正在加载图片...
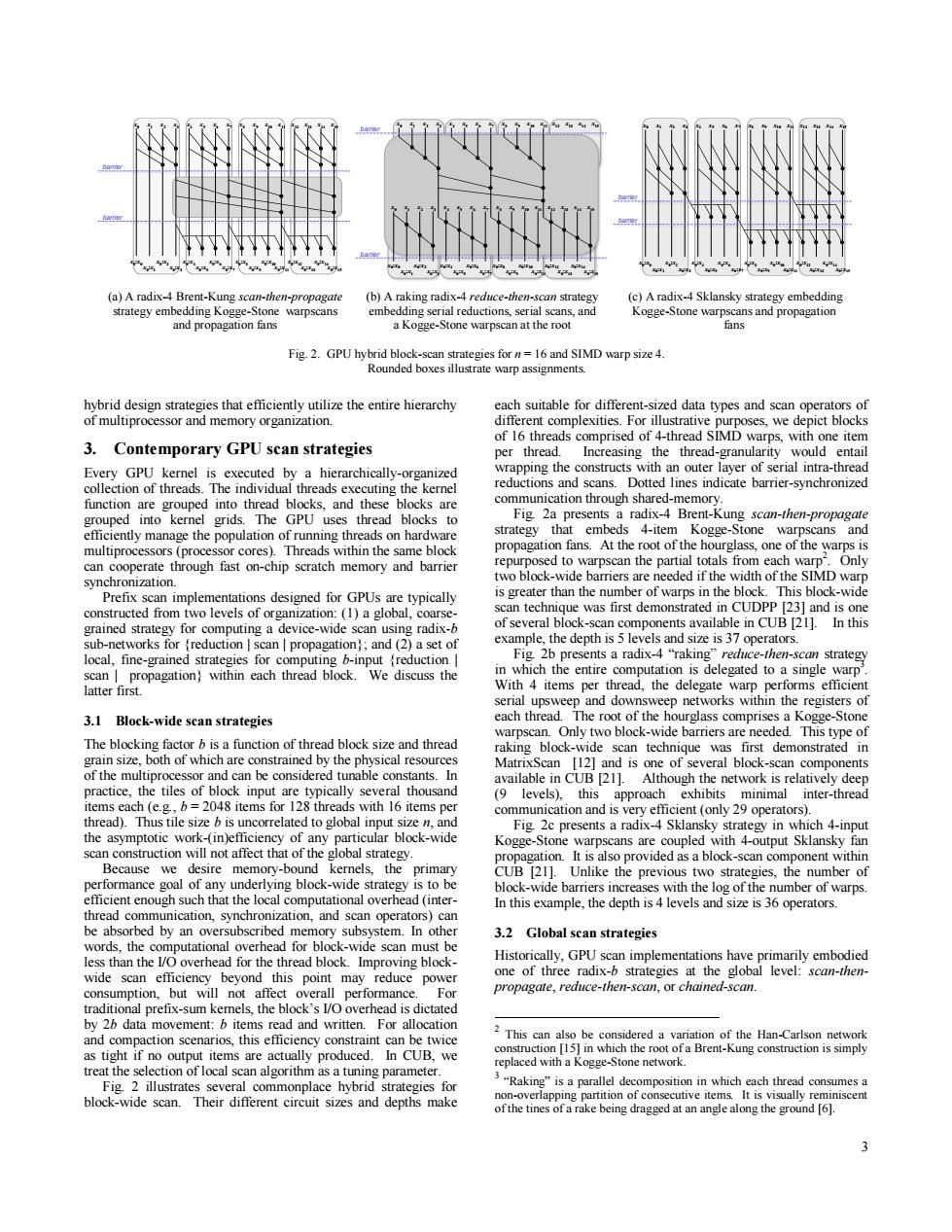
(a)A radix-4 Brent-Kung scan-then-propagate (b)A raking radix-4 reduce-then-scan strategy (c)A radix-4 Sklansky strategy embedding strategy embedding Kogge-Stone warpscans embedding serial reductions,serial scans,and Kogge-Stone warpscans and propagation and propagation fans a Kogge-Stone warpscan at the root fans Fig.2.GPU hybrid block-scan strategies for n=16 and SIMD warp size 4. Rounded boxes illustrate warp assignments. hybrid design strategies that efficiently utilize the entire hierarchy each suitable for different-sized data types and scan operators of of multiprocessor and memory organization. different complexities.For illustrative purposes,we depict blocks of 16 threads comprised of 4-thread SIMD warps,with one item 3.Contemporary GPU scan strategies per thread.Increasing the thread-granularity would entail Every GPU kernel is executed by a hierarchically-organized wrapping the constructs with an outer layer of serial intra-thread collection of threads.The individual threads executing the kernel reductions and scans.Dotted lines indicate barrier-synchronized function are grouped into thread blocks,and these blocks are communication through shared-memory grouped into kernel grids.The GPU uses thread blocks to Fig.2a presents a radix-4 Brent-Kung scan-then-propagate efficiently manage the population of running threads on hardware strategy that embeds 4-item Kogge-Stone warpscans and multiprocessors(processor cores).Threads within the same block propagation fans.At the root of the hourglass,one of the warps is can cooperate through fast on-chip scratch memory and barrier repurposed to warpscan the partial totals from each warp.Only synchronization. two block-wide barriers are needed if the width of the SIMD warp Prefix scan implementations designed for GPUs are typically is greater than the number of warps in the block.This block-wide constructed from two levels of organization:(1)a global,coarse- scan technique was first demonstrated in CUDPP [23]and is one grained strategy for computing a device-wide scan using radix-b of several block-scan components available in CUB [21]. In this sub-networks for {reduction scan propagation;and (2)a set of example,the depth is 5 levels and size is 37 operators. local,fine-grained strategies for computing b-input reduction Fig.2b presents a radix-4"raking"reduce-then-scan strategy scan propagation)within each thread block.We discuss the in which the entire computation is delegated to a single warp" latter first. With 4 items per thread,the delegate warp performs efficient serial upsweep and downsweep networks within the registers of 3.1 Block-wide scan strategies each thread.The root of the hourglass comprises a Kogge-Stone warpscan.Only two block-wide barriers are needed.This type of The blocking factor b is a function of thread block size and thread raking block-wide scan technique was first demonstrated in grain size,both of which are constrained by the physical resources MatrixScan [12]and is one of several block-scan components of the multiprocessor and can be considered tunable constants.In available in CUB [21].Although the network is relatively deep practice,the tiles of block input are typically several thousand (9 levels),this approach exhibits minimal inter-thread items each (e.g.,b=2048 items for 128 threads with 16 items per communication and is very efficient (only 29 operators). thread).Thus tile size b is uncorrelated to global input size n,and Fig.2c presents a radix-4 Sklansky strategy in which 4-input the asymptotic work-(in)efficiency of any particular block-wide Kogge-Stone warpscans are coupled with 4-output Sklansky fan scan construction will not affect that of the global strategy propagation.It is also provided as a block-scan component within Because we desire memory-bound kernels,the primary CUB [211.Unlike the previous two strategies,the