正在加载图片...
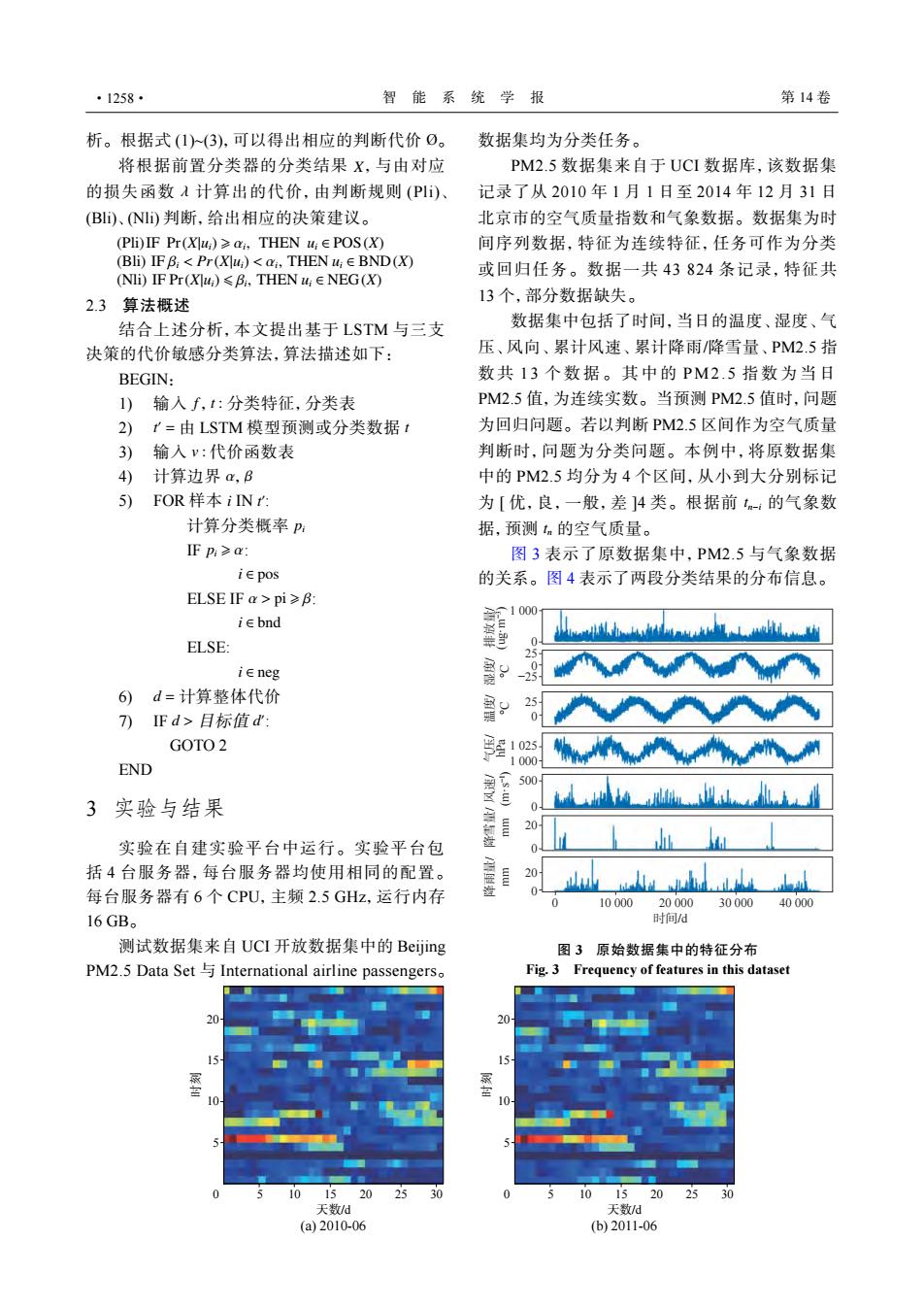
·1258· 智能系统学报 第14卷 析。根据式(1)(3),可以得出相应的判断代价O。 数据集均为分类任务。 将根据前置分类器的分类结果X,与由对应 PM2.5数据集来自于UCI数据库,该数据集 的损失函数A计算出的代价,由判断规则(PI)、 记录了从2010年1月1日至2014年12月31日 (Bl)、ND判断,给出相应的决策建议。 北京市的空气质量指数和气象数据。数据集为时 (PIi)FPr(Xu)≥a,THEN 1,∈POS(X) 间序列数据,特征为连续特征,任务可作为分类 (Bli)IF B:Pr(Xlu)<ai,THEN u;E BND(X) (Ni)FPr(XW)≤B,THEN:∈NEG(X) 或回归任务。数据一共43824条记录,特征共 2.3算法概述 13个,部分数据缺失。 结合上述分析,本文提出基于LSTM与三支 数据集中包括了时间,当日的温度、湿度、气 决策的代价敏感分类算法,算法描述如下: 压、风向、累计风速、累计降雨/降雪量、PM2.5指 BEGIN: 数共13个数据。其中的PM2.5指数为当日 1)输入f,t:分类特征,分类表 PM2.5值,为连续实数。当预测PM2.5值时,问题 2)1=由LSTM模型预测或分类数据t 为回归问题。若以判断PM2.5区间作为空气质量 3) 输入v:代价函数表 判断时,问题为分类问题。本例中,将原数据集 4) 计算边界a,B 中的PM2.5均分为4个区间,从小到大分别标记 5) FOR样本iN: 为[优,良,一般,差]4类。根据前n-:的气象数 计算分类概率p 据,预测tm的空气质量。 IFp:≥a: 图3表示了原数据集中,PM2.5与气象数据 i∈pos 的关系。图4表示了两段分类结果的分布信息。 ELSE IF a>pi≥B: iEbnd ELSE: ie neg 6)d=计算整体代价 )Fd>目标值d': GOTO 2 1000 END 500 3实验与结果 20 实验在自建实验平台中运行。实验平台包 括4台服务器,每台服务器均使用相同的配置。 20 每台服务器有6个CPU,主频2.5GHz,运行内存 10000 20000 30000 40000 16GB。 时间/d 测试数据集来自UCI开放数据集中的Beijing 图3原始数据集中的特征分布 PM2.5 Data Set International airline passengerso Fig.3 Frequency of features in this dataset 20 101520 25 30 10152025 30 天数/d 天数/d (a)2010-06 (b)2011-06析。根据式 (1)~(3),可以得出相应的判断代价 Ø。 X λ 将根据前置分类器的分类结果 ,与由对应 的损失函数 计算出的代价,由判断规则 (Pli)、 (Bli)、(Nli) 判断,给出相应的决策建议。 (Pli)IF Pr(X|ui) ⩾ αi , THEN ui ∈ POS(X) (Bli) IF βi < Pr(X|ui) < αi , THEN ui ∈ BND(X) (Nli) IF Pr(X|ui) ⩽ βi , THEN ui ∈ NEG(X) 2.3 算法概述 结合上述分析,本文提出基于 LSTM 与三支 决策的代价敏感分类算法,算法描述如下: BEGIN: 1) 输入 f ,t : 分类特征,分类表 t ′ 2) = 由 LSTM 模型预测或分类数据 t 3) 输入 v : 代价函数表 4) 计算边界 α,β i t ′ 5) FOR 样本 IN : 计算分类概率 pi IF : pi ⩾ α i ∈ pos ELSE IF : α > pi ⩾ β i ∈ bnd ELSE: i ∈ neg 6) d = 计算整体代价 d > d ′ 7) IF 目标值 : GOTO 2 END 3 实验与结果 实验在自建实验平台中运行。实验平台包 括 4 台服务器,每台服务器均使用相同的配置。 每台服务器有 6 个 CPU,主频 2.5 GHz,运行内存 16 GB。 测试数据集来自 UCI 开放数据集中的 Beijing PM2.5 Data Set 与 International airline passengers。 数据集均为分类任务。 PM2.5 数据集来自于 UCI 数据库,该数据集 记录了从 2010 年 1 月 1 日至 2014 年 12 月 31 日 北京市的空气质量指数和气象数据。数据集为时 间序列数据,特征为连续特征,任务可作为分类 或回归任务。数据一共 43 824 条记录,特征共 13 个,部分数据缺失。 tn−i tn 数据集中包括了时间,当日的温度、湿度、气 压、风向、累计风速、累计降雨/降雪量、PM2.5 指 数 共 1 3 个数据。其中 的 PM2. 5 指数为当 日 PM2.5 值,为连续实数。当预测 PM2.5 值时,问题 为回归问题。若以判断 PM2.5 区间作为空气质量 判断时,问题为分类问题。本例中,将原数据集 中的 PM2.5 均分为 4 个区间,从小到大分别标记 为 [ 优,良,一般,差 ]4 类。根据前 的气象数 据,预测 的空气质量。 图 3 表示了原数据集中,PM2.5 与气象数据 的关系。图 4 表示了两段分类结果的分布信息。 0 10 000 20 000 30 000 40 000 时间/d 1 000 0 25 25 1 025 1 000 500 20 20 0 0 0 风速/ (m·s−1 ) 降雪量/ mm 降雨量/ mm −25 0 0 排放量/ (ug·m−3 ) 湿度/ °C 温度/ °C 气压/ hPa 图 3 原始数据集中的特征分布 Fig. 3 Frequency of features in this dataset 20 15 10 5 0 5 10 15 20 25 30 时刻 天数/d 20 15 10 5 0 5 10 15 20 25 30 时刻 天数/d (a) 2010-06 (b) 2011-06 ·1258· 智 能 系 统 学 报 第 14 卷