正在加载图片...
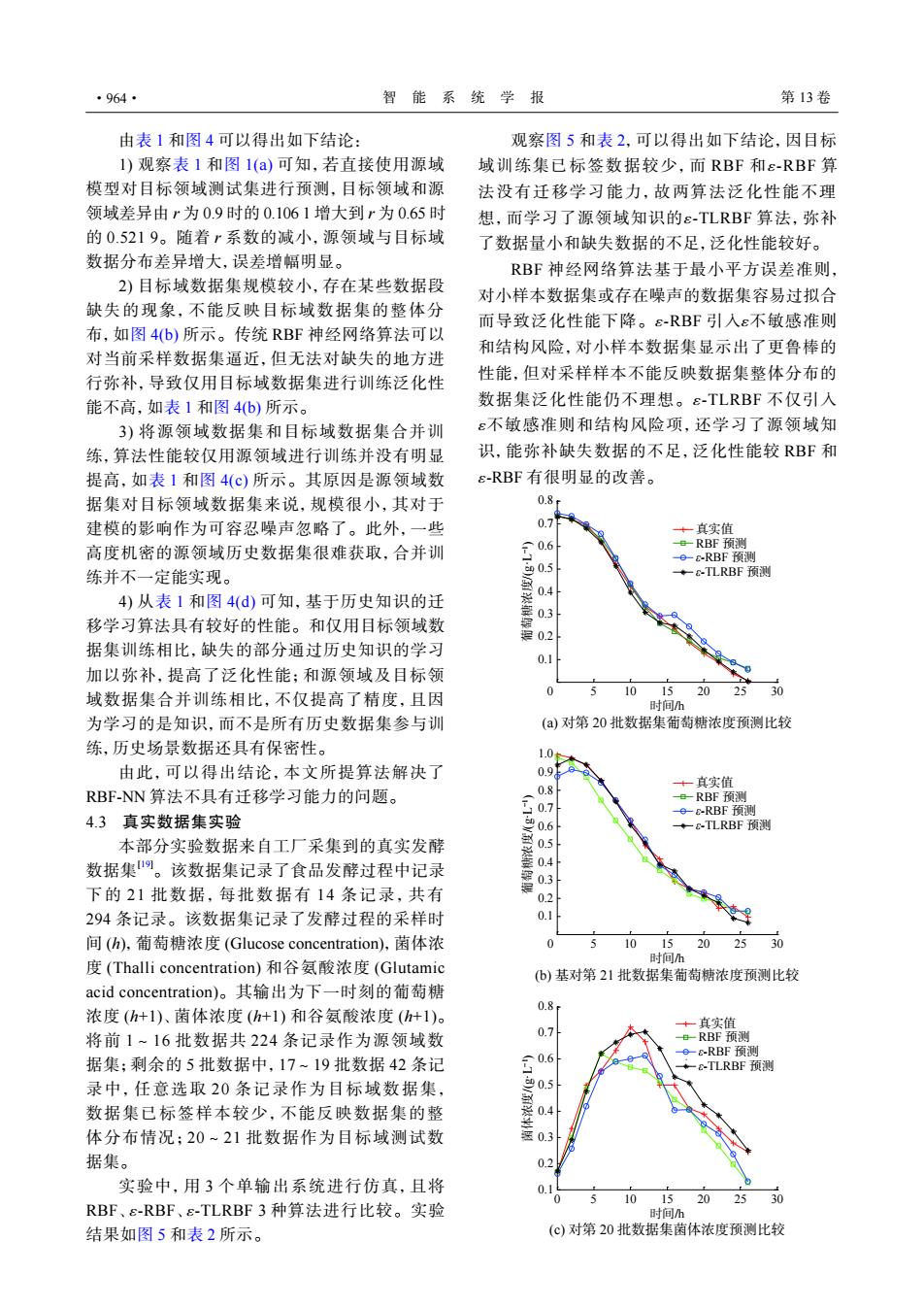
·964· 智能系统学报 第13卷 由表1和图4可以得出如下结论: 观察图5和表2,可以得出如下结论,因目标 1)观察表1和图1(a)可知,若直接使用源域 域训练集已标签数据较少,而RBF和ε-RBF算 模型对目标领域测试集进行预测,目标领域和源 法没有迁移学习能力,故两算法泛化性能不理 领域差异由r为0.9时的0.1061增大到r为0.65时 想,而学习了源领域知识的ε-TLRBF算法,弥补 的0.5219。随着r系数的减小,源领域与目标域 了数据量小和缺失数据的不足,泛化性能较好。 数据分布差异增大,误差增幅明显。 RBF神经网络算法基于最小平方误差准则, 2)目标域数据集规模较小,存在某些数据段 对小样本数据集或存在噪声的数据集容易过拟合 缺失的现象,不能反映目标域数据集的整体分 而导致泛化性能下降。E-RBF引入ε不敏感准则 布,如图4(b)所示。传统RBF神经网络算法可以 对当前采样数据集逼近,但无法对缺失的地方进 和结构风险,对小样本数据集显示出了更鲁棒的 行弥补,导致仅用目标域数据集进行训练泛化性 性能,但对采样样本不能反映数据集整体分布的 能不高,如表1和图4(b)所示。 数据集泛化性能仍不理想。ε-TLRBF不仅引入 3)将源领域数据集和目标域数据集合并训 ε不敏感准则和结构风险项,还学习了源领域知 练,算法性能较仅用源领域进行训练并没有明显 识,能弥补缺失数据的不足,泛化性能较RBF和 提高,如表1和图4(c)所示。其原因是源领域数 ERBF有很明显的改善。 据集对目标领域数据集来说,规模很小,其对于 0.8r 建模的影响作为可容忍噪声忽略了。此外,一些 0.71 +真实值 高度机密的源领域历史数据集很难获取,合并训 06 e-RBF预测 e-8-RBF预测 练并不一定能实现。 90.5 ◆a-TLRBF预测 0.4 4)从表1和图4(d)可知,基于历史知识的迁 移学习算法具有较好的性能。和仅用目标领域数 0.2 据集训练相比,缺失的部分通过历史知识的学习 0.1 加以弥补,提高了泛化性能:和源领域及目标领 域数据集合并训练相比,不仅提高了精度,且因 10 1520 25 30 时间h 为学习的是知识,而不是所有历史数据集参与训 (a)对第20批数据集葡萄糖浓度预测比较 练,历史场景数据还具有保密性。 1.0 由此,可以得出结论,本文所提算法解决了 0.98 RBF-NN算法不具有迁移学习能力的问题。 0.8 +真实值 4.3真实数据集实验 501 e-RBF预测 e&-RBF预测 0.6 +&TLRBF预测 本部分实验数据来自工厂采集到的真实发酵 数据集四。该数据集记录了食品发酵过程中记录 下的21批数据,每批数据有14条记录,共有 0.2 294条记录。