正在加载图片...
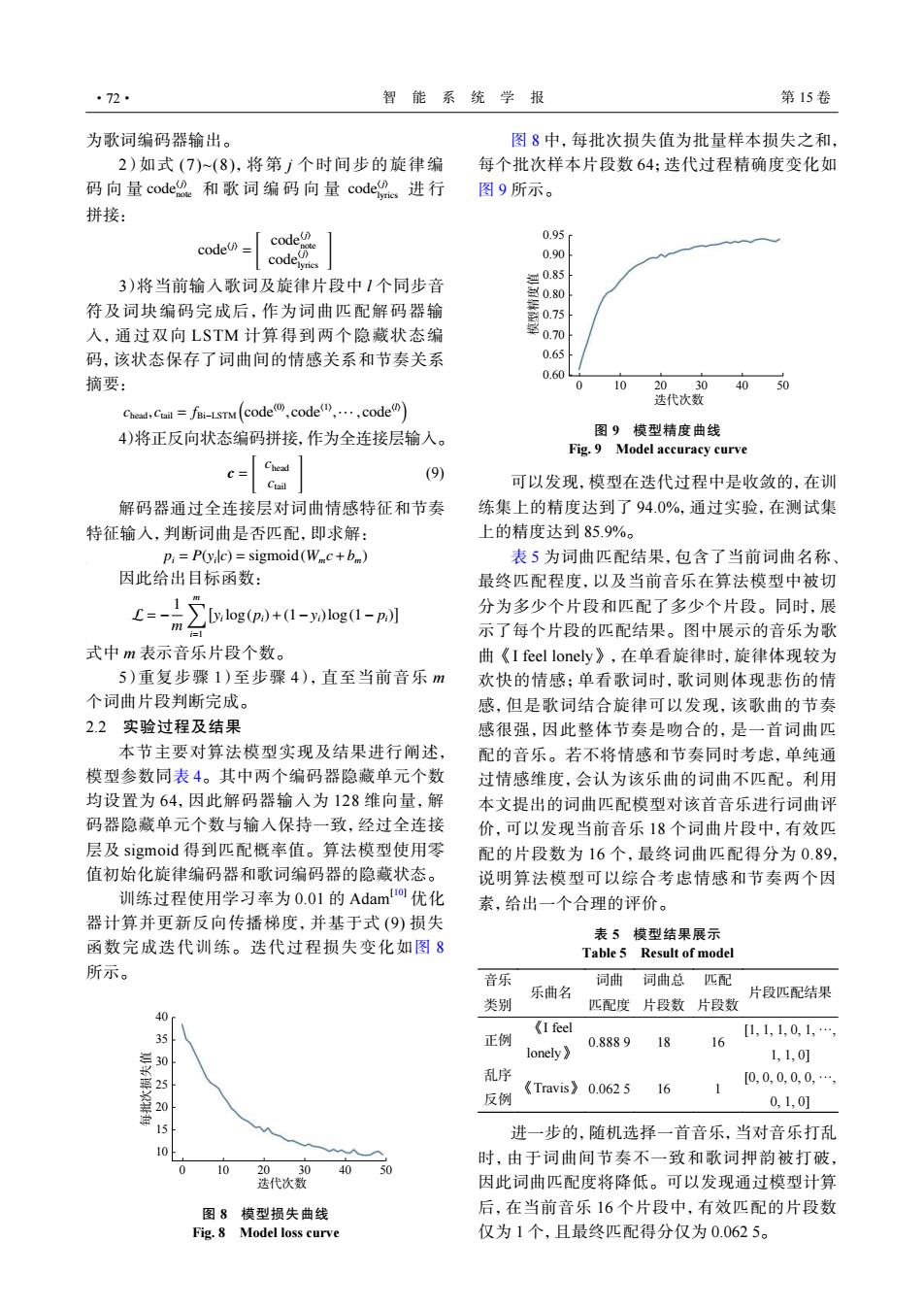
·72· 智能系统学报 第15卷 为歌词编码器输出。 图8中,每批次损失值为批量样本损失之和, 2)如式(7)~(8),将第j个时间步的旋律编 每个批次样本片段数64:迭代过程精确度变化如 码向量code和歌词编码向量code2进行 图9所示。 拼接: code 0.95 code」 codey 0.90 3)将当前输入歌词及旋律片段中1个同步音 0.85 符及词块编码完成后,作为词曲匹配解码器输 0.75 入,通过双向LSTM计算得到两个隐藏状态编 0.70 码,该状态保存了词曲间的情感关系和节奏关系 0.65 摘要: 0.60 0 10 2030 4050 迭代次数 Chead,caml=fBi-Lsnu(code(,code,…,code) 4)将正反向状态编码拼接,作为全连接层输入。 图9模型精度曲线 Fig.9 Model accuracy curve Chead (9) 可以发现,模型在迭代过程中是收敛的,在训 解码器通过全连接层对词曲情感特征和节奏 练集上的精度达到了94.0%,通过实验,在测试集 特征输入,判断词曲是否匹配,即求解: 上的精度达到85.9%。 p:=P(yalc)=sigmoid(Wc+b) 表5为词曲匹配结果,包含了当前词曲名称 因此给出目标函数: 最终匹配程度,以及当前音乐在算法模型中被切 1分 E=-二】 [y:log(pa)+(1-ya)log(1-pi)] 分为多少个片段和匹配了多少个片段。同时,展 m 示了每个片段的匹配结果。图中展示的音乐为歌 式中m表示音乐片段个数。 曲《I feel lonely》,在单看旋律时,旋律体现较为 5)重复步骤1)至步骤4),直至当前音乐m 欢快的情感;单看歌词时,歌词则体现悲伤的情 个词曲片段判断完成。 感,但是歌词结合旋律可以发现,该歌曲的节奏 2.2实验过程及结果 感很强,因此整体节奏是吻合的,是一首词曲匹 本节主要对算法模型实现及结果进行阐述, 配的音乐。若不将情感和节奏同时考虑,单纯通 模型参数同表4。其中两个编码器隐藏单元个数 过情感维度,会认为该乐曲的词曲不匹配。利用 均设置为64,因此解码器输入为128维向量,解 本文提出的词曲匹配模型对该首音乐进行词曲评 码器隐藏单元个数与输入保持一致,经过全连接 价,可以发现当前音乐18个词曲片段中,有效匹 层及sigmoid得到匹配概率值。算法模型使用零 配的片段数为16个,最终词曲匹配得分为0.89, 值初始化旋律编码器和歌词编码器的隐藏状态。 