正在加载图片...
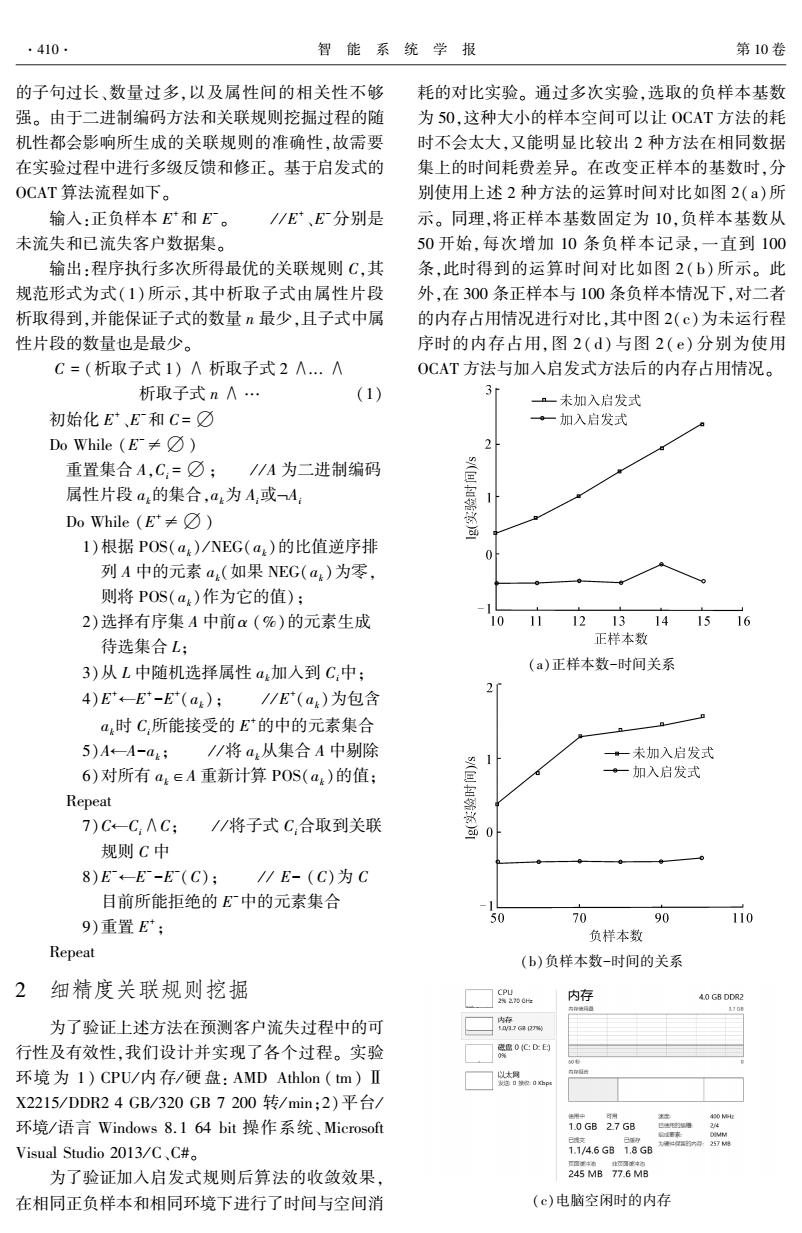
·410 智能系统学报 第10卷 的子句过长、数量过多,以及属性间的相关性不够 耗的对比实验。通过多次实验,选取的负样本基数 强。由于二进制编码方法和关联规则挖掘过程的随 为50,这种大小的样本空间可以让OCAT方法的耗 机性都会影响所生成的关联规则的准确性,故需要 时不会太大,又能明显比较出2种方法在相同数据 在实验过程中进行多级反馈和修正。基于启发式的 集上的时间耗费差异。在改变正样本的基数时,分 OCAT算法流程如下。 别使用上述2种方法的运算时间对比如图2(a)所 输入:正负样本E和E。 /E、E分别是 示。同理,将正样本基数固定为10,负样本基数从 未流失和已流失客户数据集。 50开始,每次增加10条负样本记录,一直到100 输出:程序执行多次所得最优的关联规则C,其 条,此时得到的运算时间对比如图2(b)所示。此 规范形式为式(1)所示,其中析取子式由属性片段 外,在300条正样本与100条负样本情况下,对二者 析取得到,并能保证子式的数量n最少,且子式中属 的内存占用情况进行对比,其中图2(c)为未运行程 性片段的数量也是最少。 序时的内存占用,图2(d)与图2(e)分别为使用 C=(析取子式1)八析取子式2∧.个 OCAT方法与加入启发式方法后的内存占用情况。 析取子式n八… (1) 一未加入启发式 初始化E、E和C=☑ 。一加入启发式 Do While(E≠⑦) 2 重置集合A,C,=☑;/A为二进制编码 属性片段a的集合,a4为A,或-4: 1 Do While(E*≠☑) 画 1)根据POS(a)/NEG(a,)的比值逆序排 列A中的元素a4(如果NEG(a4)为零, 则将POS(a)作为它的值): 2)选择有序集A中前α(%)的元素生成 10 11 12131415 16 待选集合L; 正样本数 3)从L中随机选择属性a加入到C:中: (a)正样本数-时间关系 4)E←-E*-E(a);/E(a)为包含 a时C,所能接受的E的中的元素集合 5)A←-A-a4: /将a从集合A中别除 ·一未加入启发式 6)对所有a4∈A重新计算P0S(a)的值: 一加入启发式 Repeat 7)C-C∧C: //将子式C合取到关联 0 规则C中 8)E←-E-E(C); /E-(C)为C 目前所能拒绝的E中的元素集合 9)重置E*: 50 70 90 110 负样本数 Repeat (b)负样本数-时间的关系 2细精度关联规则挖掘 goen 内存 4.0 GB DDR2 有程地用道 110t 为了验证上述方法在预测客户流失过程中的可 航a 行性及有效性,我们设计并实现了各个过程。实验 袋occ白 环境为1)CPU/内存/硬盘:AMD Athlon(m)Ⅱ 以太同 X2215/DDR24GB/320GB7200转/min:2)平台/ 湘中 430Me 环境/语言Windows8.164bit操作系统、Microsoft 1.0 GB 27 GB Visual Studio2013/C、C#。 1.1/4.6GB1.8G6 度生有 为了验证加入启发式规则后算法的收敛效果, 245MB77.6MB 在相同正负样本和相同环境下进行了时间与空间消 (c)电脑空闲时的内存的子句过长、数量过多,以及属性间的相关性不够 强。 