正在加载图片...
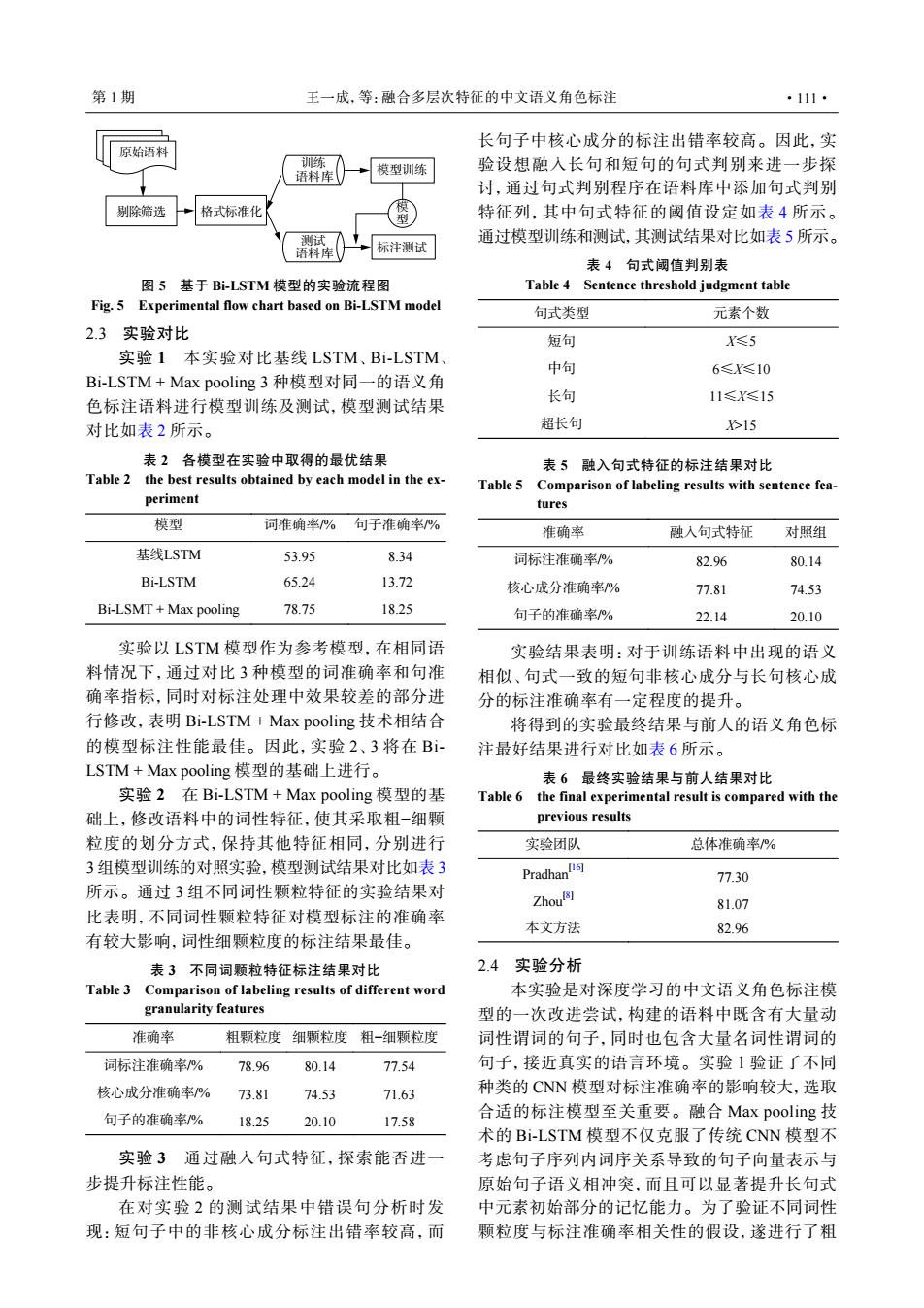
第1期 王一成,等:融合多层次特征的中文语义角色标注 ·111 长句子中核心成分的标注出错率较高。因此,实 原始语料 训练 验设想融入长句和短句的句式判别来进一步探 语料库 模型训练 讨,通过句式判别程序在语料库中添加句式判别 剔除筛选 格式标准化 型 特征列,其中句式特征的阈值设定如表4所示。 测试 通过模型训练和测试,其测试结果对比如表5所示。 语料库 标注测试 表4句式阈值判别表 图5基于Bi-LSTM模型的实验流程图 Table 4 Sentence threshold judgment table Fig.5 Experimental flow chart based on Bi-LSTM model 句式类型 元素个数 2.3实验对比 短句 X≤5 实验1本实验对比基线LSTM、Bi-LSTM、 中句 6≤X≤10 Bi-LSTM+Max pooling3种模型对同一的语义角 色标注语料进行模型训练及测试,模型测试结果 长句 11≤X≤15 对比如表2所示。 超长句 X15 表2各模型在实验中取得的最优结果 表5融入句式特征的标注结果对比 Table 2 the best results obtained by each model in the ex- Table 5 Comparison of labeling results with sentence fea- periment tures 模型 词准确率%句子准确率% 准确率 融入句式特征 对照组 基线LSTM 53.95 8.34 词标注准确率/% 82.96 80.14 Bi-LSTM 65.24 13.72 核心成分准确率% 77.81 74.53 Bi-LSMT Max pooling 78.75 18.25 句子的准确率% 22.14 20.10 实验以LSTM模型作为参考模型,在相同语 实验结果表明:对于训练语料中出现的语义 料情况下,通过对比3种模型的词准确率和句准 相似、句式一致的短句非核心成分与长句核心成 确率指标,同时对标注处理中效果较差的部分进 分的标注准确率有一定程度的提升。 行修改,表明Bi-LSTM+Max pooling技术相结合 将得到的实验最终结果与前人的语义角色标 的模型标注性能最佳。因此,实验2、3将在Bi- 注最好结果进行对比如表6所示。 LSTM+Max pooling模型的基础上进行。 表6最终实验结果与前人结果对比 实验2在Bi-LSTM+Max pooling模型的基 Table 6 the final experimental result is compared with the 础上,修改语料中的词性特征,使其采取粗-细颗 previous results 粒度的划分方式,保持其他特征相同,分别进行 实验团队 总体准确率/% 3组模型训练的对照实验,模型测试结果对比如表3 Pradhan 77.30 所示。