正在加载图片...
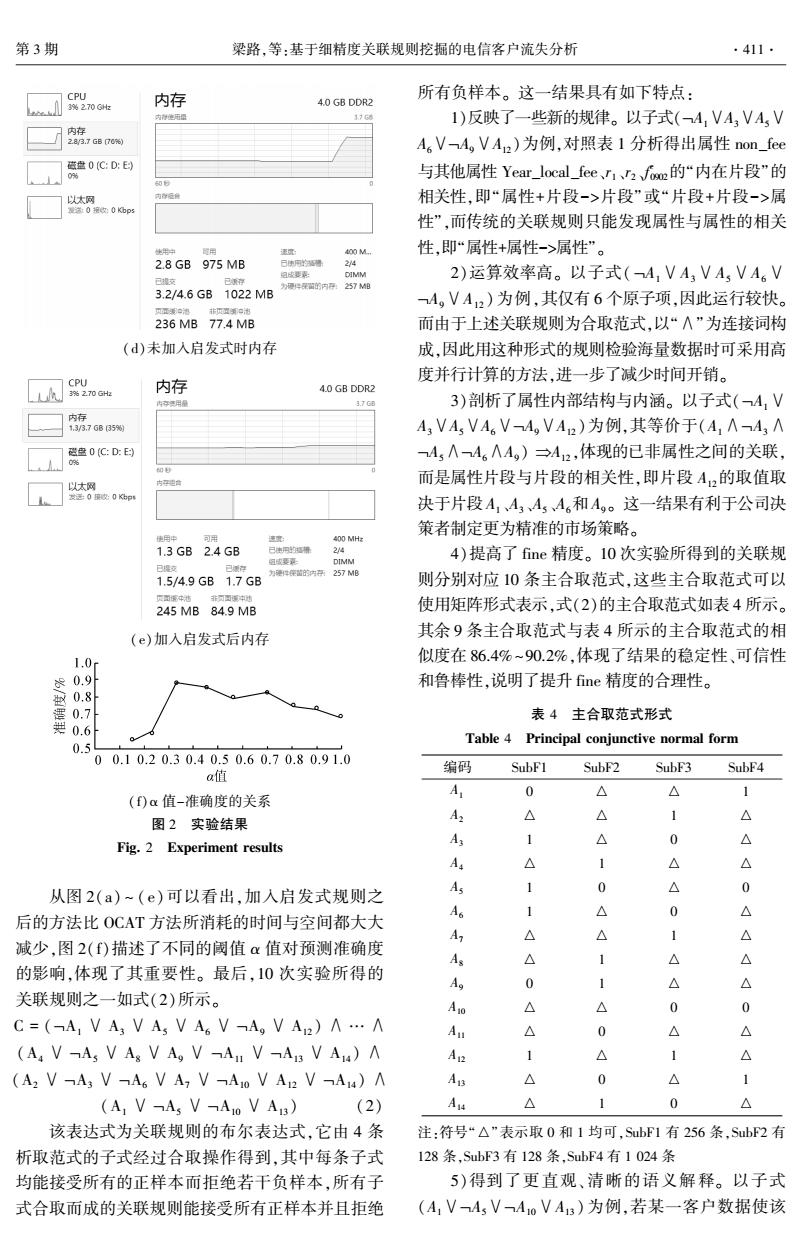
第3期 梁路,等:基于细精度关联规则挖掘的电信客户流失分析 ·411 CPU 内存 所有负样本。这一结果具有如下特点: 4.0 GB DDR2 176 1)反映了一些新的规律。以子式(-4VA3VAV 内存 2a/3.7GB70% A,V-A,VA2)为例,对照表1分析得出属性non_fee 蓝盘0C:D:E 0 与其他属性Year_local_fee、I1r2fm的“内在片段”的 以太网 内存延件 相关性,即“属性+片段->片段”或“片段+片段->属 覆法0接0kbp5 性”,而传统的关联规则只能发现属性与属性的相关 地用中 时用 逐 00M 性,即“属性+属性->属性”。 2.8GB975MB 日快阿的得 214 日皮要泰: DIMM 已交 已第存 2)运算效率高。以子式(A1VA,VA,VA6V 方件的内257M 3.2/4.6GB1022MB A,VA2)为例,其仅有6个原子项,因此运行较快。 非顶度到出 236MB77.4MB 而由于上述关联规则为合取范式,以“∧”为连接词构 (d)未加入启发式时内存 成,因此用这种形式的规则检验海量数据时可采用高 CPU 内存 度并行计算的方法,进一步了减少时间开销。 4.0 GB DDR2 内存用量 3768 3)剖析了属性内部结构与内涵。以子式(4,V 内存 13/3.7G635%则 A3VAVA.VA,VA2)为例,其等价于(A1∧A3A 磁盘0C:D:E到 AA46AAg)→A12,体现的已非属性之间的关联, 0 内骨 而是属性片段与片段的相关性,即片段A,的取值取 决于片段A143A,4,和A,。这一结果有利于公司决 策者制定更为精准的市场策略。 使同中 可用 速: 400MH 1.3GB2.4GB 已决用的播 214 阻成要来 DIMM 4)提高了fine精度。10次实验所得到的关联规 已存 1.5/4.9GB1.7GB 为年道的内257M 则分别对应10条主合取范式,这些主合取范式可以 面离中花非物四国中地 245MB84.9MB 使用矩阵形式表示,式(2)的主合取范式如表4所示。 (e)加入启发式后内存 其余9条主合取范式与表4所示的主合取范式的相 1.0 似度在86.4%~90.2%,体现了结果的稳定性、可信性 0.9 和鲁棒性,说明了提升fine精度的合理性。 0.8 0.7 表4主合取范式形式 0.6 0.5 Table 4 Principal conjunctive normal form 00.10.20.30.40.50.60.70.80.91.0 编码 SubF1 SubF2 SubF3 SubF4 a值 ()α值-准确度的关系 A 0 △ △ 1 图2实验结果 A2 △ △ 1 △ Fig.2 Experiment results Ax 1 △ △ A △ △ △ 从图2(a)~(e)可以看出,加入启发式规则之 As 1 0 △ 0 1 △ 0 △ 后的方法比OCAT方法所消耗的时间与空间都大大 Ao A △ △ 1 △ 减少,图2(f)描述了不同的阈值α值对预测准确度 As △ 1 △ 的影响,体现了其重要性。最后,10次实验所得的 Ag 0 1 △ △ 关联规则之一如式(2)所示。 A1o △ △ 0 0 C=(A:V A3 V As V A VA,V A2)A...n A △ 0 △ △ (A VAs V As VAg VA V-A3 V A4)A AR △ 1 △ (A2 VA3 VAs V A7 VA0 V A VA)A An △ 0 △ (A VAs VA0 V A3) (2) A △ 1 0 该表达式为关联规则的布尔表达式,它由4条 注:符号“△”表示取0和1均可,SubF1有256条,SubF2有 析取范式的子式经过合取操作得到,其中每条子式 128条,SubF3有128条,SubF4有1024条 均能接受所有的正样本而拒绝若干负样本,所有子 5)得到了更直观、清晰的语义解释。