正在加载图片...
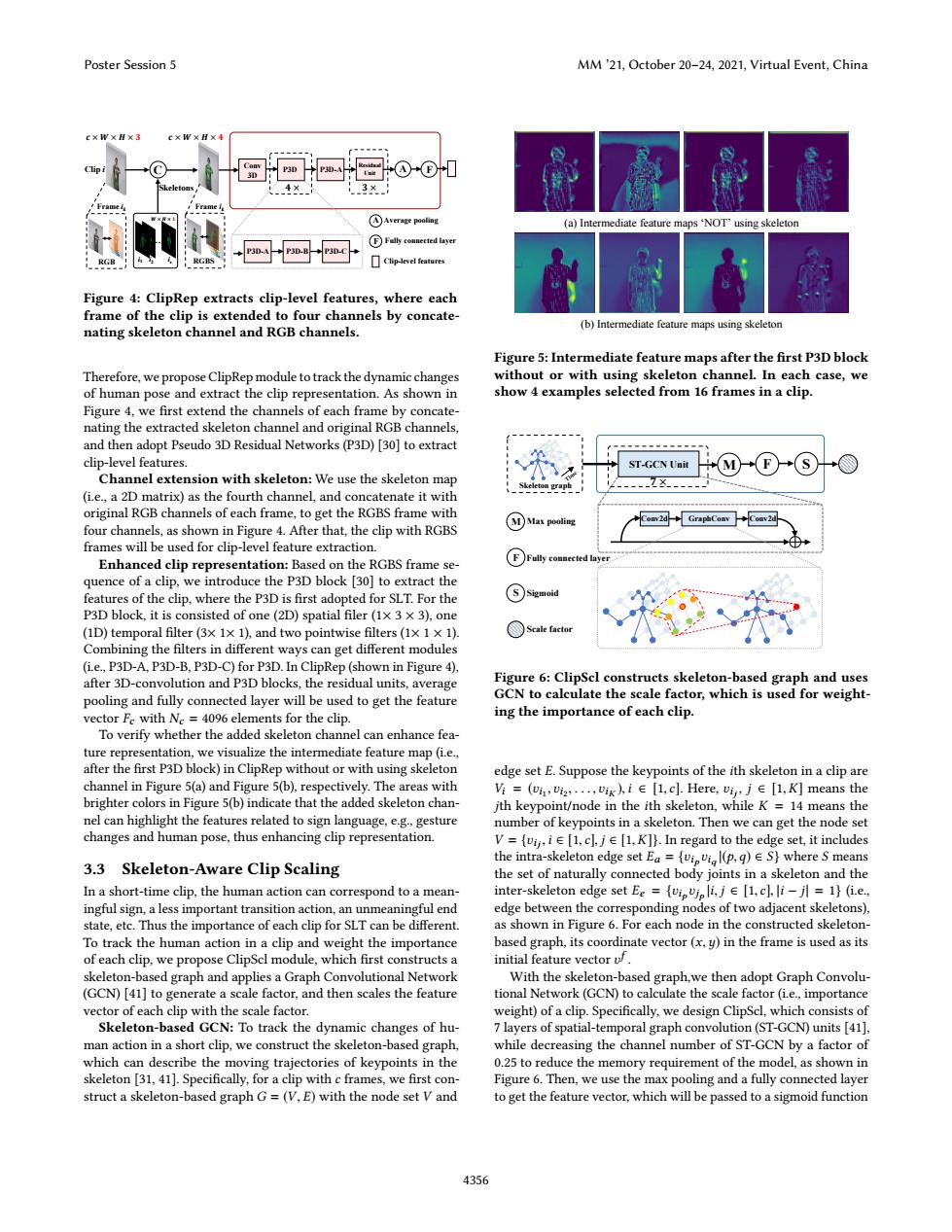
Poster Session 5 MM'21,October 20-24,2021,Virtual Event,China AAverage pooling (a)Intermediate feature maps 'NOT'using skeleton ⑥Fally conected layer Clip-level features Figure 4:ClipRep extracts clip-level features,where each frame of the clip is extended to four channels by concate- nating skeleton channel and RGB channels. (b)Intermediate feature maps using skeleton Figure 5:Intermediate feature maps after the first P3D block Therefore,we propose ClipRep module to track the dynamic changes without or with using skeleton channel.In each case,we of human pose and extract the clip representation.As shown in show 4 examples selected from 16 frames in a clip. Figure 4,we first extend the channels of each frame by concate- nating the extracted skeleton channel and original RGB channels, and then adopt Pseudo 3D Residual Networks(P3D)[30]to extract clip-level features. ST-GCN Unit Channel extension with skeleton:We use the skeleton map (i.e.,a 2D matrix)as the fourth channel,and concatenate it with original RGB channels of each frame,to get the RGBS frame with M)Max pooling four channels,as shown in Figure 4.After that,the clip with RGBS frames will be used for clip-level feature extraction. Enhanced clip representation:Based on the RGBS frame se- quence of a clip,we introduce the P3D block [30]to extract the features of the clip,where the P3D is first adopted for SLT.For the P3D block,it is consisted of one(2D)spatial filer(1x 3 x 3),one (1D)temporal filter(3x1×1),and two pointwise filters(1×1×1) Combining the filters in different ways can get different modules (i.e.,P3D-A,P3D-B,P3D-C)for P3D.In ClipRep(shown in Figure 4), after 3D-convolution and P3D blocks,the residual units,average Figure 6:ClipScl constructs skeleton-based graph and uses pooling and fully connected layer will be used to get the feature GCN to calculate the scale factor,which is used for weight- vector Fc with Ne 4096 elements for the clip. ing the importance of each clip. To verify whether the added skeleton channel can enhance fea- ture representation,we visualize the intermediate feature map(i.e.. after the first P3D block)in ClipRep without or with using skeleton edge set E.Suppose the keypoints of the ith skeleton in a clip are channel in Figure 5(a)and Figure 5(b),respectively.The areas with =(wi,i2,,vik,i∈[1,cl.Here,vi,j∈[l,K]means the brighter colors in Figure 5(b)indicate that the added skeleton chan- jth keypoint/node in the ith skeleton,while K =14 means the nel can highlight the features related to sign language,e.g.,gesture number of keypoints in a skeleton.Then we can get the node set changes and human pose,thus enhancing clip representation. V=(vi,ie[1,cl.je[1,K]).In regard to the edge set,it includes the intra-skeleton edge set Ea =vipvil(p.q)ES)where S means 3.3 Skeleton-Aware Clip Scaling the set of naturally connected body joints in a skeleton and the In a short-time clip,the human action can correspond to a mean- inter-skeleton edge set Ee =(vipvjp li.j [1.c].li-jl =1)(i.e.. ingful sign,a less important transition action,an unmeaningful end edge between the