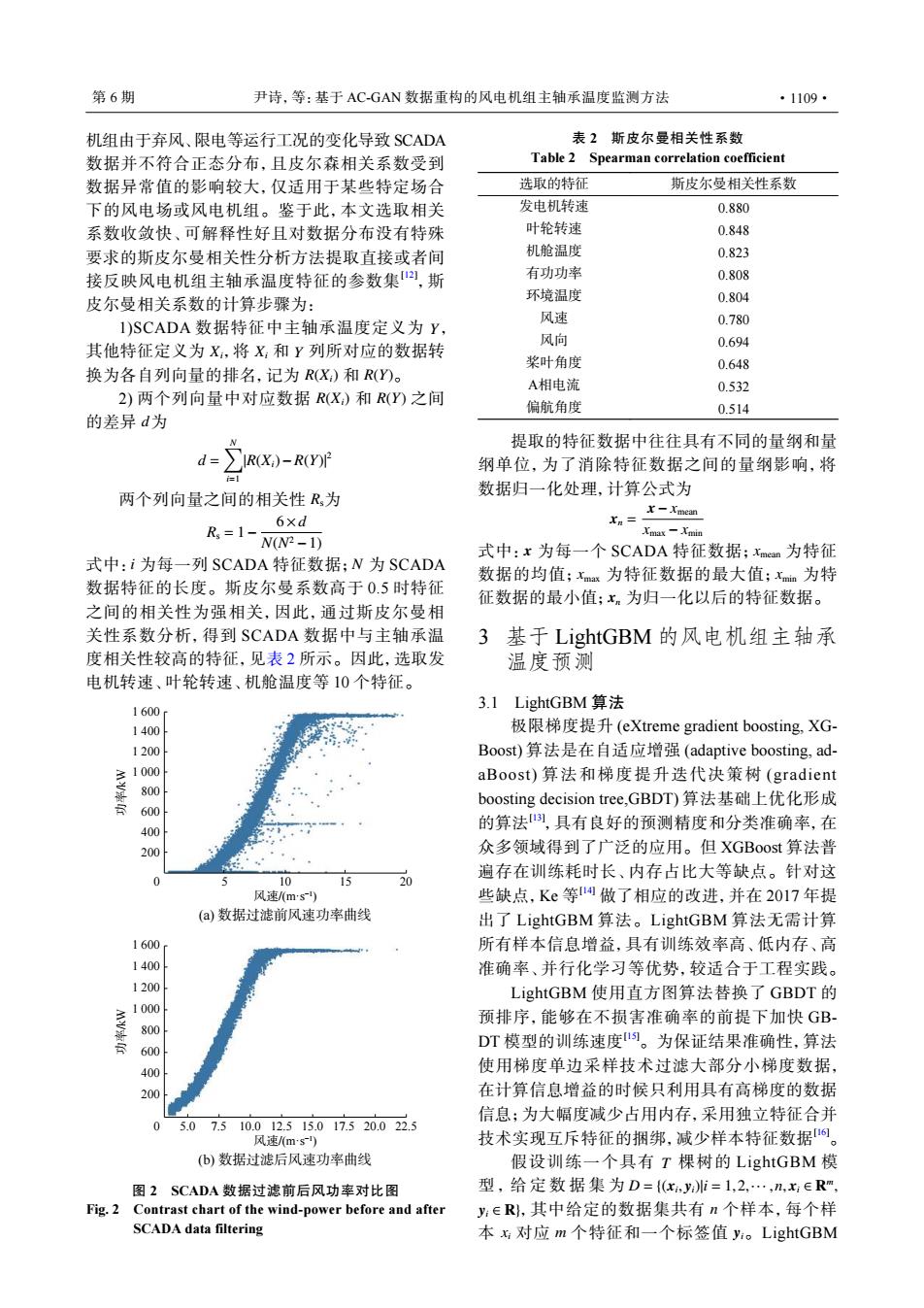
第6期 尹诗,等:基于AC-GAN数据重构的风电机组主轴承温度监测方法 ·1109· 机组由于弃风、限电等运行工况的变化导致SCADA 表2斯皮尔曼相关性系数 数据并不符合正态分布,且皮尔森相关系数受到 Table 2 Spearman correlation coefficient 数据异常值的影响较大,仅适用于某些特定场合 选取的特征 斯皮尔曼相关性系数 下的风电场或风电机组。鉴于此,本文选取相关 发电机转速 0.880 系数收敛快、可解释性好且对数据分布没有特殊 叶轮转速 0.848 要求的斯皮尔曼相关性分析方法提取直接或者间 机舱温度 0.823 接反映风电机组主轴承温度特征的参数集),斯 有功功率 0.808 皮尔曼相关系数的计算步骤为: 环境温度 0.804 I)SCADA数据特征中主轴承温度定义为Y, 风速 0.780 风向 其他特征定义为X,将X:和Y列所对应的数据转 0.694 桨叶角度 0.648 换为各自列向量的排名,记为R(X)和R(Y)。 A相电流 0.532 2)两个列向量中对应数据RX)和R()之间 偏航角度 0.514 的差异d为 提取的特征数据中往往具有不同的量纲和量 d= IR(X)-R(Y) 纲单位,为了消除特征数据之间的量纲影响,将 两个列向量之间的相关性R为 数据归一化处理,计算公式为 6×d R.=1-N(N-1) =mcm Xmax-Xmin 式中:x为每一个SCADA特征数据;Xmean为特征 式中:i为每一列SCADA特征数据:N为SCADA 数据的均值;xmax为特征数据的最大值;xn为特 数据特征的长度。斯皮尔曼系数高于0.5时特征 征数据的最小值:x。为归一化以后的特征数据。 之间的相关性为强相关,因此,通过斯皮尔曼相 关性系数分析,得到SCADA数据中与主轴承温 3 基于LightGBM的风电机组主轴承 度相关性较高的特征,见表2所示。因此,选取发 温度预测 电机转速、叶轮转速、机舱温度等10个特征。 3.1 LightGBM算法 1600 1400 极限梯度提升(eXtreme gradient boosting,XG- 1200 Boost)算法是在自适应增强(adaptive boosting,ad- 1000 aBoost)算法和梯度提升迭代决策树(gradient 800 600 boosting decision tree,GBDT)算法基础上优化形成 400 的算法1,具有良好的预测精度和分类准确率,在 200 众多领域得到了广泛的应用。但XGBoost算法普 0 5 10 15 20 遍存在训练耗时长、内存占比大等缺点。针对这 风速/ms 些缺点,Ke等做了相应的改进,并在2017年提 (a)数据过滤前风速功率曲线 出了LightGBM算法。