正在加载图片...
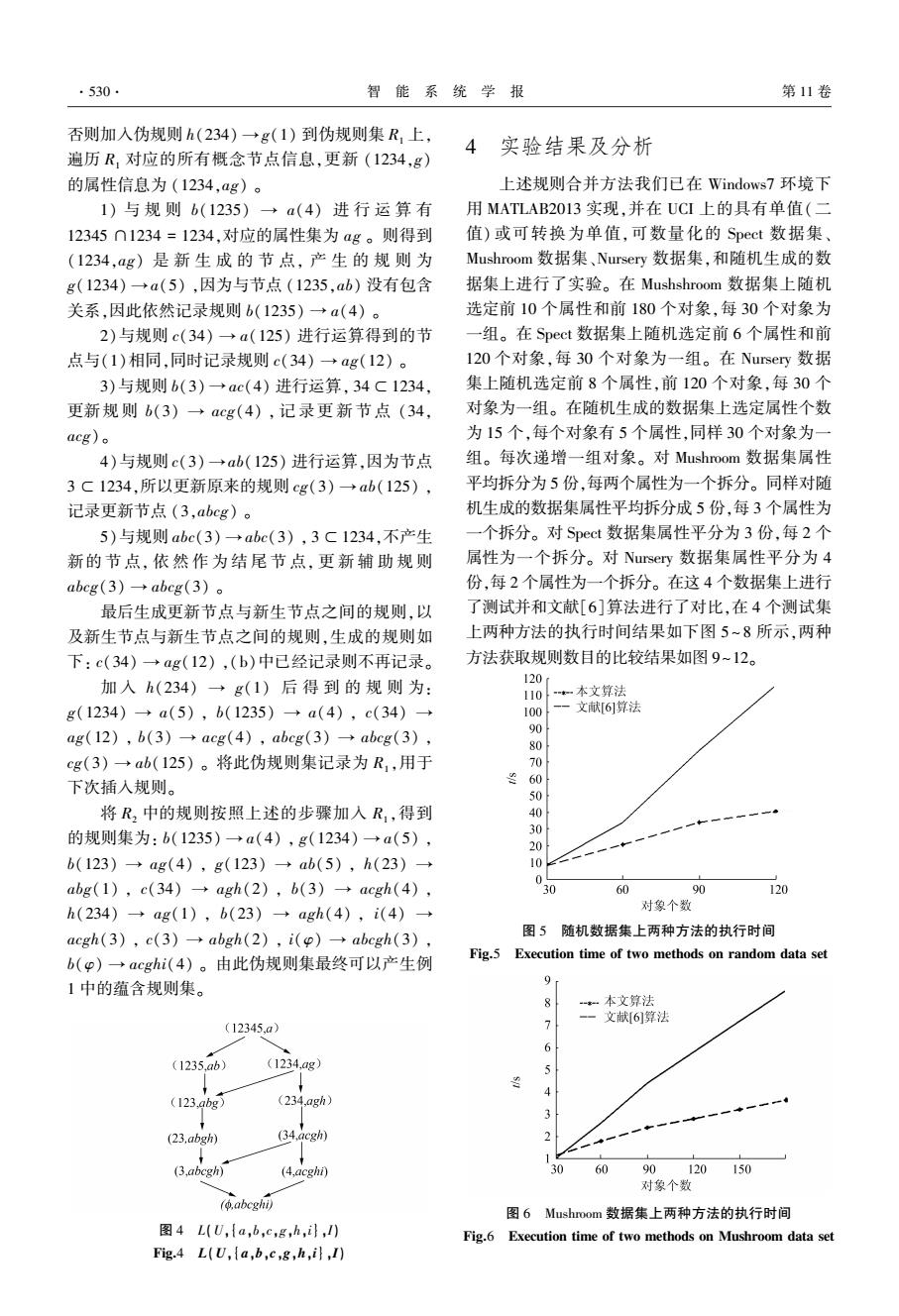
.530 智能系统学报 第11卷 否则加入伪规则h(234)→g(1)到伪规则集R,上, 4 实验结果及分析 遍历R,对应的所有概念节点信息,更新(1234,g) 的属性信息为(1234,ag))。 上述规则合并方法我们已在Windows7环境下 1)与规则b(1235)→a(4)进行运算有 用MATLAB2013实现,并在UCI上的具有单值(二 12345∩1234=1234,对应的属性集为ag。则得到 值)或可转换为单值,可数量化的Spect数据集 (1234,ag)是新生成的节点,产生的规则为 Mushroom数据集、Nursery数据集,和随机生成的数 g(1234)→a(5),因为与节点(1235,ab)没有包含 据集上进行了实验。在Mushshroom数据集上随机 关系,因此依然记录规则b(1235)→a(4)。 选定前10个属性和前180个对象,每30个对象为 2)与规则c(34)→a(125)进行运算得到的节 一组。在Spect数据集上随机选定前6个属性和前 点与(1)相同,同时记录规则c(34)→g(12)。 120个对象,每30个对象为一组。在Nursery数据 3)与规则b(3)→ac(4)进行运算,34C1234, 集上随机选定前8个属性,前120个对象,每30个 更新规则b(3)→acg(4),记录更新节点(34, 对象为一组。在随机生成的数据集上选定属性个数 acg)。 为15个,每个对象有5个属性,同样30个对象为一 4)与规则c(3)→ab(125)进行运算,因为节点 组。每次递增一组对象。对Mushroom数据集属性 3C1234,所以更新原来的规则cg(3)→ab(125), 平均拆分为5份,每两个属性为一个拆分。同样对随 记录更新节点(3,abcg)。 机生成的数据集属性平均拆分成5份,每3个属性为 5)与规则abc(3)+abc(3),3C1234,不产生 一个拆分。对Spect数据集属性平分为3份,每2个 新的节点,依然作为结尾节点,更新辅助规则 属性为一个拆分。对Nursery数据集属性平分为4 abcg(3)→abcg(3)。 份,每2个属性为一个拆分。在这4个数据集上进行 最后生成更新节点与新生节点之间的规则,以 了测试并和文献[6]算法进行了对比,在4个测试集 及新生节点与新生节点之间的规则,生成的规则如 上两种方法的执行时间结果如下图5~8所示,两种 下:c(34)→ag(12),(b)中已经记录则不再记录。 方法获取规则数目的比较结果如图9~12。 加入h(234)→g(1)后得到的规则为: 120 110 *本文算法 g(1234)→a(5),b(1235)→a(4),c(34)→ 100 文献6]算法 ag(12),b(3)→acg(4),abcg(3)→abcg(3), 90 80 cg(3)→ab(125)。将此伪规则集记录为R,用于 0 下次插入规则。 