正在加载图片...
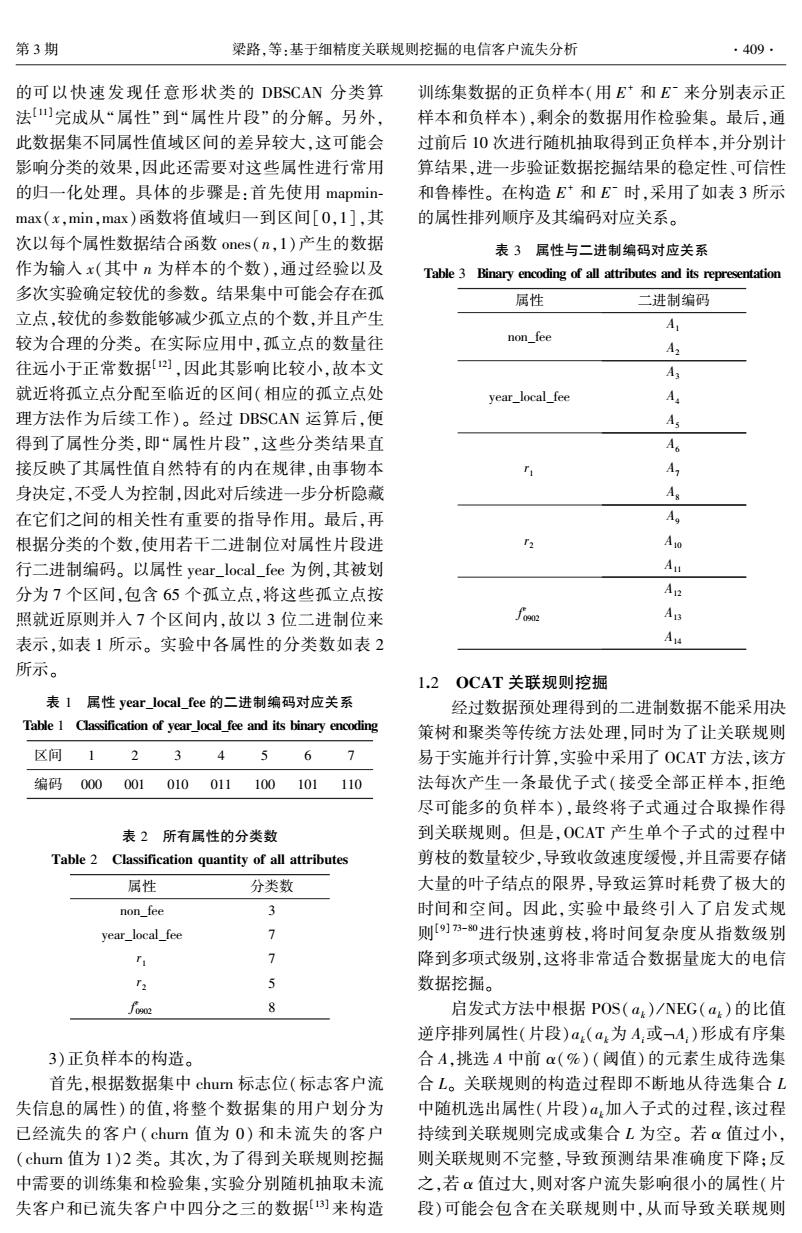
第3期 梁路,等:基于细精度关联规则挖掘的电信客户流失分析 ·409 的可以快速发现任意形状类的DBSCAN分类算 训练集数据的正负样本(用E*和E来分别表示正 法[四完成从“属性”到“属性片段”的分解。另外, 样本和负样本),剩余的数据用作检验集。最后,通 此数据集不同属性值域区间的差异较大,这可能会 过前后10次进行随机抽取得到正负样本,并分别计 影响分类的效果,因此还需要对这些属性进行常用 算结果,进一步验证数据挖掘结果的稳定性、可信性 的归一化处理。具体的步骤是:首先使用mapmin- 和鲁棒性。在构造E和E时,采用了如表3所示 max(x,min,max)函数将值域归一到区间[0,1],其 的属性排列顺序及其编码对应关系。 次以每个属性数据结合函数ones(n,1)产生的数据 表3属性与二进制编码对应关系 作为输入x(其中n为样本的个数),通过经验以及 Table 3 Binary encoding of all attributes and its representation 多次实验确定较优的参数。结果集中可能会存在孤 属性 二进制编码 立点,较优的参数能够减少孤立点的个数,并且产生 较为合理的分类。在实际应用中,孤立点的数量往 non_fee A2 往远小于正常数据)],因此其影响比较小,故本文 A 就近将孤立点分配至临近的区间(相应的孤立点处 year_local fee A. 理方法作为后续工作)。经过DBSCAN运算后,便 A 得到了属性分类,即“属性片段”,这些分类结果直 Ao 接反映了其属性值自然特有的内在规律,由事物本 A 身决定,不受人为控制,因此对后续进一步分析隐藏 As 在它们之间的相关性有重要的指导作用。最后,再 Ag 根据分类的个数,使用若干二进制位对属性片段进 A10 行二进制编码。以属性year_local_fee为例,其被划 Au 分为7个区间,包含65个孤立点,将这些孤立点按 AR 照就近原则并入7个区间内,故以3位二进制位来 foo2 An 表示,如表1所示。实验中各属性的分类数如表2 Au 所示。 1.2OCAT关联规则挖掘 表1属性year_local_fee的二进制编码对应关系 经过数据预处理得到的二进制数据不能采用决 Table 1 Classification of year local fee and its binary encoding 策树和聚类等传统方法处理,同时为了让关联规则 区间 12 3 4 5 6 > 易于实施并行计算,实验中采用了OCAT方法,该方 编码000 001010 011100101110 法每次产生一条最优子式(接受全部正样本,拒绝 尽可能多的负样本),最终将子式通过合取操作得 表2所有属性的分类数 到关联规则。