正在加载图片...
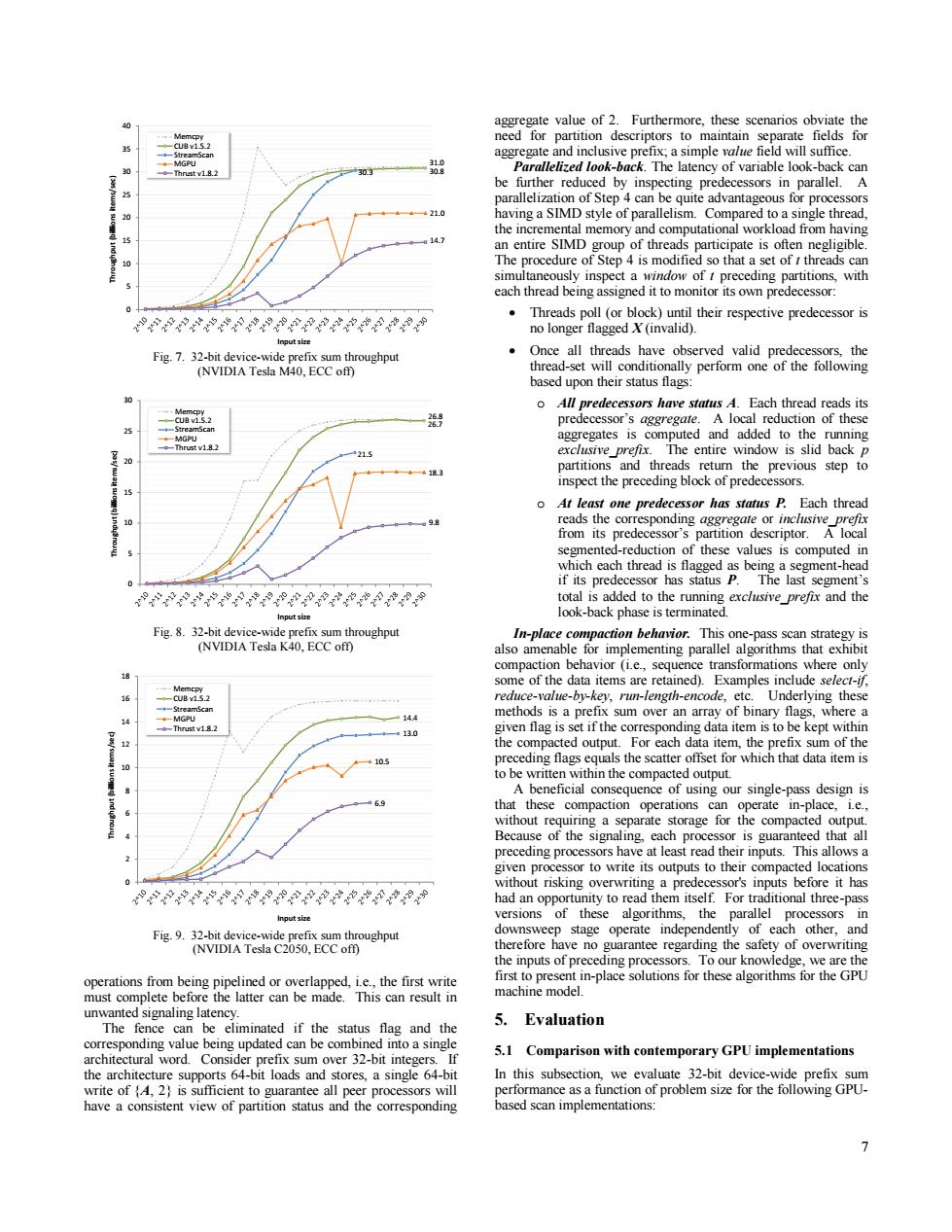
40 aggregate value of 2.Furthermore,these scenarios obviate the need for partition descriptors to maintain separate fields for 15 35 --StreamScan aggregate and inclusive prefix;a simple value field will suffice MGPU 30 Thrust v1.8.2 303 Parallelized look-back.The latency of variable look-back can be further reduced by inspecting predecessors in parallel.A parallelization of Step 4 can be quite advantageous for processors 421.0 having a SIMD style of parallelism.Compared to a single thread. the incremental memory and computational workload from having 14.7 an entire SIMD group of threads participate is often negligible. The procedure of Step 4 is modified so that a set of t threads can simultaneously inspect a window of t preceding partitions,with each thread being assigned it to monitor its own predecessor: Threads poll (or block)until their respective predecessor is e的9中 no longer flagged X(invalid). Fig.7.32-bit device-wide prefix sum throughput Once all threads have observed valid predecessors,the (NVIDIA Tesla M40.ECC off) thread-set will conditionally perform one of the following based upon their status flags: o All predecessors have status A.Each thread reads its predecessor's aggregate.A local reduction of these aggregates is computed and added to the running -Thrustv1.8.2 exclusive prefix.The entire window is slid back p partitions and threads return the previous step to -4183 inspect the preceding block of predecessors. o At least one predecessor has status P.Each thread 98 reads the corresponding aggregate or inclusive prefix from its predecessor's partition descriptor.A local segmented-reduction of these values is computed in which each thread is flagged as being a segment-head if its predecessor has status P.The last segment's 8 total is added to the running exclusive prefix and the Input size look-back phase is terminated Fig.8.32-bit device-wide prefix sum throughput In-place compaction behavior.This one-pass scan strategy is (NVIDIA Tesla K40,ECC off) also amenable for implementing parallel algorithms that exhibit compaction behavior (i.e.,sequence transformations where only some of the data items are retained).Examples include select-if, Memcpy -CUB v15.2 reduce-value-by-key,run-length-encode,etc.Underlying these -St山reamscan methods is a prefix sum over an array of binary flags,where a 14 MGPU -Thrust v1.8.2 130 given flag is set if the corresponding data item is to be kept within the compacted output.For each data item,the prefix sum of the 109 preceding flags equals the scatter offset for which that data item is 10 to be written within the compacted output. A beneficial consequence of using our single-pass design is 6e that these compaction operations can operate in-place,1.e., without requiring a separate storage for the compacted output. Because of the signaling,each processor is guaranteed that all preceding processors have at least read their inputs.This allows a given processor to write its outputs to their compacted locations without risking overwriting a predecessor's inputs before it has ee9的 had an opportunity to read them itself.For traditional three-pass Input size versions of these algorithms,the parallel processors in Fig.9.32-bit device-wide prefix sum throughput downsweep stage operate independently of each other,and (NVIDIA Tesla C2050,ECC off) therefore have no guarantee regarding the safety of overwriting the inputs of preceding processors.To our knowledge,we are the operations from being pipelined or overlapped,i.e.,the first write first to present in-place solutions for these algorithms for the GPU must complete before the latter can be made.This can result in machine model. unwanted signaling latency 5. Evaluation The fence can be eliminated if the status flag and the corresponding value being updated can be combined into a single 5.1 architectural word.Consider prefix sum over 32-bit integers.If Comparison with contemporary GPU implementations the architecture supports 64-bit loads and stores,a single 64-bit In this subsection,we evaluate 32-bit device-wide prefix sum write of 2)is sufficient to guarantee all peer processors will performance as a function of problem size for the following GPU- have a consistent view of partition status and the corresponding based scan implementations: >7 operations from being pipelined or overlapped, i.e., the first write must complete before the latter can be