LightGBM算法无需计算 1600 所有样本信息增益,具有训练效率高、低内存、高 1400 准确率、并行化学习等优势,较适合于工程实践。 1200 LightGBM使用直方图算法替换了GBDT的 1000 预排序,能够在不损害准确率的前提下加快GB 800 600 DT模型的训练速度9。为保证结果准确性,算法 400 使用梯度单边采样技术过滤大部分小梯度数据, 200 在计算信息增益的时候只利用具有高梯度的数据 7.510.012.515.017.520.022.5 信息;为大幅度减少占用内存,采用独立特征合并 0 5.0 风速/(ms) 技术实现互斥特征的捆绑,减少样本特征数据。 (b)数据过滤后风速功率曲线 假设训练一个具有T棵树的LightGBM模 图2 SCADA数据过滤前后风功率对比图 型,给定数据集为D={(xyi=1,2…,n,∈R Fig.2 Contrast chart of the wind-power before and after y:∈R,其中给定的数据集共有n个样本,每个样 SCADA data filtering 本:对应m个特征和一个标签值y:。LightGBM机组由于弃风、限电等运行工况的变化导致 SCADA 数据并不符合正态分布,且皮尔森相关系数受到 数据异常值的影响较大,仅适用于某些特定场合 下的风电场或风电机组。鉴于此,本文选取相关 系数收敛快、可解释性好且对数据分布没有特殊 要求的斯皮尔曼相关性分析方法提取直接或者间 接反映风电机组主轴承温度特征的参数集[12] ,斯 皮尔曼相关系数的计算步骤为: Y Xi Xi Y R(Xi) R(Y) 1)SCADA 数据特征中主轴承温度定义为 , 其他特征定义为 ,将 和 列所对应的数据转 换为各自列向量的排名,记为 和 。 R(Xi) R(Y) d 2) 两个列向量中对应数据 和 之间 的差异 为 d = ∑N i=1 |R(Xi)−R(Y)| 2 两个列向量之间的相关性 Rs为 Rs = 1− 6×d N(N2 −1) 式中: i 为每一列 SCADA 特征数据; N 为 SCADA 数据特征的长度。斯皮尔曼系数高于 0.5 时特征 之间的相关性为强相关,因此,通过斯皮尔曼相 关性系数分析,得到 SCADA 数据中与主轴承温 度相关性较高的特征,见表 2 所示。因此,选取发 电机转速、叶轮转速、机舱温度等 10 个特征。 