正在加载图片...
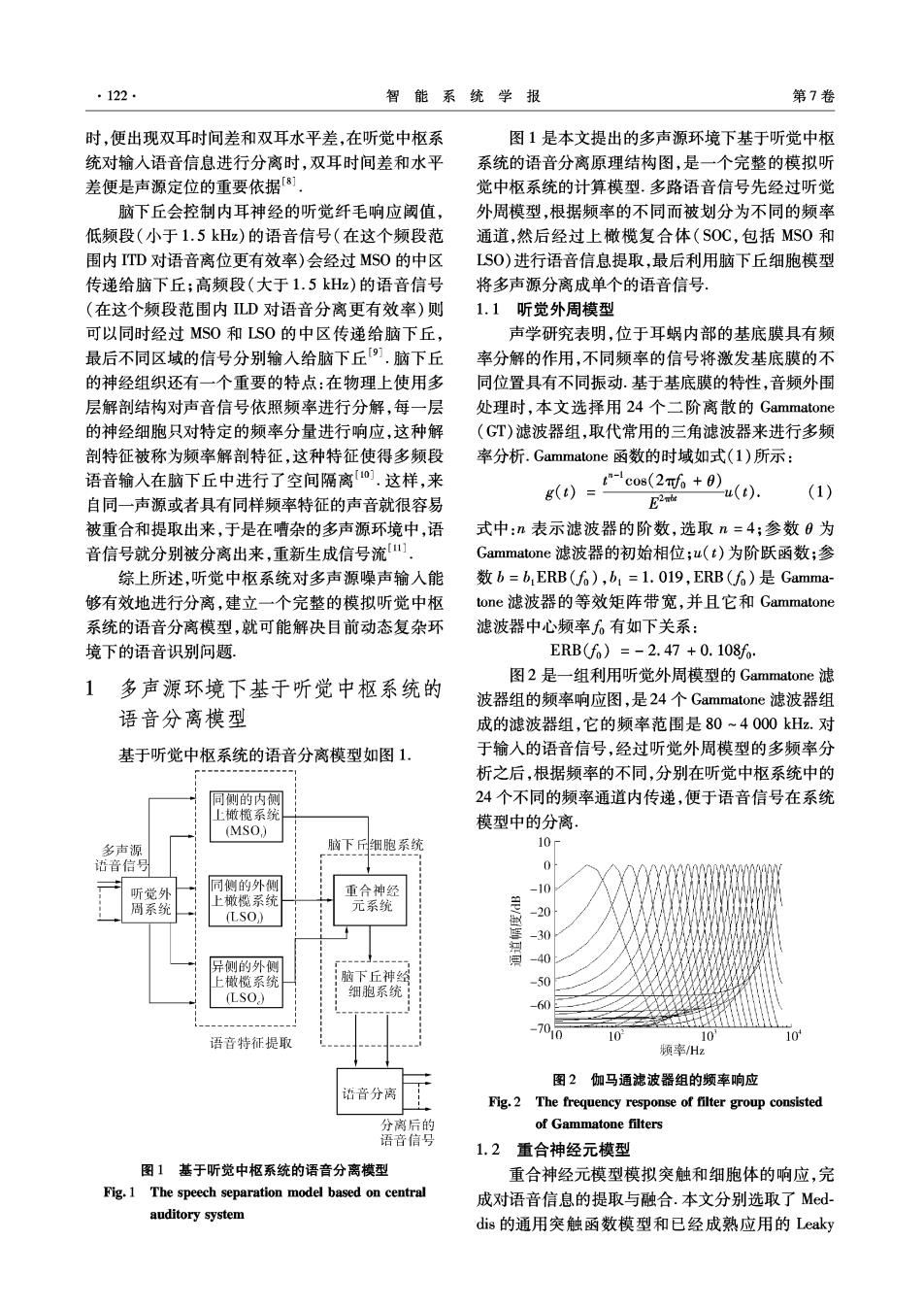
122, 智能系统学报 第7卷 时,便出现双耳时间差和双耳水平差,在听觉中枢系 图1是本文提出的多声源环境下基于听觉中枢 统对输入语音信息进行分离时,双耳时间差和水平 系统的语音分离原理结构图,是一个完整的模拟听 差便是声源定位的重要依据「8] 觉中枢系统的计算模型.多路语音信号先经过听觉 脑下丘会控制内耳神经的听觉纤毛响应阈值, 外周模型,根据频率的不同而被划分为不同的频率 低频段(小于1.5kHz)的语音信号(在这个频段范 通道,然后经过上橄榄复合体(SOC,包括MS0和 围内TD对语音离位更有效率)会经过MS0的中区 LS0)进行语音信息提取,最后利用脑下丘细胞模型 传递给脑下丘;高频段(大于1.5kHz)的语音信号 将多声源分离成单个的语音信号。 (在这个频段范围内LD对语音分离更有效率)则 1.1听觉外周模型 可以同时经过MS0和LS0的中区传递给脑下丘, 声学研究表明,位于耳蜗内部的基底膜具有频 最后不同区域的信号分别输入给脑下丘9.脑下丘 率分解的作用,不同频率的信号将激发基底膜的不 的神经组织还有一个重要的特点:在物理上使用多 同位置具有不同振动.基于基底膜的特性,音频外围 层解剖结构对声音信号依照频率进行分解,每一层 处理时,本文选择用24个二阶离散的Gammatone 的神经细胞只对特定的频率分量进行响应,这种解 (GT)滤波器组,取代常用的三角滤波器来进行多频 剖特征被称为频率解剖特征,这种特征使得多频段 率分析.Gammatone函数的时域如式(l)所示: 语音输入在脑下丘中进行了空间隔离0].