made. This can result in unwanted signaling latency. The fence can be eliminated if the status flag and the corresponding value being updated can be combined into a single architectural word. Consider prefix sum over 32-bit integers. If the architecture supports 64-bit loads and stores, a single 64-bit write of {A, 2} is sufficient to guarantee all peer processors will have a consistent view of partition status and the corresponding aggregate value of 2. Furthermore, these scenarios obviate the need for partition descriptors to maintain separate fields for aggregate and inclusive prefix; a simple value field will suffice. Parallelized look-back. The latency of variable look-back can be further reduced by inspecting predecessors in parallel. A parallelization of Step 4 can be quite advantageous for processors having a SIMD style of parallelism. Compared to a single thread, the incremental memory and computational workload from having an entire SIMD group of threads participate is often negligible. The procedure of Step 4 is modified so that a set of t threads can simultaneously inspect a window of t preceding partitions, with each thread being assigned it to monitor its own predecessor: Threads poll (or block) until their respective predecessor is no longer flagged X (invalid). Once all threads have observed valid predecessors, the thread-set will conditionally perform one of the following based upon their status flags: o All predecessors have status A. Each thread reads its predecessor’s aggregate. A local reduction of these aggregates is computed and added to the running exclusive_prefix. The entire window is slid back p partitions and threads return the previous step to inspect the preceding block of predecessors. o At least one predecessor has status P. Each thread reads the corresponding aggregate or inclusive_prefix from its predecessor’s partition descriptor. A local segmented-reduction of these values is computed in which each thread is flagged as being a segment-head if its predecessor has status P. The last segment’s total is added to the running exclusive_prefix and the look-back phase is terminated. In-place compaction behavior. This one-pass scan strategy is also amenable for implementing parallel algorithms that exhibit compaction behavior (i.e., sequence transformations where only some of the data items are retained). Examples include select-if, reduce-value-by-key, run-length-encode, etc. Underlying these methods is a prefix sum over an array of binary flags, where a given flag is set if the corresponding data item is to be kept within the compacted output. For each data item, the prefix sum of the preceding flags equals the scatter offset for which that data item is to be written within the compacted output. A beneficial consequence of using our single-pass design is that these compaction operations can operate in-place, i.e., without requiring a separate storage for the compacted output. Because of the signaling, each processor is guaranteed that all preceding processors have at least read their inputs. This allows a given processor to write its outputs to their compacted locations without risking overwriting a predecessor's inputs before it has had an opportunity to read them itself. For traditional three-pass versions of these algorithms, the parallel processors in downsweep stage operate independently of each other, and therefore have no guarantee regarding the safety of overwriting the inputs of preceding processors. To our knowledge, we are the first to present in-place solutions for these algorithms for the GPU machine model. 5. Evaluation 5.1 Comparison with contemporary GPU implementations In this subsection, we evaluate 32-bit device-wide prefix sum performance as a function of problem size for the following GPUbased scan implementations: Fig. 7. 32-bit device-wide prefix sum throughput (NVIDIA Tesla M40, ECC off) Fig. 8. 32-bit device-wide prefix sum throughput (NVIDIA Tesla K40, ECC off) Fig. 9. 32-bit device-wide prefix sum throughput (NVIDIA Tesla C2050, ECC off) 31.0 30.3 30.8 21.0 14.7 0 5 10 15 20 25 30 35 40 Throughput (billions items/sec) Input size Memcpy CUB v1.5.2 StreamScan MGPU Thrust v1.8.2 26.8 26.7 21.5 18.3 9.8 0 5 10 15 20 25 30 Throughput (billions items/sec) Input size Memcpy CUB v1.5.2 StreamScan MGPU Thrust v1.8.2 14.4 13.0 10.5 6.9 0 2 4 6 8 10 12 14 16 18 Throughput (billions items/sec) Input size Memcpy CUB v1.5.2 StreamScan MGPU Thrust v1.8.2