正在加载图片...
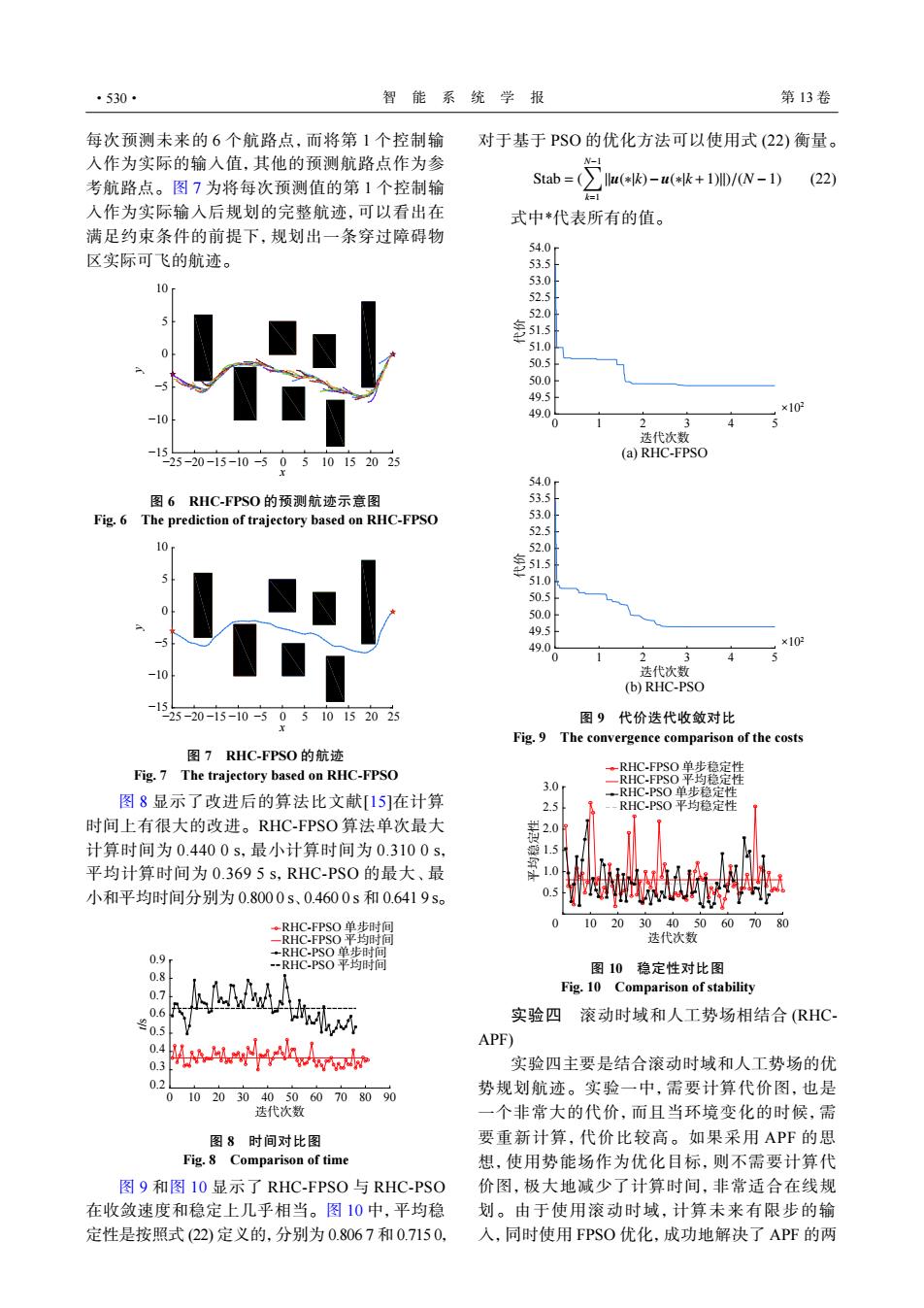
·530· 智能系统学报 第13卷 每次预测未来的6个航路点,而将第1个控制输 对于基于PS0的优化方法可以使用式(22)衡量。 入作为实际的输入值,其他的预测航路点作为参 考航路点。图7为将每次预测值的第1个控制输 Stab=((-B)-u(*+DD/(W-D (22) k=1 入作为实际输入后规划的完整航迹,可以看出在 式中*代表所有的值。 满足约束条件的前提下,规划出一条穿过障碍物 54.0 区实际可飞的航迹。 53.5 53.0 52.5 52.0 51.0 50.5 50.0 49.5 49.0 ×10 2 3 4 迭代次数 25-20-15-10-50510152025 (a)RHC-FPSO 54.0 图6RHC-FPSO的预测航迹示意图 53.5 Fig.6 The prediction of trajectory based on RHC-FPSO 53.0 52.5 10 52.0 51.5 51.0 50.5 50.0 49.5 49. ×10 0 1 4 迭代次数 (b)RHC-PSO 225-20-15-10-50510152025 图9代价迭代收敛对比 Fig.9 The convergence comparison of the costs 图7RHC-FPSO的航迹 Fig.7 The trajectory based on RHC-FPSO ◆RHC-FPSO单步稳定性 一RHC-FPSO平均稳定性 3.0 图8显示了改进后的算法比文献[15]在计算 .RHC-PSO单步稳定性 2.5 RHC-PSO平均稳定性 时间上有很大的改进。RHC-FPSO算法单次最大 计算时间为0.4400s,最小计算时间为0.3100s, 1.5 平均计算时间为0.3695s,RHC-PS0的最大、最 斗1.0 小和平均时间分别为0.8000s、0.4600s和0.6419s。 0.5 ◆RHC-FPSO单步时间 1020 304050607080 一RHC:FPSO平均时间 迭代次数 0.9 →RHC-PSO单步时间 -RHC-PSO平均时间 0.8 图10稳定性对比图 0.7 Fig.10 Comparison of stability 0.6 实验四滚动时域和人工势场相结合(RHC- 05 APF) 0.4 0.3 实验四主要是结合滚动时域和人工势场的优 0.2 0102030405060708090 势规划航迹。实验一中,需要计算代价图,也是 迭代次数 一个非常大的代价,而且当环境变化的时候,需 图8时间对比图 要重新计算,代价比较高。如果采用APF的思 Fig.8 Comparison of time 想,使用势能场作为优化目标,则不需要计算代 图9和图10显示了RHC-FPSO与RHC-PSO 价图,极大地减少了计算时间,非常适合在线规 在收敛速度和稳定上几乎相当。图10中,平均稳 划。由于使用滚动时域,计算未来有限步的输 定性是按照式(22)定义的,分别为0.8067和0.7150, 入,同时使用FPSO优化,成功地解决了APF的两每次预测未来的 6 个航路点,而将第 1 个控制输 入作为实际的输入值,其他的预测航路点作为参 考航路点。图 7 为将每次预测值的第 1 个控制输 入作为实际输入后规划的完整航迹,可以看出在 满足约束条件的前提下,规划出一条穿过障碍物 区实际可飞的航迹。 −15 −10 −5 0 5 10 −25 −20 −15 −10 −5 0 5 10 15 20 25 x y 图 6 RHC-FPSO 的预测航迹示意图 Fig. 6 The prediction of trajectory based on RHC-FPSO −15 −10 −5 0 5 10 −25 −20 −15 −10 −5 0 5 10 15 20 25 x y 图 7 RHC-FPSO 的航迹 Fig. 7 The trajectory based on RHC-FPSO 图 8 显示了改进后的算法比文献[15]在计算 时间上有很大的改进。RHC-FPSO 算法单次最大 计算时间为 0.440 0 s,最小计算时间为 0.310 0 s, 平均计算时间为 0.369 5 s,RHC-PSO 的最大、最 小和平均时间分别为 0.800 0 s、0.460 0 s 和 0.641 9 s。 0 10 20 30 40 50 60 70 80 90 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 RHC-FPSO 单步时间 RHC-FPSO 平均时间 RHC-PSO 单步时间 RHC-PSO 平均时间 迭代次数 t/s 图 8 时间对比图 Fig. 8 Comparison of time 图 9 和图 10 显示了 RHC-FPSO 与 RHC-PSO 在收敛速度和稳定上几乎相当。图 10 中,平均稳 定性是按照式 (22) 定义的,分别为 0.806 7 和 0.715 0, 对于基于 PSO 的优化方法可以使用式 (22) 衡量。 Stab = ( ∑N−1 k=1 ∥u(∗|k)−u(∗|k+1)∥)/(N −1) (22) 式中*代表所有的值。 0 1 2 3 4 5 迭代次数 49.0 49.5 50.0 50.5 51.0 51.5 52.0 52.5 53.0 53.5 54.0 代价 (a) RHC-FPSO 0 1 2 3 4 5 迭代次数 49.0 49.5 50.0 50.5 51.0 51.5 52.0 52.5 53.0 53.5 54.0 代价 (b) RHC-PSO ×102 ×102 图 9 代价迭代收敛对比 Fig. 9 The convergence comparison of the costs 0 10 20 30 40 50 60 70 80 0.5 1.0 1.5 2.0 2.5 3.0 RHC-FPSO 单步稳定性 RHC-FPSO 平均稳定性 RHC-PSO 单步稳定性 RHC-PSO 平均稳定性 迭代次数 平均稳定性 图 10 稳定性对比图 Fig. 10 Comparison of stability 实验四 滚动时域和人工势场相结合 (RHCAPF) 实验四主要是结合滚动时域和人工势场的优 势规划航迹。实验一中,需要计算代价图,也是 一个非常大的代价,而且当环境变化的时候,需 要重新计算,代价比较高。如果采用 APF 的思 想,使用势能场作为优化目标,则不需要计算代 价图,极大地减少了计算时间,非常适合在线规 划。由于使用滚动时域,计算未来有限步的输 入,同时使用 FPSO 优化,成功地解决了 APF 的两 ·530· 智 能 系 统 学 报 第 13 卷