正在加载图片...
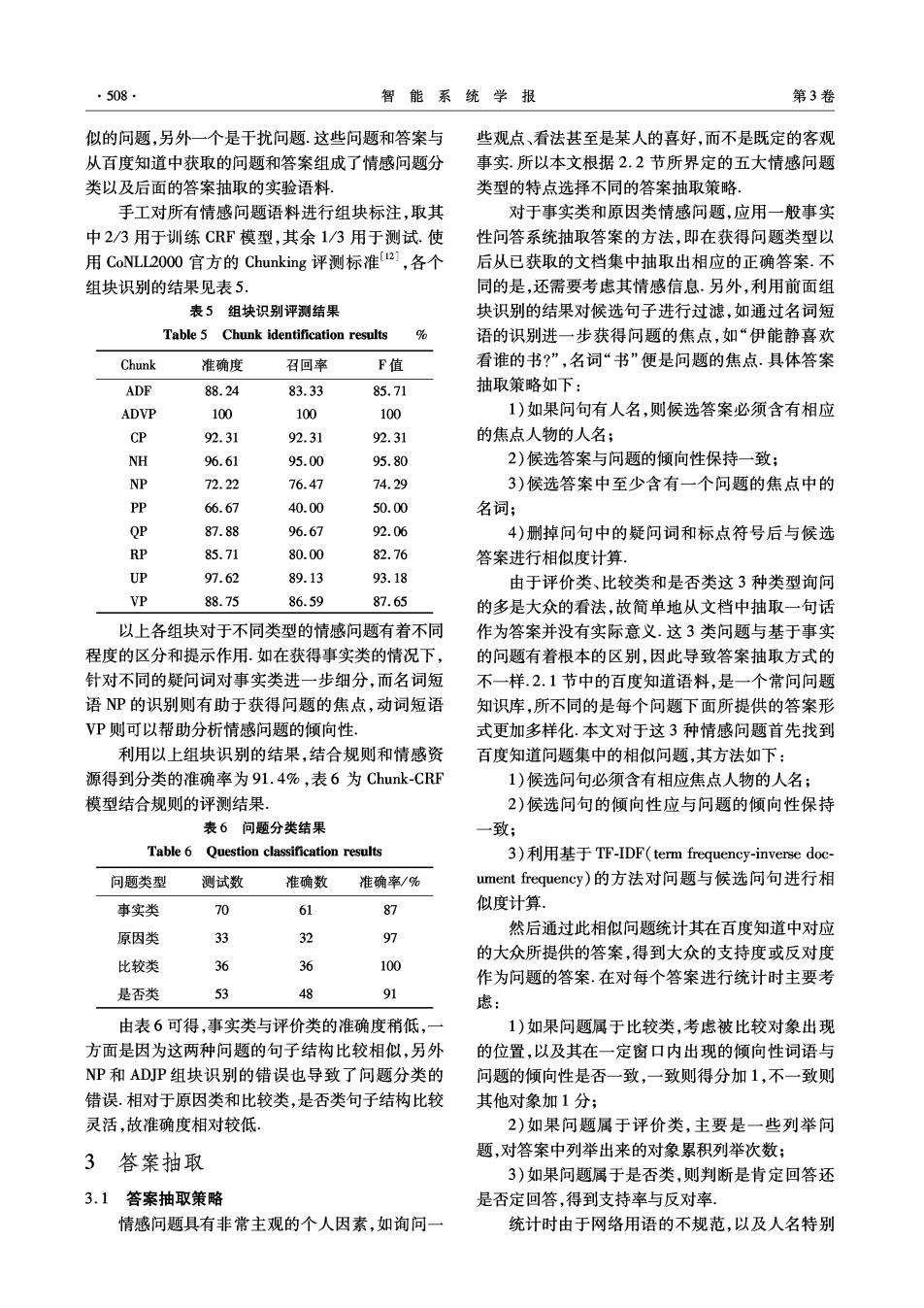
·508 智能系统学报 第3卷 似的问题,另外一个是干扰问题.这些问题和答案与 些观点、看法甚至是某人的喜好,而不是既定的客观 从百度知道中获取的问题和答案组成了情感问题分 事实.所以本文根据2.2节所界定的五大情感问题 类以及后面的答案抽取的实验语料。 类型的特点选择不同的答案抽取策略 手工对所有情感问题语料进行组块标注,取其 对于事实类和原因类情感问题,应用一般事实 中2/3用于训练CRF模型,其余1/3用于测试.使 性问答系统抽取答案的方法,即在获得问题类型以 用CoNLL20O0官方的Chunking评测标准a1,各个 后从已获取的文档集中抽取出相应的正确答案.不 组块识别的结果见表5. 同的是,还需要考虑其情感信息.另外,利用前面组 表5组块识别评测结果 块识别的结果对候选句子进行过滤,如通过名词短 Table 5 Chunk identification results 语的识别进一步获得问题的焦点,如“伊能静喜欢 Chunk 准确度 召回率 F值 看谁的书?”,名词“书”便是问题的焦点.具体答案 ADF 88.24 83.33 85.71 抽取策略如下: ADVP 100 100 100 1)如果问句有人名,则候选答案必须含有相应 CP 92.31 92.31 92.31 的焦点人物的人名; NH 96.61 95.00 95.80 2)候选答案与问题的倾向性保持一致; NP 72.22 76.47 74.29 3)候选答案中至少含有一个问题的焦点中的 PP 66.67 40.00 50.00 名词; QP 87.88 96.67 92.06 4)删掉问句中的疑问词和标点符号后与候选 RP 85.71 80.00 82.76 答案进行相似度计算。 UP 97.62 89.13 93.18 由于评价类、比较类和是否类这3种类型询问 P 88.75 86.59 87.65 的多是大众的看法,故简单地从文档中抽取一句话 以上各组块对于不同类型的情感问题有着不同 作为答案并没有实际意义.