正在加载图片...
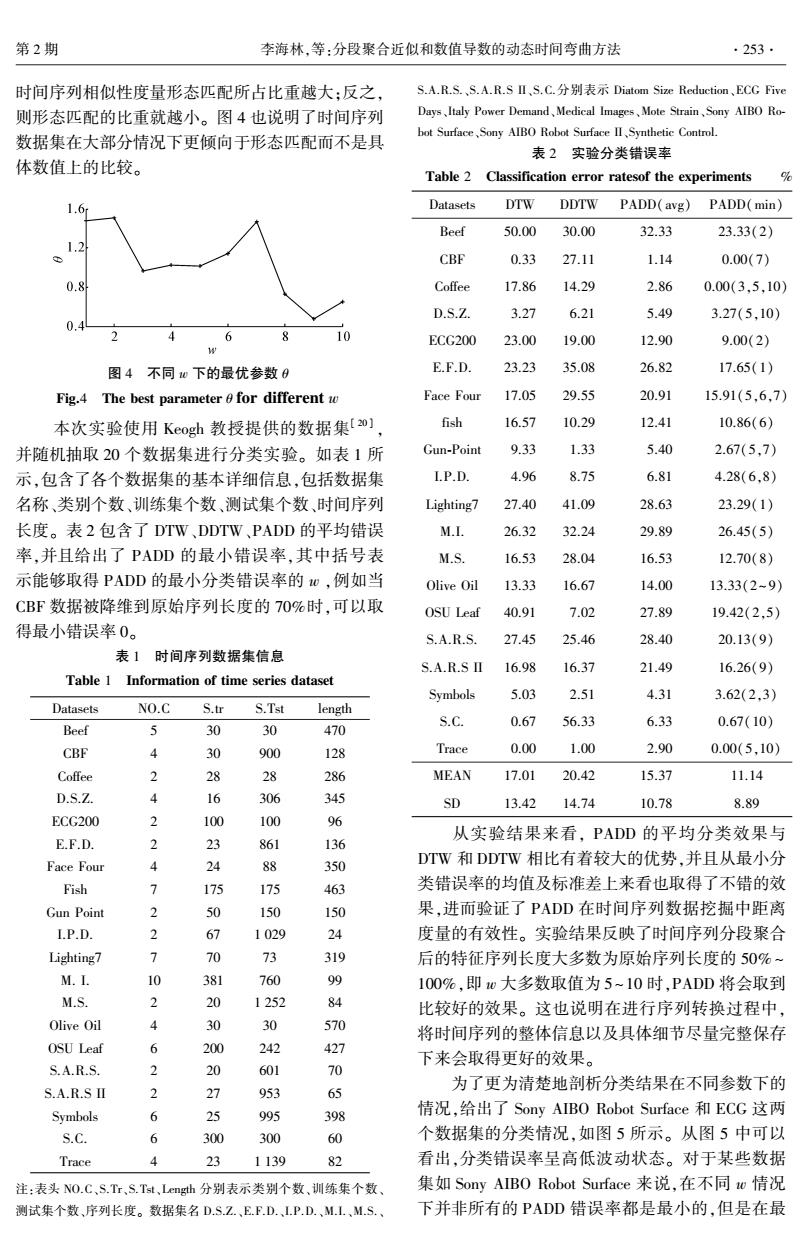
第2期 李海林,等:分段聚合近似和数值导数的动态时间弯曲方法 .253. 时间序列相似性度量形态匹配所占比重越大:反之 S.A.R.S.、S.A.R.SⅡ、S.C.分别表示Diatom Size Reduction、ECG Five 则形态匹配的比重就越小。图4也说明了时间序列 Days、Italy Power Demand、Medical Images、Mote Strain,Sony AIBO Ro-- bot Surface,Sony AlBO Robot Surface II,Synthetic Control. 数据集在大部分情况下更倾向于形态匹配而不是具 表2实验分类错误率 体数值上的比较。 Table 2 Classification error ratesof the experiments Datasets DTW DDTW PADD(avg) PADD(min) Beef 50.00 30.00 32.33 23.33(2) CBF 0.33 27.11 1.14 0.00(7) Coffee 17.86 14.29 2.86 0.00(3,5,10) D.S.Z. 3.27 6.21 5.49 3.27(5.10) 6 10 ECG200 23.00 19.00 12.90 9.00(2) 图4不同w下的最优参数0 E.F.D. 23.23 35.08 26.82 17.65(1) Fig.4 The best parameter for different w Face Four 17.05 29.55 20.91 15.91(5,6,7) 本次实验使用Keogh教授提供的数据集[0] fish 16.57 10.29 12.41 10.86(6) 并随机抽取20个数据集进行分类实验。如表1所 Gun-Point 9.33 1.33 5.40 2.67(5,7) 示,包含了各个数据集的基本详细信息,包括数据集 I.P.D. 4.96 8.75 6.81 4.28(6,8) 名称、类别个数、训练集个数、测试集个数、时间序列 Lighting7 27.40 41.09 28.63 23.29(1) 长度。表2包含了DTW、DDTW、PADD的平均错误 M.I. 26.32 32.24 29.89 26.45(5) 率,并且给出了PADD的最小错误率,其中括号表 M.S. 16.53 28.04 16.53 12.70(8) 示能够取得PADD的最小分类错误率的w,例如当 Olive Oil 13.33 16.67 14.00 13.33(2-9) CBF数据被降维到原始序列长度的70%时,可以取 OSU Leaf 40.91 7.02 27.89 19.42(2,5) 得最小错误率0。 S.A.R.S. 27.45 25.46 28.40 20.13(9) 表1时间序列数据集信息 S.A.R.SΠ 16.98 16.37 21.49 16.26(9) Table 1 Information of time series dataset Symbols 5.03 2.51 4.31 3.62(2,3) Datasets NO.C S.tr S.Tst length 5 S.C. 0.67 56.33 6.33 0.67(10) Beef 30 30 470 CBF 4 30 900 128 Trace 0.00 1.00 2.90 0.00(5,10) Coffee 2 28 28 286 MEAN 17.01 20.42 15.37 11.14 D.S.Z. 4 16 306 345 SD 13.42 14.74 10.78 8.89 ECG200 2 100 100 96 从实验结果来看,PADD的平均分类效果与 E.F.D. 2 23 861 136 Face Four 4 24 88 350 DTW和DDTW相比有着较大的优势,并且从最小分 Fish 7 175 175 463 类错误率的均值及标准差上来看也取得了不错的效 Gun Point 2 150 150 果,进而验证了PADD在时间序列数据挖掘中距离 I.P.D. 2 67 1029 24 度量的有效性。