number of performance goal of any underlying block-wide strategy is to be block-wide barriers increases with the log of the number of warps efficient enough such that the local computational overhead(inter- In this example,the depth is 4 levels and size is 36 operators. thread communication,synchronization,and scan operators)can be absorbed by an oversubscribed memory subsystem.In other 3.2 Global scan strategies words,the computational overhead for block-wide scan must be less than the I/O overhead for the thread block.Improving block- Historically,GPU scan implementations have primarily embodied wide scan efficiency beyond this point may reduce power one of three radix-b strategies at the global level:scan-then- consumption,but will not affect overall performance For propagate,reduce-then-scan,or chained-scan. traditional prefix-sum kemels,the block's I/O overhead is dictated by 2b data movement:b items read and written.For allocation and compaction scenarios,this efficiency constraint can be twice 2 This can also be considered a variation of the Han-Carlson network as tight if no output items are actually produced. In CUB,we construction [15]in which the root of a Brent-Kung construction is simply replaced with a Kogge-Stone network. treat the selection of local scan algorithm as a tuning parameter. Fig.2 illustrates several commonplace hybrid strategies for 3"Raking"is a parallel decomposition in which each thread consumes a block-wide scan.Their different circuit sizes and depths make non-overlapping partition of consecutive items.It is visually reminiscent ofthe tines of a rake being dragged at an angle along the ground [6]. 33 hybrid design strategies that efficiently utilize the entire hierarchy of multiprocessor and memory organization. 3. Contemporary GPU scan strategies Every GPU kernel is executed by a hierarchically-organized collection of threads. The individual threads executing the kernel function are grouped into thread blocks, and these blocks are grouped into kernel grids. The GPU uses thread blocks to efficiently manage the population of running threads on hardware multiprocessors (processor cores). Threads within the same block can cooperate through fast on-chip scratch memory and barrier synchronization. Prefix scan implementations designed for GPUs are typically constructed from two levels of organization: (1) a global, coarsegrained strategy for computing a device-wide scan using radix-b sub-networks for {reduction | scan | propagation}; and (2) a set of local, fine-grained strategies for computing b-input {reduction | scan | propagation} within each thread block. We discuss the latter first. 3.1 Block-wide scan strategies The blocking factor b is a function of thread block size and thread grain size, both of which are constrained by the physical resources of the multiprocessor and can be considered tunable constants. In practice, the tiles of block input are typically several thousand items each (e.g., b = 2048 items for 128 threads with 16 items per thread). Thus tile size b is uncorrelated to global input size n, and the asymptotic work-(in)efficiency of any particular block-wide scan construction will not affect that of the global strategy. Because we desire memory-bound kernels, the primary performance goal of any underlying block-wide strategy is to be efficient enough such that the local computational overhead (interthread communication, synchronization, and scan operators) can be absorbed by an oversubscribed memory subsystem. In other words, the computational overhead for block-wide scan must be less than the I/O overhead for the thread block. Improving blockwide scan efficiency beyond this point may reduce power consumption, but will not affect overall performance. For traditional prefix-sum kernels, the block’s I/O overhead is dictated by 2b data movement: b items read and written. For allocation and compaction scenarios, this