这样,来 g(0)=cos(26+0 B2nbe u(t) (1) 自同一声源或者具有同样频率特征的声音就很容易 被重合和提取出来,于是在嘈杂的多声源环境中,语 式中:n表示滤波器的阶数,选取n=4;参数0为 音信号就分别被分离出来,重新生成信号流 Gammatone滤波器的初始相位;u(t)为阶跃函数;参 综上所述,听觉中枢系统对多声源噪声输入能 数b=b,ERB(f6),b1=1.019,ERB(f6)是Gamma- 够有效地进行分离,建立一个完整的模拟听觉中枢 tone滤波器的等效矩阵带宽,并且它和Gammatone 系统的语音分离模型,就可能解决目前动态复杂环 滤波器中心频率6有如下关系: 境下的语音识别问题, ERB(f6)=-2.47+0.108f: 图2是一组利用听觉外周模型的Gammatone滤 1多声源环境下基于听觉中枢系统的 波器组的频率响应图,是24个Gammatone滤波器组 语音分离模型 成的滤波器组,它的频率范围是80~4000kHz.对 基于听觉中枢系统的语音分离模型如图1. 于输入的语音信号,经过听觉外周模型的多频率分 析之后,根据频率的不同,分别在听觉中枢系统中的 同侧的内侧 24个不同的频率通道内传递,便于语音信号在系统 上橄榄系究 模型中的分离 (MSO) 多声源 脑下细胞系统 10- 话音信号 0 听觉外 同侧的外侧 重合神经 -10 周系统 上橄横系统 元系统 (LSO,) -20 -30 异侧的外侧 调 -40 上橄榄系统 脑下丘神给 -50 (LSO.) 细胞系统 -60 1010 语音特征提取 10 10 10 频率/Hz 图2伽马通滤波器组的频率响应 语音分离 Fig.2 The frequency response of filter group consisted 分离后的 of Gammatone filters 语音信号 1.2重合神经元模型 图1基于听觉中枢系统的语音分离模型 重合神经元模型模拟突触和细胞体的响应,完 Fig.1 The speech separation model based on central 成对语音信息的提取与融合.本文分别选取了Med- auditory system dis的通用突触函数模型和已经成熟应用的Leaky