6 50 将R,中的规则按照上述的步骤加入R,得到 40 一 的规则集为:b(1235)→a(4),g(1234)→a(5), 30 20 b(123)→ag(4),g(123)→ab(5),,h(23)→ 10 abg(1),c(34)→agh(2),b(3)→acgh(4), 0 0 60 90 120 h(234)→ag(1),b(23)→agh(4),i(4)→ 对象个数 acgh(3),c(3)→abgh(2),i(p)→abcgh(3), 图5随机数据集上两种方法的执行时间 b(p)一acghi(4)。由此伪规则集最终可以产生例 Fig.5 Execution time of two methods on random data set 1中的蕴含规则集。 9 f *一本文算法 一文献[6]算法 (12345,a) 6 (1235.ab) (1234,ag) (123,abg) (234,agh) (23.abgh) (34.acgh) ◆ (3.abcgh) (4,acghi) 30 60 90120150 对象个数 (.abcghi) 图6 Mushroom数据集上两种方法的执行时间 4 L(U,(a,b,c,g,h,i,) Fig.6 Execution time of two methods on Mushroom data set Fig.4 L(U,a,b,c,g,h,i)否则加入伪规则 h(234) → g(1) 到伪规则集 R1 上, 遍历 R1 对应的所有概念节点信息,更新 (1234,g) 的属性信息为 (1234,ag) 。 1) 与 规 则 b(1235) → a(4) 进 行 运 算 有 12345 ∩1234 = 1234,对应的属性集为 ag 。 则得到 (1234,ag) 是 新 生 成 的 节 点, 产 生 的 规 则 为 g(1234) → a(5) ,因为与节点 (1235,ab) 没有包含 关系,因此依然记录规则 b(1235) → a(4) 。 2)与规则 c(34) → a(125) 进行运算得到的节 点与(1)相同,同时记录规则 c(34) → ag(12) 。 3)与规则 b(3) → ac(4) 进行运算, 34 ⊂1234, 更新规 则 b(3) → acg(4) , 记 录 更 新 节 点 (34, acg)。 4)与规则 c(3) →ab(125) 进行运算,因为节点 3 ⊂ 1234,所以更新原来的规则 cg(3) → ab(125) , 记录更新节点 (3,abcg) 。 5)与规则 abc(3) → abc(3) , 3 ⊂1234,不产生 新的 节 点, 依 然 作 为 结 尾 节 点, 更 新 辅 助 规 则 abcg(3) → abcg(3) 。 最后生成更新节点与新生节点之间的规则,以 及新生节点与新生节点之间的规则,生成的规则如 下: c(34) → ag(12) ,(b)中已经记录则不再记录。 