但是,OCAT产生单个子式的过程中 Table 2 Classification quantity of all attributes 剪枝的数量较少,导致收敛速度缓慢,并且需要存储 属性 分类数 大量的叶子结点的限界,导致运算时耗费了极大的 non_fee 3 时间和空间。因此,实验中最终引入了启发式规 year local fee 7 则]0进行快速剪枝,将时间复杂度从指数级别 1 1 降到多项式级别,这将非常适合数据量庞大的电信 T2 5 数据挖掘。 fo 启发式方法中根据POS(a)/NEG(a:)的比值 逆序排列属性(片段)a:(a.为A:或4:)形成有序集 3)正负样本的构造。 合A,挑选A中前α(%)(阈值)的元素生成待选集 首先,根据数据集中chum标志位(标志客户流 合L。关联规则的构造过程即不断地从待选集合L 失信息的属性)的值,将整个数据集的用户划分为 中随机选出属性(片段)a加入子式的过程,该过程 已经流失的客户(chum值为0)和未流失的客户 持续到关联规则完成或集合L为空。若α值过小, (chum值为1)2类。其次,为了得到关联规则挖掘 则关联规则不完整,导致预测结果准确度下降:反 中需要的训练集和检验集,实验分别随机抽取未流 之,若α值过大,则对客户流失影响很小的属性(片 失客户和已流失客户中四分之三的数据[]来构造 段)可能会包含在关联规则中,从而导致关联规则的可以快速发现任意形状类的 DBSCAN 分类算 法[11]完成从“属性”到“属性片段” 的分解。 另外, 此数据集不同属性值域区间的差异较大,这可能会 影响分类的效果,因此还需要对这些属性进行常用 的归一化处理。 具体的步骤是:首先使用 mapmin⁃ max(x,min,max)函数将值域归一到区间[0,1],其 次以每个属性数据结合函数 ones(n,1)产生的数据 作为输入 x(其中 n 为样本的个数),通过经验以及 多次实验确定较优的参数。 结果集中可能会存在孤 立点,较优的参数能够减少孤立点的个数,并且产生 较为合理的分类。 在实际应用中,孤立点的数量往 往远小于正常数据[12] ,因此其影响比较小,故本文 就近将孤立点分配至临近的区间(相应的孤立点处 理方法作为后续工作)。 经过 DBSCAN 运算后,便 得到了属性分类,即“属性片段”,这些分类结果直 接反映了其属性值自然特有的内在规律,由事物本 身决定,不受人为控制,因此对后续进一步分析隐藏 在它们之间的相关性有重要的指导作用。 最后,再 根据分类的个数,使用若干二进制位对属性片段进 行二进制编码。 以属性 year_local_fee 为例,其被划 分为 7 个区间,包含 65 个孤立点,将这些孤立点按 照就近原则并入 7 个区间内,故以 3 位二进制位来 表示,如表 1 所示。 实验中各属性的分类数如表 2 所示。 