说明算法模型可以综合考虑情感和节奏两个因 训练过程使用学习率为0.01的Adam优化 素,给出一个合理的评价。 器计算并更新反向传播梯度,并基于式(9)损失 表5模型结果展示 函数完成迭代训练。迭代过程损失变化如图8 Table 5 Result of model 所示。 音乐 词曲 词曲总匹配 乐曲名 片段匹配结果 类别 匹配度片段数片段数 40 《I feel 35 正例 0.8889 18 [1,1,1,0,1,, 16 lonely》 1,1,0] 2 乱序 [0,0,0,0,0,…, 《Travis》0.0625 16 1 反例 0,1,0] 进一步的,随机选择一首音乐,当对音乐打乱 10 时,由于词曲间节奏不一致和歌词押韵被打破, 0 10 20。.30 40 50 迭代次数 因此词曲匹配度将降低。可以发现通过模型计算 图8模型损失曲线 后,在当前音乐16个片段中,有效匹配的片段数 Fig.8 Model loss curve 仅为1个,且最终匹配得分仅为0.0625。为歌词编码器输出。 code⟨j⟩ note code⟨j⟩ lyrics 2)如式 (7)~(8),将第 j 个时间步的旋律编 码向量 和歌词编码向量 进 行 拼接: code⟨j⟩ = [ code⟨j⟩ note code⟨j⟩ lyrics ] 3)将当前输入歌词及旋律片段中 l 个同步音 符及词块编码完成后,作为词曲匹配解码器输 入,通过双向 LSTM 计算得到两个隐藏状态编 码,该状态保存了词曲间的情感关系和节奏关系 摘要: chead, ctail = fBi−LSTM ( code⟨0⟩ , code⟨1⟩ ,··· , code⟨l⟩ ) 4)将正反向状态编码拼接,作为全连接层输入。 c = [ chead ctail ] (9) 解码器通过全连接层对词曲情感特征和节奏 特征输入,判断词曲是否匹配,即求解: pi = P(yi |c) = sigmoid(Wmc+bm) 因此给出目标函数: L = − 1 m ∑m i=1 [ yi log(pi)+(1−yi)log(1− pi) ] 式中 m 表示音乐片段个数。 5)重复步骤 1)至步骤 4),直至当前音乐 m 个词曲片段判断完成。 2.2 实验过程及结果 本节主要对算法模型实现及结果进行阐述, 模型参数同表 4。其中两个编码器隐藏单元个数 均设置为 64,因此解码器输入为 128 维向量,解 码器隐藏单元个数与输入保持一致,经过全连接 层及 sigmoid 得到匹配概率值。