以子式 式合取而成的关联规则能接受所有正样本并且拒绝 (A,VMsV4oVA13)为例,若某一客户数据使该(d)未加入启发式时内存 (e)加入启发式后内存 (f)α 值-准确度的关系 图 2 实验结果 Fig. 2 Experiment results 从图 2(a) ~ ( e)可以看出,加入启发式规则之 后的方法比 OCAT 方法所消耗的时间与空间都大大 减少,图 2(f)描述了不同的阈值 α 值对预测准确度 的影响,体现了其重要性。 最后,10 次实验所得的 关联规则之一如式(2)所示。 C = (ØA1 ∨ A3 ∨ A5 ∨ A6 ∨ ØA9 ∨ A12 ) ∧ … ∧ (A4 ∨ ØA5 ∨ A8 ∨ A9 ∨ ØA11 ∨ ØA13 ∨ A14 ) ∧ (A2 ∨ ØA3 ∨ ØA6 ∨ A7 ∨ ØA10 ∨ A12 ∨ ØA14 ) ∧ (A1 ∨ ØA5 ∨ ØA10 ∨ A13 ) (2) 该表达式为关联规则的布尔表达式,它由 4 条 析取范式的子式经过合取操作得到,其中每条子式 均能接受所有的正样本而拒绝若干负样本,所有子 式合取而成的关联规则能接受所有正样本并且拒绝 所有负样本。 这一结果具有如下特点: 1)反映了一些新的规律。 以子式(ØA1∨A3∨A5∨ A6∨ØA9∨A12 )为例,对照表 1 分析得出属性 non_fee 与其他属性 Year_local_fee、r1、r2、f e 0902的“内在片段”的 相关性,即“属性+片段->片段”或“片段+片段->属 性”,而传统的关联规则只能发现属性与属性的相关 性,即“属性+属性->属性”。 2)运算效率高。 以子式( ØA1∨A3∨A5∨A6∨ ØA9∨A12 )为例,其仅有 6 个原子项,因此运行较快。 而由于上述关联规则为合取范式,以“∧”为连接词构 成,因此用这种形式的规则检验海量数据时可采用高 度并行计算的方法,进一步了减少时间开销。 3)剖析了属性内部结构与内涵。 以子式(ØA1∨ A3∨A5∨A6∨ØA9∨A12 )为例,其等价于(A1∧ØA3∧ ØA5∧ØA6∧A9 ) ÞA12 ,体现的已非属性之间的关联, 而是属性片段与片段的相关性,即片段 A12的取值取 决于片段 A1 、A3 、A5 、A6和 A9 。 这一结果有利于公司决 策者制定更为精准的市场策略。 4)提高了 fine 精度。 10 次实验所得到的关联规 则分别对应 10 条主合取范式,这些主合取范式可以 使用矩阵形式表示,式(2)的主合取范式如表 4 所示。 其余 9 条主合取范式与表 4 所示的主合取范式的相 似度在 86.4% ~90.2%,体现了结果的稳定性、可信性 和鲁棒性,说明了提升 fine 精度的合理性。 表 4 主合取范式形式 Table 4 Principal conjunctive normal form 编码 SubF1 SubF2 SubF3 SubF4 A1 0 △ △ 1 A2 △ △ 1 △ A3 1 △ 0 △ A4 △ 1 △ △ A5 1 0 △ 0 A6 1 △ 0 △ A7 △ △ 1 △ A8 △ 1 △ △ A9 0 1 △ △ A10 △ △ 0 0 A11 △ 0 △ △ A12 1 △ 1 △ A13 △ 0 △ 1 A14 △ 1 0 △ 注:符号“△”表示取 0 和 1 均可,SubF1 有 256 条,SubF2 有 128 条,SubF3 有 128 条,SubF4 有 1 024 条 5)得到了更直观、清晰的语义解释。 以子式 (A1∨ØA5∨ØA10∨A13 )为例,若某一客户数据使该 第 3 期 梁路,等:基于细精度关联规则挖掘的电信客户流失分析 ·411·