corresponding nodes of two adjacent skeletons), state,etc.Thus the importance of each clip for SLT can be different. as shown in Figure 6.For each node in the constructed skeleton- To track the human action in a clip and weight the importance based graph,its coordinate vector (x,y)in the frame is used as its of each clip,we propose ClipScl module,which first constructs a initial feature vector skeleton-based graph and applies a Graph Convolutional Network With the skeleton-based graph,we then adopt Graph Convolu- (GCN)[41]to generate a scale factor,and then scales the feature tional Network(GCN)to calculate the scale factor(ie.,importance vector of each clip with the scale factor. weight)of a clip.Specifically,we design ClipScl,which consists of Skeleton-based GCN:To track the dynamic changes of hu- 7 layers of spatial-temporal graph convolution(ST-GCN)units [41]. man action in a short clip,we construct the skeleton-based graph, while decreasing the channel number of ST-GCN by a factor of which can describe the moving trajectories of keypoints in the 0.25 to reduce the memory requirement of the model,as shown in skeleton [31,41].Specifically,for a clip with c frames,we first con- Figure 6.Then,we use the max pooling and a fully connected layer struct a skeleton-based graph G=(V,E)with the node set V and to get the feature vector,which will be passed to a sigmoid function 4356Clip i 𝒄𝒄 × 𝑾𝑾 × 𝑯𝑯 × 𝟑𝟑 … 𝑾𝑾 × 𝑯𝑯 × 𝟏𝟏 i1 i2 ic C 𝒄𝒄 × 𝑾𝑾 × 𝑯𝑯 × 𝟒𝟒 Conv 3D P3D P3D-A 𝟒𝟒 × Residual Unit 𝟑𝟑 × A F Frame i Frame k ik RGB RGBS Fully connected layer Average pooling Clip-level features Skeletons P3D-A P3D-B P3D-C F A Figure 4: ClipRep extracts clip-level features, where each frame of the clip is extended to four channels by concatenating skeleton channel and RGB channels. Therefore, we propose ClipRep module to track the dynamic changes of human pose and extract the clip representation. As shown in Figure 4, we first extend the channels of each frame by concatenating the extracted skeleton channel and original RGB channels, and then adopt Pseudo 3D Residual Networks (P3D) [30] to extract clip-level features. Channel extension with skeleton: We use the skeleton map (i.e., a 2D matrix) as the fourth channel, and concatenate it with original RGB channels of each frame, to get the RGBS frame with four channels, as shown in Figure 4. After that, the clip with RGBS frames will be used for clip-level feature extraction. Enhanced clip representation: Based on the RGBS frame sequence of a clip, we introduce the P3D block [30] to extract the features of the clip, where the P3D is first adopted for SLT. For the P3D block, it is consisted of one (2D) spatial filer (1× 3 × 3), one (1D) temporal filter (3× 1× 1), and two pointwise filters (1× 1 × 1). Combining the filters in different ways can get different modules (i.e., P3D-A, P3D-B, P3D-C) for P3D. In ClipRep (shown in Figure 4), after 3D-convolution and P3D blocks, the residual units, average pooling and fully connected layer will be used to get the feature vector Fc with Nc = 4096 elements for the clip. To verify whether the added skeleton channel can enhance feature representation, we visualize the intermediate feature map (i.e., after the first P3D block) in ClipRep without or with using skeleton channel in Figure 5(a) and Figure 5(b), respectively. The areas with brighter colors in Figure 5(b) indicate that the added skeleton channel can highlight the features related to sign language, e.g., gesture changes and human pose, thus enhancing clip representation. 