由于二进制编码方法和关联规则挖掘过程的随 机性都会影响所生成的关联规则的准确性,故需要 在实验过程中进行多级反馈和修正。 基于启发式的 OCAT 算法流程如下。 输入:正负样本 E +和 E - 。 / / E + 、E -分别是 未流失和已流失客户数据集。 输出:程序执行多次所得最优的关联规则 C,其 规范形式为式(1)所示,其中析取子式由属性片段 析取得到,并能保证子式的数量 n 最少,且子式中属 性片段的数量也是最少。 C = (析取子式 1) ∧ 析取子式 2 ∧... ∧ 析取子式 n ∧ … (1) 初始化 E + 、E -和 C = ∅ Do While (E -≠ ∅ ) 重置集合 A,Ci = ∅ ; / / A 为二进制编码 属性片段 ak的集合,ak为 Ai或ØAi Do While (E +≠ ∅ ) 1)根据 POS(ak) / NEG(ak)的比值逆序排 列 A 中的元素 ak(如果 NEG(ak)为零, 则将 POS(ak)作为它的值); 2)选择有序集 A 中前α (%)的元素生成 待选集合 L; 3)从 L 中随机选择属性 ak加入到 Ci中; 4)E +←E + -E + (ak); / / E + (ak)为包含 ak时 Ci所能接受的 E +的中的元素集合 5)A←A-ak; / / 将 ak从集合 A 中剔除 6)对所有 ak∈A 重新计算 POS(ak)的值; Repeat 7)C←Ci∧C; / / 将子式 Ci合取到关联 规则 C 中 8)E -←E - -E - (C); / / E- (C)为 C 目前所能拒绝的 E -中的元素集合 9)重置 E + ; Repeat 2 细精度关联规则挖掘 为了验证上述方法在预测客户流失过程中的可 行性及有效性,我们设计并实现了各个过程。 实验 环境 为 1) CPU/ 内 存/ 硬 盘: AMD Athlon ( tm) Ⅱ X2215 / DDR2 4 GB / 320 GB 7 200 转/ min;2)平台/ 环境/ 语言 Windows 8. 1 64 bit 操作系统、Microsoft Visual Studio 2013 / C、C#。 为了验证加入启发式规则后算法的收敛效果, 在相同正负样本和相同环境下进行了时间与空间消 耗的对比实验。 通过多次实验,选取的负样本基数 为 50,这种大小的样本空间可以让 OCAT 方法的耗 时不会太大,又能明显比较出 2 种方法在相同数据 集上的时间耗费差异。 在改变正样本的基数时,分 别使用上述 2 种方法的运算时间对比如图 2(a)所 示。 同理,将正样本基数固定为 10,负样本基数从 50 开始,每次增加 10 条负样本记录,一直到 100 条,此时得到的运算时间对比如图 2( b) 所示。 此 外,在 300 条正样本与 100 条负样本情况下,对二者 的内存占用情况进行对比,其中图 2(c)为未运行程 序时的内存占用,图 2 ( d) 与图 2 ( e) 分别为使用 OCAT 方法与加入启发式方法后的内存占用情况。 (a)正样本数-时间关系 (b)负样本数-时间的关系 (c)电脑空闲时的内存 ·410· 智 能 系 统 学 报 第 10 卷