算法模型使用零 值初始化旋律编码器和歌词编码器的隐藏状态。 训练过程使用学习率为 0.01 的 Adam[10] 优化 器计算并更新反向传播梯度,并基于式 (9) 损失 函数完成迭代训练。迭代过程损失变化如图 8 所示。 35 40 30 25 每批次损失值 迭代次数 20 15 10 0 10 20 30 40 50 图 8 模型损失曲线 Fig. 8 Model loss curve 图 8 中,每批次损失值为批量样本损失之和, 每个批次样本片段数 64;迭代过程精确度变化如 图 9 所示。 0.95 0.90 0.85 0.80 0.75 模型精度值 0.70 0.65 0.60 0 10 20 迭代次数 30 40 50 图 9 模型精度曲线 Fig. 9 Model accuracy curve 可以发现,模型在迭代过程中是收敛的,在训 练集上的精度达到了 94.0%,通过实验,在测试集 上的精度达到 85.9%。 表 5 为词曲匹配结果,包含了当前词曲名称、 最终匹配程度,以及当前音乐在算法模型中被切 分为多少个片段和匹配了多少个片段。同时,展 示了每个片段的匹配结果。图中展示的音乐为歌 曲《I feel lonely》,在单看旋律时,旋律体现较为 欢快的情感;单看歌词时,歌词则体现悲伤的情 感,但是歌词结合旋律可以发现,该歌曲的节奏 感很强,因此整体节奏是吻合的,是一首词曲匹 配的音乐。若不将情感和节奏同时考虑,单纯通 过情感维度,会认为该乐曲的词曲不匹配。利用 本文提出的词曲匹配模型对该首音乐进行词曲评 价,可以发现当前音乐 18 个词曲片段中,有效匹 配的片段数为 16 个,最终词曲匹配得分为 0.89, 说明算法模型可以综合考虑情感和节奏两个因 素,给出一个合理的评价。 表 5 模型结果展示 Table 5 Result of model 音乐 类别 乐曲名 词曲 匹配度 词曲总 片段数 匹配 片段数 片段匹配结果 正例 《I feel lonely》 0.888 9 18 16 [1, 1, 1, 0, 1, ···, 1, 1, 0] 乱序 反例 《Travis》 0.062 5 16 1 [0, 0, 0, 0, 0, ···, 0, 1, 0] 进一步的,随机选择一首音乐,当对音乐打乱 时,由于词曲间节奏不一致和歌词押韵被打破, 因此词曲匹配度将降低。可以发现通过模型计算 后,在当前音乐 16 个片段中,有效匹配的片段数 仅为 1 个,且最终匹配得分仅为 0.062 5。 ·72· 智 能 系 统 学 报 第 15 卷