正在加载图片...
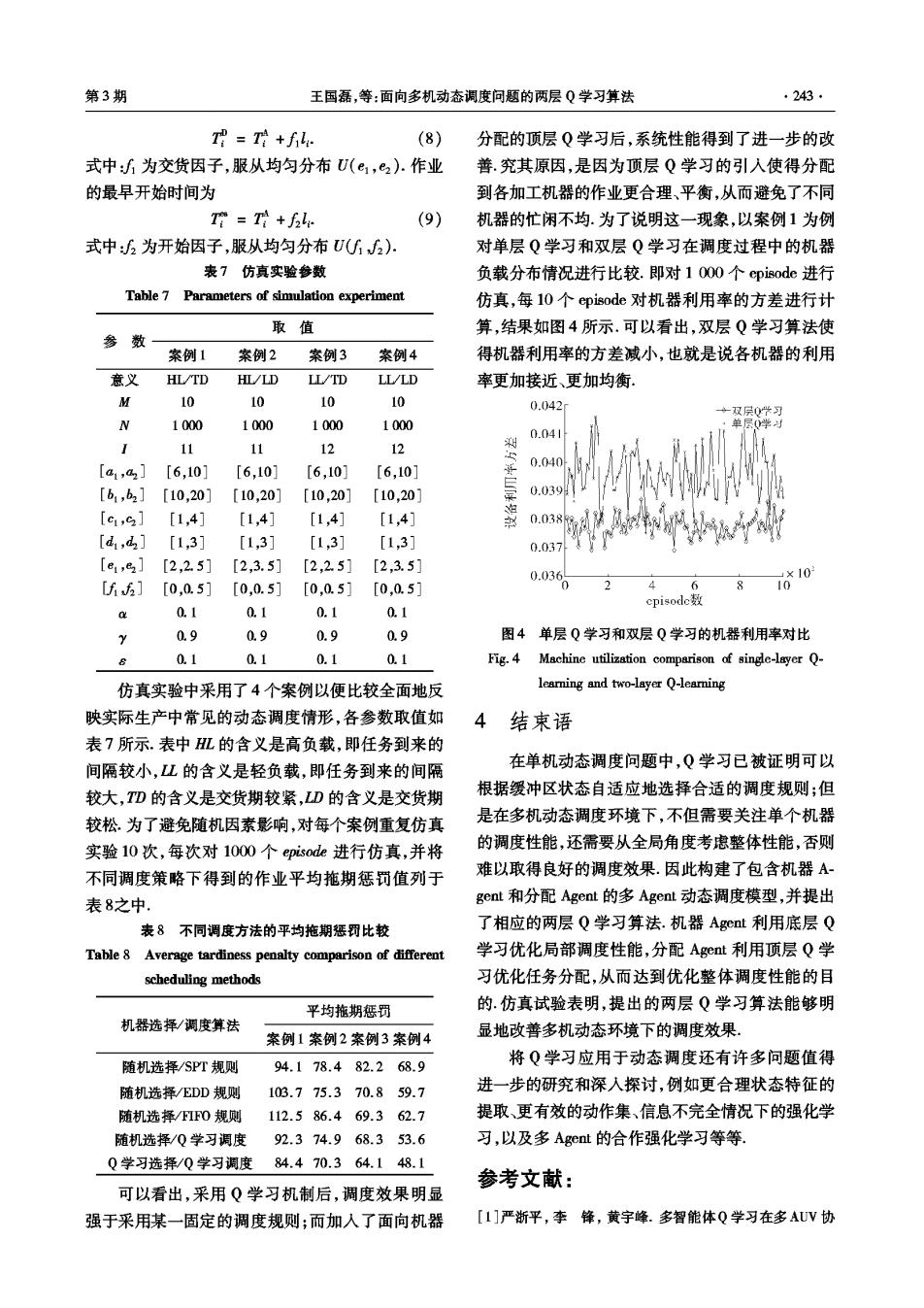
第3期 王国磊,等:面向多机动态调度问题的两层Q学习算法 .243 T母=+f: (8) 分配的顶层Q学习后,系统性能得到了进一步的改 式中:为交货因子,服从均匀分布U(e,e2).作业 善.究其原因,是因为顶层Q学习的引入使得分配 的最早开始时间为 到各加工机器的作业更合理、平衡,从而避免了不同 T=+f: (9) 机器的忙闲不均.为了说明这一现象,以案例1为例 式中:为开始因子,服从均匀分布U(2) 对单层Q学习和双层Q学习在调度过程中的机器 表7仿真实验参数 负载分布情况进行比较.即对10O0个episode进行 Table 7 Parameters of simulation experiment 仿真,每10个episode对机器利用率的方差进行计 取值 算,结果如图4所示.可以看出,双层Q学习算法使 参 数 案例1 案例2 案例3 案例4 得机器利用率的方差减小,也就是说各机器的利用 意义 HL/TD HL/LD LL/TD LL/LD 率更加接近、更加均衡 M 10 10 10 10 0.042 ·双层0此习 N 1000 1000 1000 1000 0学为 0.04 11 11 12 12 [a1,a2] [6,10] [6,10] [6,10] [6,10] 0.040 [b1,b2] [10,20] [10,20] [10,20] [10,20] .39 [c1,9] [1,4] [1,41 [1,4] [1,4] 0.038: [d,d] [1,3] [1,3] [1,3] [1,3] 0.037 [e1,82] [2,2.5] [2,3.5] [2,2.5] [2,3.5] 0.03 [f6] 「0.0.51 「0.0.51 [0,0.51 「0.0.51 0 10*10 cpisode数 a 0.1 0.1 0.1 0.1 2 0.9 0.9 0.9 0.9 图4单层Q学习和双层Q学习的机器利用率对比 0.1 0.1 0.1 0.1 Fig.4 Machine utilization comparison of single-layer Q- 仿真实验中采用了4个案例以便比较全面地反 learning and two-layer Q-learning 映实际生产中常见的动态调度情形,各参数取值如 4 结束语 表7所示.