efficiency constraint can be twice as tight if no output items are actually produced. In CUB, we treat the selection of local scan algorithm as a tuning parameter. Fig. 2 illustrates several commonplace hybrid strategies for block-wide scan. Their different circuit sizes and depths make each suitable for different-sized data types and scan operators of different complexities. For illustrative purposes, we depict blocks of 16 threads comprised of 4-thread SIMD warps, with one item per thread. Increasing the thread-granularity would entail wrapping the constructs with an outer layer of serial intra-thread reductions and scans. Dotted lines indicate barrier-synchronized communication through shared-memory. Fig. 2a presents a radix-4 Brent-Kung scan-then-propagate strategy that embeds 4-item Kogge-Stone warpscans and propagation fans. At the root of the hourglass, one of the warps is repurposed to warpscan the partial totals from each warp2 . Only two block-wide barriers are needed if the width of the SIMD warp is greater than the number of warps in the block. This block-wide scan technique was first demonstrated in CUDPP [23] and is one of several block-scan components available in CUB [21]. In this example, the depth is 5 levels and size is 37 operators. Fig. 2b presents a radix-4 “raking” reduce-then-scan strategy in which the entire computation is delegated to a single warp 3 . With 4 items per thread, the delegate warp performs efficient serial upsweep and downsweep networks within the registers of each thread. The root of the hourglass comprises a Kogge-Stone warpscan. Only two block-wide barriers are needed. This type of raking block-wide scan technique was first demonstrated in MatrixScan [12] and is one of several block-scan components available in CUB [21]. Although the network is relatively deep (9 levels), this approach exhibits minimal inter-thread communication and is very efficient (only 29 operators). Fig. 2c presents a radix-4 Sklansky strategy in which 4-input Kogge-Stone warpscans are coupled with 4-output Sklansky fan propagation. It is also provided as a block-scan component within CUB [21]. Unlike the previous two strategies, the number of block-wide barriers increases with the log of the number of warps. In this example, the depth is 4 levels and size is 36 operators. 3.2 Global scan strategies Historically, GPU scan implementations have primarily embodied one of three radix-b strategies at the global level: scan-thenpropagate, reduce-then-scan, or chained-scan. 2 This can also be considered a variation of the Han-Carlson network construction [15] in which the root of a Brent-Kung construction is simply replaced with a Kogge-Stone network. 3 “Raking” is a parallel decomposition in which each thread consumes a non-overlapping partition of consecutive items. It is visually reminiscent of the tines of a rake being dragged at an angle along the ground [6]. (a) A radix-4 Brent-Kung scan-then-propagate strategy embedding Kogge-Stone warpscans and propagation fans (b) A raking radix-4 reduce-then-scan strategy embedding serial reductions, serial scans, and a Kogge-Stone warpscan at the root (c) A radix-4 Sklansky strategy embedding Kogge-Stone warpscans and propagation fans Fig. 2. GPU hybrid block-scan strategies for n = 16 and SIMD warp size 4. Rounded boxes illustrate warp assignments. x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x0 :x0 x0 :x1 x0 :x2 x0 :x3 x0 :x4 x0 :x5 x0 :x6 x0 :x7 x0 :x8 x0 :x9 x0 :x10x0 :x11 x0 :x12x0 :x13 x0 :x14x0 :x15 barrier barrier x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x0 :x0 x0 :x1 x0 :x2 x0 :x3 x0 :x4 x0 :x5 x0 :x6 x0 :x7 x0 :x8 x0 :x9 x0 :x10x0 :x11 x0 :x12x0 :x13 x0 :x14x0 :x15 x12 x13 x14 x15 barrier barrier x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x0 :x0 x0 :x1 x0 :x2 x0 :x3 x0 :x4 x0 :x5 x0 :x6 x0 :x7 x0 :x8 x0 :x9 x0 :x10x0 :x11 x0 :x12x0 :x13 x0 :x14x0 :x15 barrier barrier