这3类问题与基于事实 程度的区分和提示作用.如在获得事实类的情况下, 的问题有着根本的区别,因此导致答案抽取方式的 针对不同的疑问词对事实类进一步细分,而名词短 不一样.2.1节中的百度知道语料,是一个常问问题 语NP的识别则有助于获得问题的焦点,动词短语 知识库,所不同的是每个问题下面所提供的答案形 VP则可以帮助分析情感问题的倾向性, 式更加多样化.本文对于这3种情感问题首先找到 利用以上组块识别的结果,结合规则和情感资 百度知道问题集中的相似问题,其方法如下: 源得到分类的准确率为91.4%,表6为Chunk-CRF 1)候选问句必须含有相应焦点人物的人名; 模型结合规则的评测结果 2)候选问句的倾向性应与问题的倾向性保持 表6问题分类结果 致; Table 6 Question classification results 3)利用基于TF-IDF(term frequency-inverse doc 问题类型 测试数 准确数 准确率/% ument frequency)的方法对问题与候选问句进行相 事实类 70 87 似度计算. 然后通过此相似问题统计其在百度知道中对应 原因类 33 32 97 比较类 哈 的大众所提供的答案,得到大众的支持度或反对度 36 100 作为问题的答案.在对每个答案进行统计时主要考 是否类 53 48 91 虑: 由表6可得,事实类与评价类的准确度稍低, 1)如果问题属于比较类,考虑被比较对象出现 方面是因为这两种问题的句子结构比较相似,另外 的位置,以及其在一定窗口内出现的倾向性词语与 NP和ADP组块识别的错误也导致了问题分类的 问题的倾向性是否一致,一致则得分加1,不一致则 错误.相对于原因类和比较类,是否类句子结构比较 其他对象加1分; 灵活,故准确度相对较低 2)如果问题属于评价类,主要是一些列举问 3答案抽取 题,对答案中列举出来的对象累积列举次数; 3)如果问题属于是否类,则判断是肯定回答还 3.1答案抽取策略 是否定回答,得到支持率与反对率. 情感问题具有非常主观的个人因素,如询问一 统计时由于网络用语的不规范,以及人名特别