实验结果反映了时间序列分段聚合 Lighting7 7 70 13 319 后的特征序列长度大多数为原始序列长度的50%~ M.I. 10 381 760 99 100%,即0大多数取值为5~10时,PADD将会取到 M.S. 2 20 1252 84 比较好的效果。这也说明在进行序列转换过程中, Olive Oil 4 30 30 570 将时间序列的整体信息以及具体细节尽量完整保存 OSU Leaf 6 200 242 427 下来会取得更好的效果。 S.A.R.S. 2 20 601 70 S.A.R.SΠ 2 27 为了更为清楚地剖析分类结果在不同参数下的 953 65 Symbols 情况,给出了Sony AIBO Robot Surface和ECG这两 6 3 995 398 S.C. 6 300 300 60 个数据集的分类情况,如图5所示。从图5中可以 Trace 23 1139 82 看出,分类错误率呈高低波动状态。对于某些数据 注:表头NO.C、S.Tr,S.Tst、Length分别表示类别个数、训练集个数 集如Sony AIB0 Robot Surface来说,在不同w情况 测试集个数、序列长度。数据集名D.S.Z.、EFD.、LP.D.、ML.、M.S.、 下并非所有的PADD错误率都是最小的,但是在最时间序列相似性度量形态匹配所占比重越大;反之, 则形态匹配的比重就越小。 图 4 也说明了时间序列 数据集在大部分情况下更倾向于形态匹配而不是具 体数值上的比较。 图 4 不同 w 下的最优参数 θ Fig.4 The best parameter θ for different w 本次实验使用 Keogh 教授提供的数据集[ 20 ] , 并随机抽取 20 个数据集进行分类实验。 如表 1 所 示,包含了各个数据集的基本详细信息,包括数据集 名称、类别个数、训练集个数、测试集个数、时间序列 长度。 表 2 包含了 DTW、DDTW、PADD 的平均错误 率,并且给出了 PADD 的最小错误率,其中括号表 示能够取得 PADD 的最小分类错误率的 w ,例如当 CBF 数据被降维到原始序列长度的 70%时,可以取 得最小错误率 0。 表 1 时间序列数据集信息 Table 1 Information of time series dataset Datasets NO.C S.tr S.Tst length Beef 5 30 30 470 CBF 4 30 900 128 Coffee 2 28 28 286 D.S.Z. 4 16 306 345 ECG200 2 100 100 96 E.F.D. 2 23 861 136 Face Four 4 24 88 350 Fish 7 175 175 463 Gun Point 2 50 150 150 I.P.D. 2 67 1 029 24 Lighting7 7 70 73 319 M. I. 10 381 760 99 M.S. 2 20 1 252 84 Olive Oil 4 30 30 570 OSU Leaf 6 200 242 427 S.A.R.S. 2 20 601 70 S.A.R.S II 2 27 953 65 Symbols 6 25 995 398 S.C. 6 300 300 60 Trace 4 23 1 139 82 注:表头 NO.C、S.Tr、S.Tst、Length 分别表示类别个数、训练集个数、 测试集个数、序列长度。 