正在加载图片...
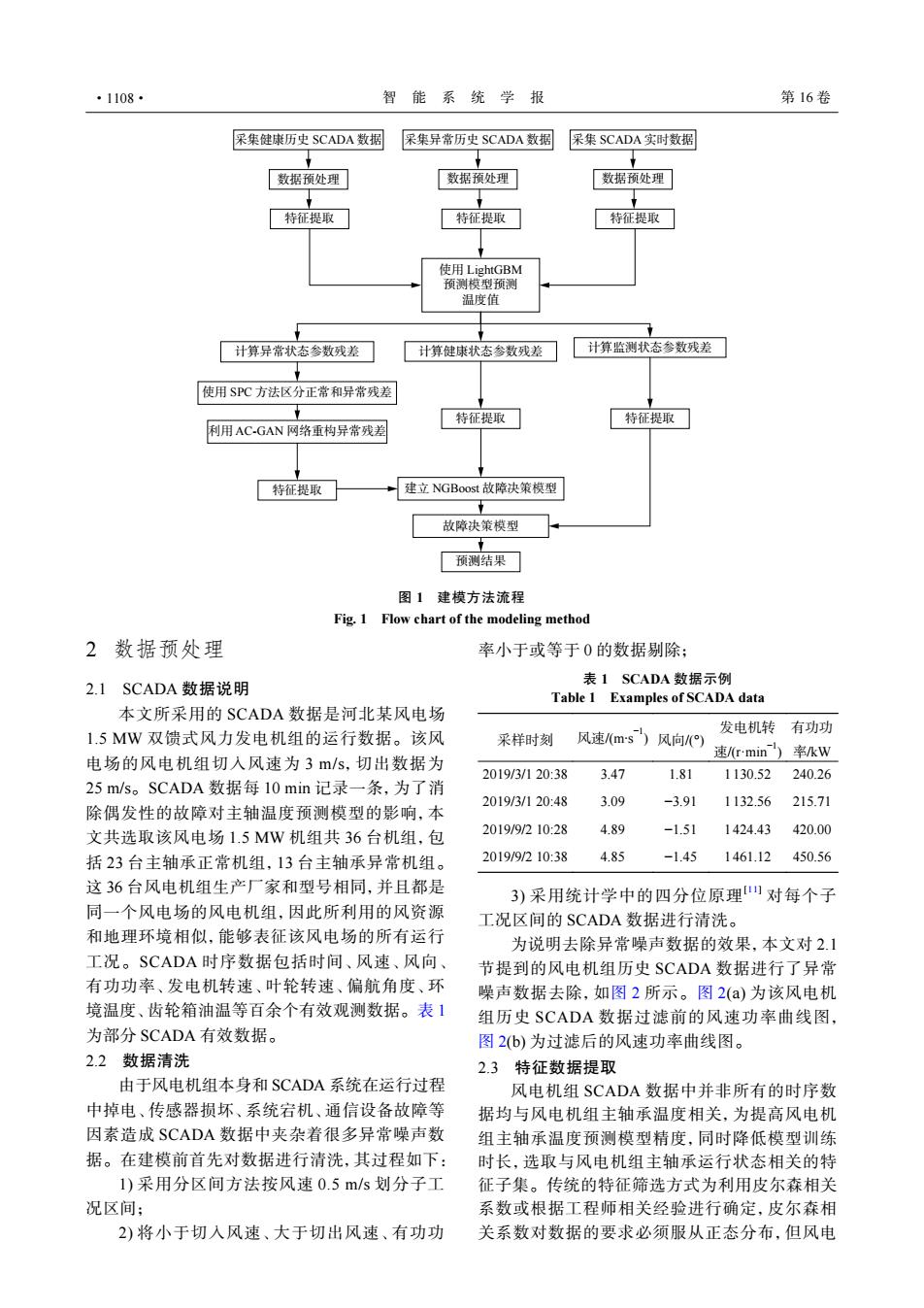
·1108· 智能系统学报 第16卷 采集健康历史SCADA数据 呆集异常历史SCADA数据 采集SCADA实时数据 数据预处理 数据预处理 数据预处理 特征提取 特征提取 特征提取 使用LightGBM 预测模型预测 温度值 计算异常状态参数残差 计算健康状态参数残差 计算监测状态参数残差 使用SPC方法区分正常和异常残差 特征提取 特征提取 利用AC-GAN网络重构异常残差 特征提取 建立NGBoost故障决策模型 故障决策模型 预测结果 图1建模方法流程 Fig.1 Flow chart of the modeling method 2数据预处理 率小于或等于0的数据别除: 表1 SCADA数据示例 2.1 SCADA数据说明 Table 1 Examples of SCADA data 本文所采用的SCADA数据是河北某风电场 1.5MW双馈式风力发电机组的运行数据。该风 采样时刻 风速ms风向/() 发电机转有功功 速/rmin率W 电场的风电机组切入风速为3m/s,切出数据为 2019/3/120:38 3.47 1.81 1130.52 240.26 25m/s。SCADA数据每10min记录一条,为了消 2019/3/120:48 3.09 -3.91 1132.56 215.71 除偶发性的故障对主轴温度预测模型的影响,本 文共选取该风电场1.5MW机组共36台机组,包 2019/9/210:28 4.89 -1.51 1424.43 420.00 括23台主轴承正常机组,13台主轴承异常机组。 2019/9/210:38 4.85 -1.45 1461.12450.56 这36台风电机组生产厂家和型号相同,并且都是 3)采用统计学中的四分位原理山对每个子 同一个风电场的风电机组,因此所利用的风资源 工况区间的SCADA数据进行清洗。 和地理环境相似,能够表征该风电场的所有运行 为说明去除异常噪声数据的效果,本文对2.1 工况。SCADA时序数据包括时间、风速、风向、 节提到的风电机组历史SCADA数据进行了异常 有功功率、发电机转速、叶轮转速、偏航角度、环 噪声数据去除,如图2所示。图2(a)为该风电机 境温度、齿轮箱油温等百余个有效观测数据。表1 组历史SCADA数据过滤前的风速功率曲线图, 为部分SCADA有效数据。 图2(b)为过滤后的风速功率曲线图。 2.2数据清洗 2.3特征数据提取 由于风电机组本身和SCADA系统在运行过程 风电机组SCADA数据中并非所有的时序数 中掉电、传感器损坏、系统宕机、通信设备故障等 据均与风电机组主轴承温度相关,为提高风电机 因素造成SCADA数据中夹杂着很多异常噪声数 组主轴承温度预测模型精度,同时降低模型训练 据。在建模前首先对数据进行清洗,其过程如下: 时长,选取与风电机组主轴承运行状态相关的特 1)采用分区间方法按风速0.5m/s划分子工 征子集。