5 10 15 20 风速/(m·s−1) (a) 数据过滤前风速功率曲线 0 200 400 600 800 1 000 1 200 1 400 1 600 功率/kW 0 200 400 600 800 1 000 1 200 1 400 1 600 功率/kW 5.0 7.5 10.0 12.5 15.0 17.5 20.0 22.5 风速/(m·s−1) (b) 数据过滤后风速功率曲线 图 2 SCADA 数据过滤前后风功率对比图 Fig. 2 Contrast chart of the wind-power before and after SCADA data filtering 表 2 斯皮尔曼相关性系数 Table 2 Spearman correlation coefficient 选取的特征 斯皮尔曼相关性系数 发电机转速 0.880 叶轮转速 0.848 机舱温度 0.823 有功功率 0.808 环境温度 0.804 风速 0.780 风向 0.694 桨叶角度 0.648 A相电流 0.532 偏航角度 0.514 提取的特征数据中往往具有不同的量纲和量 纲单位,为了消除特征数据之间的量纲影响,将 数据归一化处理,计算公式为 xn = x− xmean xmax − xmin x xmean xmax xmin xn 式中: 为每一个 SCADA 特征数据; 为特征 数据的均值; 为特征数据的最大值; 为特 征数据的最小值; 为归一化以后的特征数据。 3 基于 LightGBM 的风电机组主轴承 温度预测 3.1 LightGBM 算法 极限梯度提升 (eXtreme gradient boosting, XGBoost) 算法是在自适应增强 (adaptive boosting, adaBoost) 算法和梯度提升迭代决策树 (gradient boosting decision tree,GBDT) 算法基础上优化形成 的算法[13] ,具有良好的预测精度和分类准确率,在 众多领域得到了广泛的应用。但 XGBoost 算法普 遍存在训练耗时长、内存占比大等缺点。针对这 些缺点,Ke 等 [14] 做了相应的改进,并在 2017 年提 出了 LightGBM 算法。LightGBM 算法无需计算 所有样本信息增益,具有训练效率高、低内存、高 准确率、并行化学习等优势,较适合于工程实践。 LightGBM 使用直方图算法替换了 GBDT 的 预排序,能够在不损害准确率的前提下加快 GBDT 模型的训练速度[15]。为保证结果准确性,算法 使用梯度单边采样技术过滤大部分小梯度数据, 在计算信息增益的时候只利用具有高梯度的数据 信息;为大幅度减少占用内存,采用独立特征合并 技术实现互斥特征的捆绑,减少样本特征数据[16]。 T D = {(xi , yi)|i = 1,2,··· ,n, xi ∈ R m , yi ∈ R} n xi m yi 假设训练一个具有 棵树的 LightGBM 模 型,给定数据集为 ,其中给定的数据集共有 个样本,每个样 本 对应 个特征和一个标签值 。LightGBM 第 6 期 尹诗,等:基于 AC-GAN 数据重构的风电机组主轴承温度监测方法 ·1109·