通过3组不同词性颗粒特征的实验结果对 Zhou图 81.07 比表明,不同词性颗粒特征对模型标注的准确率 本文方法 82.96 有较大影响,词性细颗粒度的标注结果最佳。 表3不同词颗粒特征标注结果对比 2.4 实验分析 Table 3 Comparison of labeling results of different word 本实验是对深度学习的中文语义角色标注模 granularity features 型的一次改进尝试,构建的语料中既含有大量动 准确率 粗颗粒度细颗粒度粗-细颗粒度 词性谓词的句子,同时也包含大量名词性谓词的 词标注准确率% 78.96 80.14 77.54 句子,接近真实的语言环境。实验1验证了不同 核心成分准确率% 73.81 74.53 71.63 种类的CNN模型对标注准确率的影响较大,选取 句子的准确率% 合适的标注模型至关重要。融合Max pooling技 18.25 20.10 17.58 术的Bi-LSTM模型不仅克服了传统CNN模型不 实验3通过融入句式特征,探索能否进一 考虑句子序列内词序关系导致的句子向量表示与 步提升标注性能。 原始句子语义相冲突,而且可以显著提升长句式 在对实验2的测试结果中错误句分析时发 中元素初始部分的记忆能力。为了验证不同词性 现:短句子中的非核心成分标注出错率较高,而 颗粒度与标注准确率相关性的假设,遂进行了粗原始语料 训练 语料库 测试 语料库 剔除筛选 格式标准化 模型训练 模 型 标注测试 图 5 基于 Bi-LSTM 模型的实验流程图 Fig. 5 Experimental flow chart based on Bi-LSTM model 2.3 实验对比 实验 1 本实验对比基线 LSTM、Bi-LSTM、 Bi-LSTM + Max pooling 3 种模型对同一的语义角 色标注语料进行模型训练及测试,模型测试结果 对比如表 2 所示。 表 2 各模型在实验中取得的最优结果 Table 2 the best results obtained by each model in the experiment 模型 词准确率/% 句子准确率/% 基线LSTM 53.95 8.34 Bi-LSTM 65.24 13.72 Bi-LSMT + Max pooling 78.75 18.25 实验以 LSTM 模型作为参考模型,在相同语 料情况下,通过对比 3 种模型的词准确率和句准 确率指标,同时对标注处理中效果较差的部分进 行修改,表明 Bi-LSTM + Max pooling 技术相结合 的模型标注性能最佳。因此,实验 2、3 将在 BiLSTM + Max pooling 模型的基础上进行。 实验 2 在 Bi-LSTM + Max pooling 模型的基 础上,修改语料中的词性特征,使其采取粗−细颗 粒度的划分方式,保持其他特征相同,分别进行 3 组模型训练的对照实验,模型测试结果对比如表 3 所示。