加 入 h(234) → g(1) 后 得 到 的 规 则 为: g(1234) → a(5) , b(1235) → a(4) , c(34) → ag(12) , b(3) → acg(4) , abcg(3) → abcg(3) , cg(3) → ab(125) 。 将此伪规则集记录为 R1 ,用于 下次插入规则。 将 R2 中的规则按照上述的步骤加入 R1 ,得到 的规则集为: b(1235) → a(4) , g(1234) → a(5) , b(123) → ag(4) , g(123) → ab(5) , h(23) → abg(1) , c(34) → agh(2) , b(3) → acgh(4) , h(234) → ag(1) , b(23) → agh(4) , i(4) → acgh(3) , c(3) → abgh(2) , i(φ) → abcgh(3) , b(φ) → acghi(4) 。 由此伪规则集最终可以产生例 1 中的蕴含规则集。 图 4 L(U,{a,b,c,g,h,i},I) Fig.4 L(U,{a,b,c,g,h,i},I) 4 实验结果及分析 上述规则合并方法我们已在 Windows7 环境下 用 MATLAB2013 实现,并在 UCI 上的具有单值(二 值) 或可转换为单值,可数量化的 Spect 数据集、 Mushroom 数据集、Nursery 数据集,和随机生成的数 据集上进行了实验。 在 Mushshroom 数据集上随机 选定前 10 个属性和前 180 个对象,每 30 个对象为 一组。 在 Spect 数据集上随机选定前 6 个属性和前 120 个对象,每 30 个对象为一组。 在 Nursery 数据 集上随机选定前 8 个属性,前 120 个对象,每 30 个 对象为一组。 在随机生成的数据集上选定属性个数 为 15 个,每个对象有 5 个属性,同样 30 个对象为一 组。 每次递增一组对象。 对 Mushroom 数据集属性 平均拆分为 5 份,每两个属性为一个拆分。 同样对随 机生成的数据集属性平均拆分成 5 份,每 3 个属性为 一个拆分。 对 Spect 数据集属性平分为 3 份,每 2 个 属性为一个拆分。 对 Nursery 数据集属性平分为 4 份,每 2 个属性为一个拆分。 在这 4 个数据集上进行 了测试并和文献[6]算法进行了对比,在 4 个测试集 上两种方法的执行时间结果如下图 5 ~ 8 所示,两种 方法获取规则数目的比较结果如图 9~12。 图 5 随机数据集上两种方法的执行时间 Fig.5 Execution time of two methods on random data set 图 6 Mushroom 数据集上两种方法的执行时间 Fig.6 Execution time of two methods on Mushroom data set ·530· 智 能 系 统 学 报 第 11 卷