表中HL的含义是高负载,即任务到来的 间隔较小,L的含义是轻负载,即任务到来的间隔 在单机动态调度问题中,Q学习已被证明可以 较大,TD的含义是交货期较紧,LD的含义是交货期 根据缓冲区状态自适应地选择合适的调度规则:但 较松.为了避免随机因素影响,对每个案例重复仿真 是在多机动态调度环境下,不但需要关注单个机器 实验10次,每次对1000个episode进行仿真,并将 的调度性能,还需要从全局角度考虑整体性能,否则 不同调度策略下得到的作业平均施期惩罚值列于 难以取得良好的调度效果.因此构建了包含机器A 表8之中 gent和分配Agent的多Agent动态调度模型,并提出 表8不同调度方法的平均拖期惩罚比较 了相应的两层Q学习算法.机器Agct利用底层Q Table 8 Average tardiness penalty comparison of different 学习优化局部调度性能,分配Aget利用顶层Q学 scheduling methods 习优化任务分配,从而达到优化整体调度性能的目 平均拖期惩罚 的.仿真试验表明,提出的两层Q学习算法能够明 机器选择/调度算法 案例1案例2案例3案例4 显地改善多机动态环境下的调度效果。 随机选择/SPT规则 94.178.482.268.9 将Q学习应用于动态调度还有许多问题值得 随机选择/EDD规则 103.775.370.859.7 进一步的研究和深入探讨,例如更合理状态特征的 随机选择/FIFO规则 112.586.469.362.7 提取、更有效的动作集、信息不完全情况下的强化学 随机选择/Q学习调度92.374.968.353.6 习,以及多Aget的合作强化学习等等 Q学习选择/Q学习调度84.470.364.148.1 参考文献: 可以看出,采用Q学习机制后,调度效果明显 强于采用某一固定的调度规则;而加入了面向机器 [1]严浙平,李锋,黄宇峰.多智能体Q学习在多AUV协