该数据集记录了发酵过程的采样时 0.1 间(h),葡萄糖浓度(Glucose concentration),菌体浓 1015202530 时间h 度(Thalli concentration)和谷氨酸浓度(Glutamic (b)基对第21批数据集葡萄糖浓度预测比较 acid concentration)。其输出为下一时刻的葡萄糖 浓度(h+1)、菌体浓度(h+1)和谷氨酸浓度(h+1)。 0.8 +真实值 将前1~16批数据共224条记录作为源领域数 0.7 -RBF预测 e-&-RBF预测 据集;剩余的5批数据中,17~19批数据42条记 0.6 8-TLRBF预测 录中,任意选取20条记录作为目标域数据集, 数据集已标签样本较少,不能反映数据集的整 0.4 体分布情况;20~21批数据作为目标域测试数 蓝0.3 据集。 02 实验中,用3个单输出系统进行仿真,且将 0.1 0 5 1015202530 RBF、E-RBF、E-TLRBF3种算法进行比较。实验 时间h 结果如图5和表2所示。 (©)对第20批数据集菌体浓度预测比较由表 1 和图 4 可以得出如下结论: 1) 观察表 1 和图 1(a) 可知,若直接使用源域 模型对目标领域测试集进行预测,目标领域和源 领域差异由 r 为 0.9 时的 0.106 1 增大到 r 为 0.65 时 的 0.521 9。随着 r 系数的减小,源领域与目标域 数据分布差异增大,误差增幅明显。 2) 目标域数据集规模较小,存在某些数据段 缺失的现象,不能反映目标域数据集的整体分 布,如图 4(b) 所示。传统 RBF 神经网络算法可以 对当前采样数据集逼近,但无法对缺失的地方进 行弥补,导致仅用目标域数据集进行训练泛化性 能不高,如表 1 和图 4(b) 所示。 3) 将源领域数据集和目标域数据集合并训 练,算法性能较仅用源领域进行训练并没有明显 提高,如表 1 和图 4(c) 所示。其原因是源领域数 据集对目标领域数据集来说,规模很小,其对于 建模的影响作为可容忍噪声忽略了。此外,一些 高度机密的源领域历史数据集很难获取,合并训 练并不一定能实现。 4) 从表 1 和图 4(d) 可知,基于历史知识的迁 移学习算法具有较好的性能。和仅用目标领域数 据集训练相比,缺失的部分通过历史知识的学习 加以弥补,提高了泛化性能;和源领域及目标领 域数据集合并训练相比,不仅提高了精度,且因 为学习的是知识,而不是所有历史数据集参与训 练,历史场景数据还具有保密性。 由此,可以得出结论,本文所提算法解决了 RBF-NN 算法不具有迁移学习能力的问题。 4.3 真实数据集实验 本部分实验数据来自工厂采集到的真实发酵 数据集[19]。