3.3 Skeleton-Aware Clip Scaling In a short-time clip, the human action can correspond to a meaningful sign, a less important transition action, an unmeaningful end state, etc. Thus the importance of each clip for SLT can be different. To track the human action in a clip and weight the importance of each clip, we propose ClipScl module, which first constructs a skeleton-based graph and applies a Graph Convolutional Network (GCN) [41] to generate a scale factor, and then scales the feature vector of each clip with the scale factor. Skeleton-based GCN: To track the dynamic changes of human action in a short clip, we construct the skeleton-based graph, which can describe the moving trajectories of keypoints in the skeleton [31, 41]. Specifically, for a clip with c frames, we first construct a skeleton-based graph G = (V, E) with the node set V and (a) Intermediate feature maps ‘NOT’ using skeleton (b) Intermediate feature maps using skeleton Figure 5: Intermediate feature maps after the first P3D block without or with using skeleton channel. In each case, we show 4 examples selected from 16 frames in a clip. ST-GCN Unit M F S 𝟕𝟕 × Conv2d GraphConv Conv2d Fully connected layer Max pooling F M S Sigmoid Scale factor Skeleton graph Figure 6: ClipScl constructs skeleton-based graph and uses GCN to calculate the scale factor, which is used for weighting the importance of each clip. edge set E. Suppose the keypoints of the ith skeleton in a clip are Vi = (υi1 ,υi2 , . . . ,υiK ),i ∈ [1,c]. Here, υij , j ∈ [1,K] means the jth keypoint/node in the ith skeleton, while K = 14 means the number of keypoints in a skeleton. Then we can get the node set V = {υij ,i ∈ [1,c], j ∈ [1,K]}. In regard to the edge set, it includes the intra-skeleton edge set Ea = {υip υiq |(p, q) ∈ S} where S means the set of naturally connected body joints in a skeleton and the inter-skeleton edge set Ee = {υip υjp |i, j ∈ [1,c], |i − j| = 1} (i.e., edge between the corresponding nodes of two adjacent skeletons), as shown in Figure 6. For each node in the constructed skeletonbased graph, its coordinate vector (x,y) in the frame is used as its initial feature vector υ f . With the skeleton-based graph,we then adopt Graph Convolutional Network (GCN) to calculate the scale factor (i.e., importance weight) of a clip. Specifically, we design ClipScl, which consists of 7 layers of spatial-temporal graph convolution (ST-GCN) units [41], while decreasing the channel number of ST-GCN by a factor of 0.25 to reduce the memory requirement of the model, as shown in Figure 6. Then, we use the max pooling and a fully connected layer to get the feature vector, which will be passed to a sigmoid function Poster Session 5 MM ’21, October 20–24, 2021, Virtual Event, China 4356