数据集名 D.S.Z.、E.F.D.、I.P.D.、M.I.、M.S.、 S.A.R.S.、S.A.R.S II、S.C.分别表示 Diatom Size Reduction、ECG Five Days、Italy Power Demand、Medical Images、Mote Strain、Sony AIBO Ro⁃ bot Surface、Sony AIBO Robot Surface II、Synthetic Control. 表 2 实验分类错误率 Table 2 Classification error ratesof the experiments % Datasets DTW DDTW PADD(avg) PADD(min) Beef 50.00 30.00 32.33 23.33(2) CBF 0.33 27.11 1.14 0.00(7) Coffee 17.86 14.29 2.86 0.00(3,5,10) D.S.Z. 3.27 6.21 5.49 3.27(5,10) ECG200 23.00 19.00 12.90 9.00(2) E.F.D. 23.23 35.08 26.82 17.65(1) Face Four 17.05 29.55 20.91 15.91(5,6,7) fish 16.57 10.29 12.41 10.86(6) Gun⁃Point 9.33 1.33 5.40 2.67(5,7) I.P.D. 4.96 8.75 6.81 4.28(6,8) Lighting7 27.40 41.09 28.63 23.29(1) M.I. 26.32 32.24 29.89 26.45(5) M.S. 16.53 28.04 16.53 12.70(8) Olive Oil 13.33 16.67 14.00 13.33(2~ 9) OSU Leaf 40.91 7.02 27.89 19.42(2,5) S.A.R.S. 27.45 25.46 28.40 20.13(9) S.A.R.S II 16.98 16.37 21.49 16.26(9) Symbols 5.03 2.51 4.31 3.62(2,3) S.C. 0.67 56.33 6.33 0.67(10) Trace 0.00 1.00 2.90 0.00(5,10) MEAN 17.01 20.42 15.37 11.14 SD 13.42 14.74 10.78 8.89 从实验结果来看, PADD 的平均分类效果与 DTW 和 DDTW 相比有着较大的优势,并且从最小分 类错误率的均值及标准差上来看也取得了不错的效 果,进而验证了 PADD 在时间序列数据挖掘中距离 度量的有效性。 实验结果反映了时间序列分段聚合 后的特征序列长度大多数为原始序列长度的 50% ~ 100%,即 w 大多数取值为 5~10 时,PADD 将会取到 比较好的效果。 这也说明在进行序列转换过程中, 将时间序列的整体信息以及具体细节尽量完整保存 下来会取得更好的效果。 为了更为清楚地剖析分类结果在不同参数下的 情况,给出了 Sony AIBO Robot Surface 和 ECG 这两 个数据集的分类情况,如图 5 所示。 从图 5 中可以 看出,分类错误率呈高低波动状态。 对于某些数据 集如 Sony AIBO Robot Surface 来说,在不同 w 情况 下并非所有的 PADD 错误率都是最小的,但是在最 第 2 期 李海林,等:分段聚合近似和数值导数的动态时间弯曲方法 ·253·