正在加载图片...
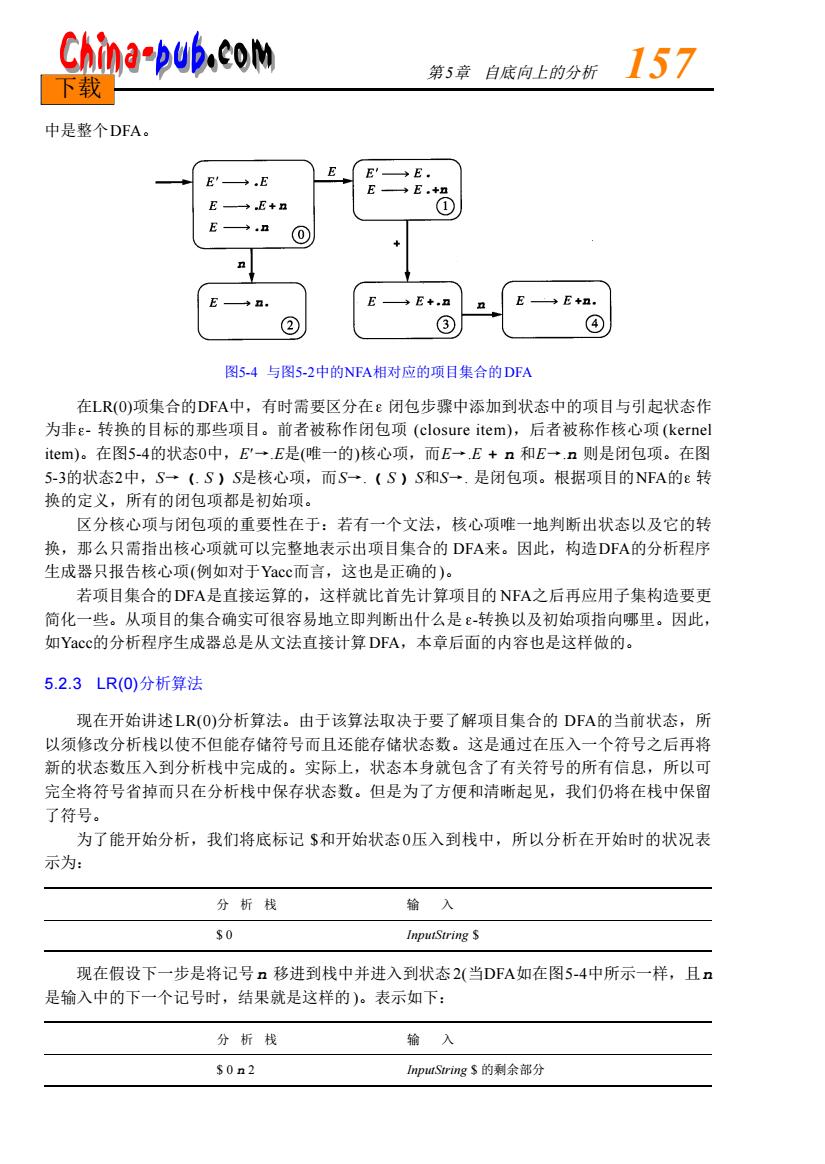
China-pub.com 第5章自底向上的分析 157 下载 中是整个DFA .E E E'→E (0 4E+,a ③ ④ 图5-4与图5-2中的NFA相对应的项目集合的DFA 在LR(O)项集合的DFA中,有时需要区分在E闭包步骤中添加到状态中的项目与引起状态作 为非e-转换的目标的那些项目。前者被称作闭包项(closure item),后者被称作核心项(kernel item)。在图5-4的状态0中,E'一E是(唯一的)核心项,而E一E+n和E,n则是闭包项。在图 53的状态2中,S一(.S)S是核心项,而S一.(S)S和S一.是闭包项。根据项目的NFA的E转 换的定义,所有的闭包项都是初始项。 区分核心项与闭包项的重要性在于:若有一个文法,核心项唯一地判断出状态以及它的转 换,那么只需指出核心项就可以完整地表示出项目集合的DFA来。因此,构造DFA的分析程序 生成器只报告核心项(例如对于Yacc而言,这也是正确的)。 若项目集合的DFA是直接运算的,这样就比首先计算项目的NFA之后再应用子集构造要更 简化一些。从项目的集合确实可很容易地立即判断出什么是-转换以及初始项指向哪里。因此, 如Yacc的分析程序生成器总是从文法直接计算DFA,本章后面的内容也是这样做的。 5.2.3LR(0)分析算法 现在开始讲述LR(O)分析算法。由于该算法取决于要了解项目集合的DFA的当前状态,所 以须修改分析栈以使不但能存储符号而且还能存储状态数。这是通过在压入一个符号之后再将 新的状态数压入到分析栈中完成的。实际上,状态本身就包含了有关符号的所有信息,所以可 完全将符号省掉而只在分析栈中保存状态数。但是为了方便和清晰起见,我们仍将在栈中保留 了符号。 为了能开始分析,我们将底标记$和开始状态0压入到栈中,所以分析在开始时的状况表 示为 分析栈 输入 InputString S 现在假设下一步是将记号n移进到栈中并进入到状态2(当DFA如在图5-4中所示一样,且n 是输入中的下一个记号时,结果就是这样的)。表示如下: 分析栈 输入 的剩余部分中是整个D FA。 图5-4 与图5 - 2中的N FA相对应的项目集合的D FA 在L R ( 0 )项集合的D FA中,有时需要区分在 闭包步骤中添加到状态中的项目与引起状态作 为非 - 转换的目标的那些项目。前者被称作闭包项 (closure item),后者被称作核心项 ( k e r n e l i t e m )。在图5 - 4的状态0中,E¢→.E是(唯一的)核心项,而E→.E + n 和E→.n 则是闭包项。在图 5 - 3的状态2中,S→ (. S ) S是核心项,而S→. ( S ) S和S→. 是闭包项。根据项目的N FA的 转 换的定义,所有的闭包项都是初始项。 区分核心项与闭包项的重要性在于:若有一个文法,核心项唯一地判断出状态以及它的转 换,那么只需指出核心项就可以完整地表示出项目集合的 D FA来。因此,构造D FA的分析程序 生成器只报告核心项(例如对于Ya c c而言,这也是正确的)。 若项目集合的D FA是直接运算的,这样就比首先计算项目的 N FA之后再应用子集构造要更 简化一些。从项目的集合确实可很容易地立即判断出什么是 -转换以及初始项指向哪里。因此, 如Ya c c的分析程序生成器总是从文法直接计算D FA,本章后面的内容也是这样做的。 5.2.3 LR(0)分析算法 现在开始讲述L R ( 0 )分析算法。由于该算法取决于要了解项目集合的 D FA的当前状态,所 以须修改分析栈以使不但能存储符号而且还能存储状态数。这是通过在压入一个符号之后再将 新的状态数压入到分析栈中完成的。实际上,状态本身就包含了有关符号的所有信息,所以可 完全将符号省掉而只在分析栈中保存状态数。但是为了方便和清晰起见,我们仍将在栈中保留 了符号。 为了能开始分析,我们将底标记 $和开始状态0压入到栈中,所以分析在开始时的状况表 示为: 分 析 栈 输 入 $ 0 InputString $ 现在假设下一步是将记号n 移进到栈中并进入到状态2 (当D FA如在图5 - 4中所示一样,且n 是输入中的下一个记号时,结果就是这样的 )。表示如下: 分 析 栈 输 入 $ 0 n 2 InputString $ 的剩余部分 第 5章 自底向上的分析 1 5 7 下载