传统的特征筛选方式为利用皮尔森相关 况区间; 系数或根据工程师相关经验进行确定,皮尔森相 2)将小于切入风速、大于切出风速、有功功 关系数对数据的要求必须服从正态分布,但风电数据预处理 数据预处理 特征提取 特征提取 计算异常状态参数残差 计算健康状态参数残差 采集异常历史 SCADA 数据 特征提取 计算监测状态参数残差 数据预处理 特征提取 特征提取 特征提取 采集 SCADA 实时数据 预测结果 故障决策模型 采集健康历史 SCADA 数据 使用 LightGBM 预测模型预测 温度值 使用 SPC 方法区分正常和异常残差 利用 AC-GAN 网络重构异常残差 建立 NGBoost 故障决策模型 图 1 建模方法流程 Fig. 1 Flow chart of the modeling method 2 数据预处理 2.1 SCADA 数据说明 本文所采用的 SCADA 数据是河北某风电场 1.5 MW 双馈式风力发电机组的运行数据。该风 电场的风电机组切入风速为 3 m/s,切出数据为 25 m/s。SCADA 数据每 10 min 记录一条,为了消 除偶发性的故障对主轴温度预测模型的影响,本 文共选取该风电场 1.5 MW 机组共 36 台机组,包 括 23 台主轴承正常机组,13 台主轴承异常机组。 这 36 台风电机组生产厂家和型号相同,并且都是 同一个风电场的风电机组,因此所利用的风资源 和地理环境相似,能够表征该风电场的所有运行 工况。SCADA 时序数据包括时间、风速、风向、 有功功率、发电机转速、叶轮转速、偏航角度、环 境温度、齿轮箱油温等百余个有效观测数据。表 1 为部分 SCADA 有效数据。 2.2 数据清洗 由于风电机组本身和 SCADA 系统在运行过程 中掉电、传感器损坏、系统宕机、通信设备故障等 因素造成 SCADA 数据中夹杂着很多异常噪声数 据。在建模前首先对数据进行清洗,其过程如下: 1) 采用分区间方法按风速 0.5 m/s 划分子工 况区间; 2) 将小于切入风速、大于切出风速、有功功 率小于或等于 0 的数据剔除; 表 1 SCADA 数据示例 Table 1 Examples of SCADA data 采样时刻 风速/(m∙s−1) 风向/(°) 发电机转 速/(r·min−1) 有功功 率/kW 2019/3/1 20:38 3.47 1.81 1 130.52 240.26 2019/3/1 20:48 3.09 −3.91 1 132.56 215.71 2019/9/2 10:28 4.89 −1.51 1 424.43 420.00 2019/9/2 10:38 4.85 −1.45 1 461.12 450.56 3) 采用统计学中的四分位原理[11] 对每个子 工况区间的 SCADA 数据进行清洗。 为说明去除异常噪声数据的效果,本文对 2.1 节提到的风电机组历史 SCADA 数据进行了异常 噪声数据去除,如图 2 所示。图 2(a) 为该风电机 组历史 SCADA 数据过滤前的风速功率曲线图, 图 2(b) 为过滤后的风速功率曲线图。 2.3 特征数据提取 风电机组 SCADA 数据中并非所有的时序数 据均与风电机组主轴承温度相关,为提高风电机 组主轴承温度预测模型精度,同时降低模型训练 时长,选取与风电机组主轴承运行状态相关的特 征子集。传统的特征筛选方式为利用皮尔森相关 系数或根据工程师相关经验进行确定,皮尔森相 关系数对数据的要求必须服从正态分布,但风电 ·1108· 智 能 系 统 学 报 第 16 卷