正在加载图片...
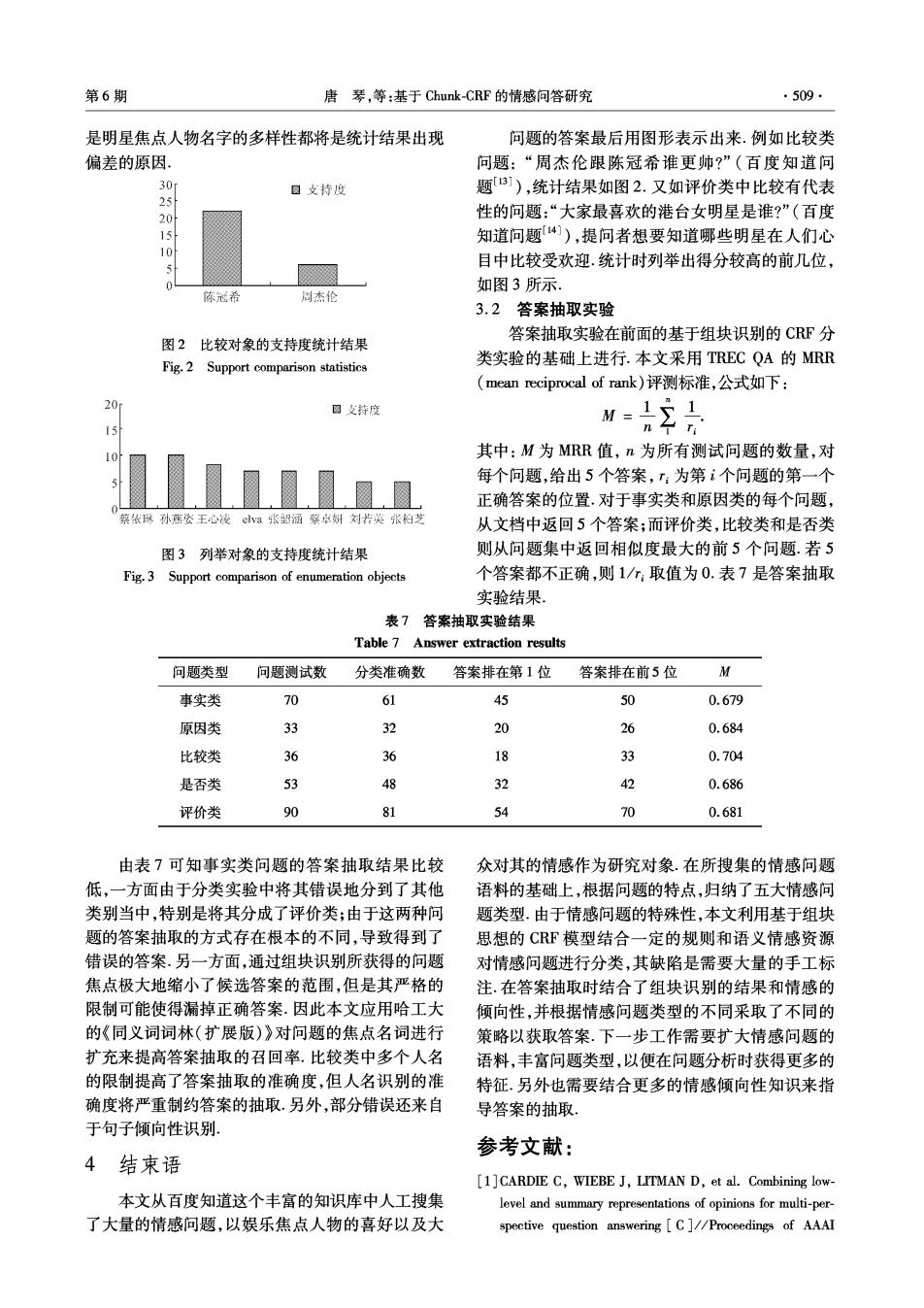
第6期 唐琴,等:基于Chunk-CRF的情感问答研究 ·509· 是明星焦点人物名字的多样性都将是统计结果出现 问题的答案最后用图形表示出来.例如比较类 偏差的原因. 问题:“周杰伦跟陈冠希谁更帅?”(百度知道问 30m 回文持搜 题31),统计结果如图2.又如评价类中比较有代表 20 性的问题:“大家最喜欢的港台女明星是谁?”(百度 15 知道问题4]),提问者想要知道哪些明星在人们心 10 目中比较受欢迎.统计时列举出得分较高的前几位, 如图3所示. 陈心希 周杰伦 3.2答案抽取实验 答案抽取实验在前面的基于组块识别的CRF分 图2比较对象的支持度统计结果 Fig.2 Support comparison statistics 类实验的基础上进行.本文采用TREC QA的MRR (mean reciprocal of rank)评测标准,公式如下: 回支持度 M=1分1 n T Ti 其中:M为MRR值,n为所有测试问题的数量,对 网 每个问题,给出5个答案,T:为第i个问题的第一个 正确答案的位置.对于事实类和原因类的每个问题, 察依政孙燕姿王心楼©a张韶涵蔡卓谢刘光英张柏芝 从文档中返回5个答案;而评价类,比较类和是否类 图3列举对象的支持度统计结果 则从问题集中返回相似度最大的前5个问题.若5 Fig.3 Support comparison of enumeration objects 个答案都不正确,则1/:取值为0.表7是答案抽取 实验结果 表7答案抽取实验结果 Table 7 Answer extraction results 问题类型 问题测试数 分类准确数 答案排在第1位 答案排在前5位 公 事实类 70 61 45 50 0.679 原因类 33 32 20 26 0.684 比较类 36 36 18 33 0.704 是否类 53 阳 32 42 0.686 评价类 90 81 54 70 0.681 由表7可知事实类问题的答案抽取结果比较 众对其的情感作为研究对象.在所搜集的情感问题 低,一方面由于分类实验中将其错误地分到了其他 语料的基础上,根据问题的特点,归纳了五大情感问 类别当中,特别是将其分成了评价类;由于这两种问 题类型.由于情感问题的特殊性,本文利用基于组块 题的答案抽取的方式存在根本的不同,导致得到了 思想的CRF模型结合一定的规则和语义情感资源 错误的答案.另一方面,通过组块识别所获得的问题 对情感问题进行分类,其缺陷是需要大量的手工标 焦点极大地缩小了候选答案的范围,但是其严格的 注.在答案抽取时结合了组块识别的结果和情感的 限制可能使得漏掉正确答案.因此本文应用哈工大 倾向性,并根据情感问题类型的不同采取了不同的 的《同义词词林(扩展版)》对问题的焦点名词进行 策略以获取答案.下一步工作需要扩大情感问题的 扩充来提高答案抽取的召回率.比较类中多个人名 语料,丰富问题类型,以便在问题分析时获得更多的 的限制提高了答案抽取的准确度,但人名识别的准 特征.另外也需要结合更多的情感倾向性知识来指 确度将严重制约答案的抽取.另外,部分错误还来自 导答案的抽取, 于句子倾向性识别, 参考文献: 4结束语 [1]CARDIE C,WIEBE J,LITMAN D,et al.Combining low- 本文从百度知道这个丰富的知识库中人工搜集 level and summary representations of opinions for multi-per- 了大量的情感问题,以娱乐焦点人物的喜好以及大 spective question answering C]//Proceedings of AAAI