该数据集记录了食品发酵过程中记录 下的 21 批数据,每批数据有 14 条记录,共有 294 条记录。该数据集记录了发酵过程的采样时 间 (h),葡萄糖浓度 (Glucose concentration),菌体浓 度 (Thalli concentration) 和谷氨酸浓度 (Glutamic acid concentration)。其输出为下一时刻的葡萄糖 浓度 (h+1)、菌体浓度 (h+1) 和谷氨酸浓度 (h+1)。 将前 1~16 批数据共 224 条记录作为源领域数 据集;剩余的 5 批数据中,17~19 批数据 42 条记 录中,任意选取 20 条记录作为目标域数据集, 数据集已标签样本较少,不能反映数据集的整 体分布情况;20~21 批数据作为目标域测试数 据集。 ε ε 实验中,用 3 个单输出系统进行仿真,且将 RBF、 -RBF、 -TLRBF 3 种算法进行比较。实验 结果如图 5 和表 2 所示。 ε ε 观察图 5 和表 2,可以得出如下结论,因目标 域训练集已标签数据较少,而 RBF 和 -RBF 算 法没有迁移学习能力,故两算法泛化性能不理 想,而学习了源领域知识的 -TLRBF 算法,弥补 了数据量小和缺失数据的不足,泛化性能较好。 ε ε ε ε ε RBF 神经网络算法基于最小平方误差准则, 对小样本数据集或存在噪声的数据集容易过拟合 而导致泛化性能下降。 -RBF 引入 不敏感准则 和结构风险,对小样本数据集显示出了更鲁棒的 性能,但对采样样本不能反映数据集整体分布的 数据集泛化性能仍不理想。 -TLRBF 不仅引入 不敏感准则和结构风险项,还学习了源领域知 识,能弥补缺失数据的不足,泛化性能较 RBF 和 -RBF 有很明显的改善。 (a) 对第 20 批数据集葡萄糖浓度预测比较 (b) 基对第 21 批数据集葡萄糖浓度预测比较 (c) 对第 20 批数据集菌体浓度预测比较 0 5 10 15 20 25 30 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 时间/h 0 5 10 15 20 25 30 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 时间/h 0 5 10 15 20 25 30 时间/h 葡萄糖浓度/(g·L−1 ) 真实值 RBF 预测 ε-RBF 预测 ε-TLRBF 预测 真实值 RBF 预测 ε-RBF 预测 ε-TLRBF 预测 真实值 RBF 预测 ε-RBF 预测 ε-TLRBF 预测 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 葡萄糖浓度/(g·L−1 ) 菌体浓度/(g·L−1 ) ·964· 智 能 系 统 学 报 第 13 卷