正在加载图片...
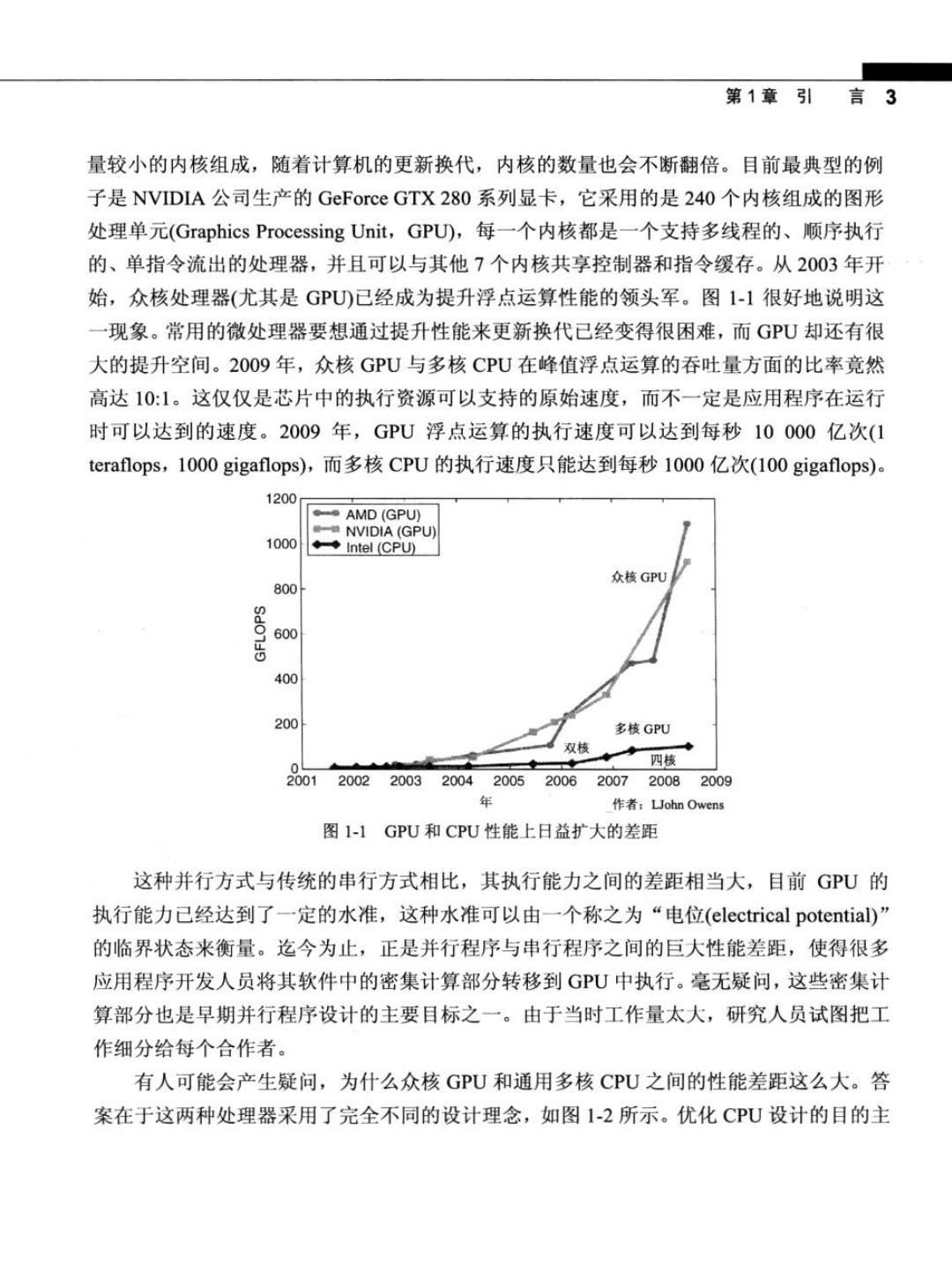
第1章引言3 量较小的内核组成,随着计算机的更新换代,内核的数量也会不断翻倍。目前最典型的例 子是NVIDIA公司生产的GeForce GTX280系列显卡,它采用的是240个内核组成的图形 处理单元(Graphics Processing Unit,GPU,每一个内核都是一个支持多线程的、顺序执行 的、单指令流出的处理器,并且可以与其他7个内核共享控制器和指令缓存。从2003年开 始,众核处理器(尤其是GPU)已经成为提升浮点运算性能的领头军。图1-1很好地说明这 一现象。常用的微处理器要想通过提升性能来更新换代已经变得很困难,而GPU却还有很 大的提升空间。20O9年,众核GPU与多核CPU在峰值浮点运算的吞吐量方面的比率竟然 高达10:1。这仅仅是芯片中的执行资源可以支持的原始速度,而不一定是应用程序在运行 时可以达到的速度。2009年,GPU浮点运算的执行速度可以达到每秒10000亿次(1 teraflops,1000 gigaflops),而多核CPU的执行速度只能达到每秒1000亿次(100 gigaflops)。 1200 AMD(GPU) NVIDIA(GPU) 1000 ◆◆Intel(CPU) 众核GPU 800 600 400 200 多核GPU 双核 0 四核 001 2002 2003 2004200520062007 20082009 作者:John Owens 图1-1GPU和CPU性能上日益扩大的差距 这种并行方式与传统的串行方式相比,其执行能力之间的差距相当大,目前GPU的 执行能力已经达到了一定的水准,这种水准可以由一个称之为“电位(electrical potential)” 的临界状态来衡量。迄今为止,正是并行程序与串行程序之间的巨大性能差距,使得很多 应用程序开发人员将其软件中的密集计算部分转移到GPU中执行。毫无疑问,这些密集计 算部分也是早期并行程序设计的主要目标之一。由于当时工作量太大,研究人员试图把工 作细分给每个合作者。 有人可能会产生疑问,为什么众核GPU和通用多核CPU之间的性能差距这么大。答 案在于这两种处理器采用了完全不同的设计理念,如图1-2所示。优化CPU设计的目的主