表 1 属性 year_local_fee 的二进制编码对应关系 Table 1 Classification of year_local_fee and its binary encoding 区间 1 2 3 4 5 6 7 编码 000 001 010 011 100 101 110 表 2 所有属性的分类数 Table 2 Classification quantity of all attributes 属性 分类数 non_fee 3 year_local_fee 7 r1 7 r2 5 f e 0902 8 3)正负样本的构造。 首先,根据数据集中 churn 标志位(标志客户流 失信息的属性) 的值,将整个数据集的用户划分为 已经流失的客户( churn 值为 0) 和未流失的客户 (churn 值为 1)2 类。 其次,为了得到关联规则挖掘 中需要的训练集和检验集,实验分别随机抽取未流 失客户和已流失客户中四分之三的数据[13] 来构造 训练集数据的正负样本(用 E + 和 E - 来分别表示正 样本和负样本),剩余的数据用作检验集。 最后,通 过前后 10 次进行随机抽取得到正负样本,并分别计 算结果,进一步验证数据挖掘结果的稳定性、可信性 和鲁棒性。 在构造 E + 和 E - 时,采用了如表 3 所示 的属性排列顺序及其编码对应关系。 表 3 属性与二进制编码对应关系 Table 3 Binary encoding of all attributes and its representation 属性 二进制编码 non_fee A1 A2 year_local_fee A3 A4 A5 r1 A6 A7 A8 r2 A9 A10 A11 f e 0902 A12 A13 A14 1.2 OCAT 关联规则挖掘 经过数据预处理得到的二进制数据不能采用决 策树和聚类等传统方法处理,同时为了让关联规则 易于实施并行计算,实验中采用了 OCAT 方法,该方 法每次产生一条最优子式(接受全部正样本,拒绝 尽可能多的负样本),最终将子式通过合取操作得 到关联规则。 但是,OCAT 产生单个子式的过程中 剪枝的数量较少,导致收敛速度缓慢,并且需要存储 大量的叶子结点的限界,导致运算时耗费了极大的 时间和空间。 因此,实验中最终引入了启发式规 则[9] 73-80进行快速剪枝,将时间复杂度从指数级别 降到多项式级别,这将非常适合数据量庞大的电信 数据挖掘。 启发式方法中根据 POS( ak) / NEG( ak)的比值 逆序排列属性(片段)ak(ak为 Ai或ØAi)形成有序集 合 A,挑选 A 中前 α(%) (阈值)的元素生成待选集 合 L。 关联规则的构造过程即不断地从待选集合 L 中随机选出属性(片段) ak加入子式的过程,该过程 持续到关联规则完成或集合 L 为空。 若 α 值过小, 则关联规则不完整,导致预测结果准确度下降;反 之,若 α 值过大,则对客户流失影响很小的属性(片 段)可能会包含在关联规则中,从而导致关联规则 第 3 期 梁路,等:基于细精度关联规则挖掘的电信客户流失分析 ·409·