通过 3 组不同词性颗粒特征的实验结果对 比表明,不同词性颗粒特征对模型标注的准确率 有较大影响,词性细颗粒度的标注结果最佳。 表 3 不同词颗粒特征标注结果对比 Table 3 Comparison of labeling results of different word granularity features 准确率 粗颗粒度 细颗粒度 粗−细颗粒度 词标注准确率/% 78.96 80.14 77.54 核心成分准确率/% 73.81 74.53 71.63 句子的准确率/% 18.25 20.10 17.58 实验 3 通过融入句式特征,探索能否进一 步提升标注性能。 在对实验 2 的测试结果中错误句分析时发 现:短句子中的非核心成分标注出错率较高,而 长句子中核心成分的标注出错率较高。因此,实 验设想融入长句和短句的句式判别来进一步探 讨,通过句式判别程序在语料库中添加句式判别 特征列,其中句式特征的阈值设定如表 4 所示。 通过模型训练和测试,其测试结果对比如表 5 所示。 表 4 句式阈值判别表 Table 4 Sentence threshold judgment table 句式类型 元素个数 短句 X≤5 中句 6≤X≤10 长句 11≤X≤15 超长句 X>15 表 5 融入句式特征的标注结果对比 Table 5 Comparison of labeling results with sentence features 准确率 融入句式特征 对照组 词标注准确率/% 82.96 80.14 核心成分准确率/% 77.81 74.53 句子的准确率/% 22.14 20.10 实验结果表明:对于训练语料中出现的语义 相似、句式一致的短句非核心成分与长句核心成 分的标注准确率有一定程度的提升。 将得到的实验最终结果与前人的语义角色标 注最好结果进行对比如表 6 所示。 表 6 最终实验结果与前人结果对比 Table 6 the final experimental result is compared with the previous results 实验团队 总体准确率/% Pradhan[16] 77.30 Zhou[8] 81.07 本文方法 82.96 2.4 实验分析 本实验是对深度学习的中文语义角色标注模 型的一次改进尝试,构建的语料中既含有大量动 词性谓词的句子,同时也包含大量名词性谓词的 句子,接近真实的语言环境。实验 1 验证了不同 种类的 CNN 模型对标注准确率的影响较大,选取 合适的标注模型至关重要。融合 Max pooling 技 术的 Bi-LSTM 模型不仅克服了传统 CNN 模型不 考虑句子序列内词序关系导致的句子向量表示与 原始句子语义相冲突,而且可以显著提升长句式 中元素初始部分的记忆能力。为了验证不同词性 颗粒度与标注准确率相关性的假设,遂进行了粗 第 1 期 王一成,等:融合多层次特征的中文语义角色标注 ·111·