正在加载图片...
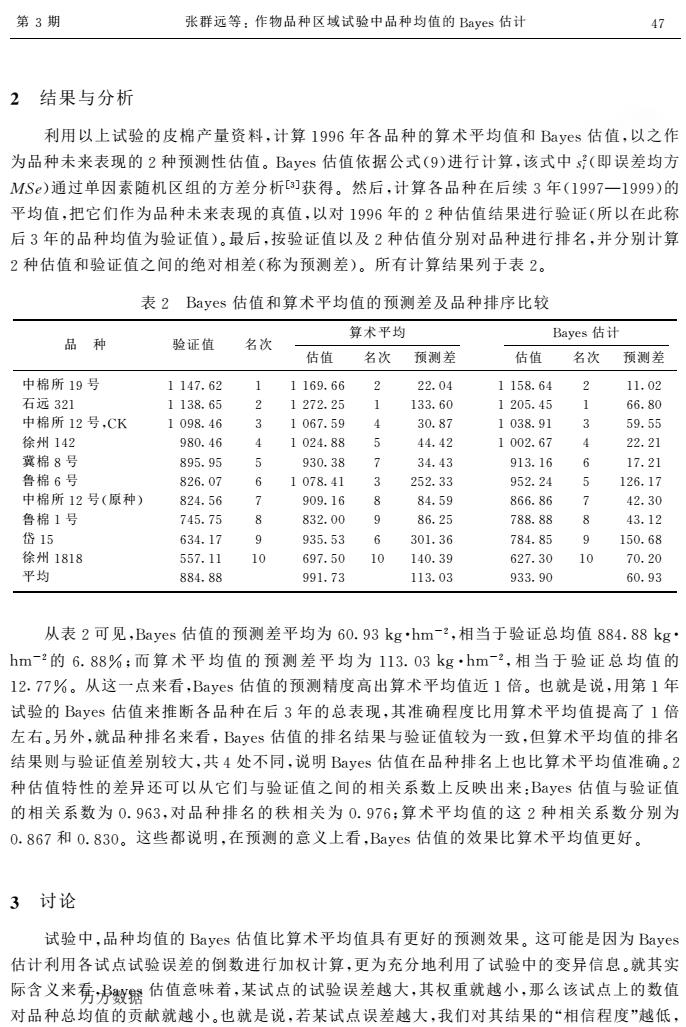
第3期 张群远等:作物品种区域试验中品种均值的Bayes估计 2结果与分析 利用以上试验的皮棉产量资料,计算1996年各品种的算术平均值和Bays估值,以之作 为品种未来表现的2种预测性估值。Bayes估值依据公式(9)进行计算,该式中s(即误差均方 MS)通过单因素随机区组的方差分析]获得。然后,计算各品种在后续3年(1997一1999)的 平均值,把它们作为品种未来表现的真值,以对1996年的2种估值结果进行验证(所以在此称 后3年的品种均值为验证值)。最后,按验证值以及2种估值分别对品种进行排名,并分别计算 2种估值和验证值之间的绝对相差(称为预测差)。所有计算结果列于表2。 表2 Bayes估值和算术平均值的预测差及品种排序比较 算术平均 Baves估计 品种 验证值 名次 估值名次预测差 估值 名次预测差 中棉所19号 1147.62 1169.66 2 22.04 1158.64 2 11.02 右远321 1138.65 2 1272.25 1 133.60 1205.45 1 66.80 中棉所12号,CK 1098.46 1067.59 30.87 1038.91 59.55 徐州142 980.46 1024.88 1002.67 冀棉8号 895.95 930.38 913.16 鲁棉6号 826.07 6 1078.41 252.33 952.24 126.17 中棉所12号(原种) 824.56 2 909.16 8 84.59 866.86 7 42.30 鲁棉1号 745.75 8 832.00 86.25 788.88 R 43.12 代15 634.17 0 935.53 6 36 4.85 8 150. 徐州1818 557.1 10 697.5 140.3 62.30 10 70.20 平均 884.88 991.73 113.03 933.90 60.93 从表2可见,Bayes估值的预测差平均为60.93kghm-2,相当于验证总均值884.88kg hm-的6.88%:而算术平均值的预测差平均为113.03kg·hm-2,相当于验证总均值的 12.77%。从这一点来看,Bayes估值的预测精度高出算术平均值近1倍。也就是说,用第1年 试验的Bayes估值来推断各品种在后3年的总表现,其准确程度比用算术平均值提高了1倍 左右。另外,就品种排名米看,Bayes估值的排名结果与验证值较为一致,但算术平均值的排名 结果则与验证值差别较大,共4处不同,说明Bayes估值在品种排名上也比算术平均值准确。2 种估值特性的差异还可以从它们与验证值之间的相关系数上反映出来:Bayes估值与验证值 的相关系数为0.963,对品种排名的秩相关为0.976:算术平均值的这2种相关系数分别为 0.867和0.830。这些都说明,在预测的意义上看,Bayes估值的效果比算术平均值更好。 3讨论 试验中,品种均值的Bayes估值比算术平均值具有更好的预测效果。这可能是因为Bayes 估计利用各试点试验误差的倒数进行加权计算,更为充分地利用了试验中的变异信息。就其实 际含义米秀乃数继估值意味着,某试点的试验误差越大,其权重就越小,那么该试点上的数值 对品种总均值的贡献就越小。也就是说,若某试点误差越大,我们对其结果的“相信程度”越低, ! 结果与分析 利用以上试验的皮棉产量资料"计算 #$$%年各品种的算术平均值和 &’()*估值"以之作 为品种未来表现的 +种预测性估值,&’()*估值依据公式-$.进行计算"该式中 / + 0-即误差均方 123.通过单因素随机区组的方差分析456获得,然后"计算各品种在后续 5年-#$$78#$$$.的 平均值"把它们作为品种未来表现的真值"以对 #$$%年的 +种估值结果进行验证-所以在此称 后 5年的品种均值为验证值.,最后"按验证值以及 +种估值分别对品种进行排名"并分别计算 +种估值和验证值之间的绝对相差-称为预测差.,所有计算结果列于表 +, 表 + &’()*估值和算术平均值的预测差及品种排序比较 品 种 验证值 名次 算术平均 &’()*估计 估值 名次 预测差 估值 名次 预测差 中棉所 #$号 ##97:%+ # ##%$:%% + ++:;9 ##<=:%9 + ##:;+ 石远 5+# ##5=:%< + #+7+:+< # #55:%; #+;<:9< # %%:=; 中棉所 #+号">? #;$=:9% 5 #;%7:<$ 9 5;:=7 #;5=:$# 5 <$:<< 徐州 #9+ $=;:9% 9 #;+9:== < 99:9+ #;;+:%7 9 ++:+# 冀棉 =号 =$<:$< < $5;:5= 7 59:95 $#5:#% % #7:+# 鲁棉 %号 =+%:;7 % #;7=:9# 5 +<+:55 $<+:+9 < #+%:#7 中棉所 #+号-原种. =+9:<% 7 $;$:#% = =9:<$ =%%:=% 7 9+:5; 鲁棉 #号 79<:7< = =5+:;; $ =%:+< 7==:== = 95:#+ 岱 #< %59:#7 $ $5<:<5 % 5;#:5% 7=9:=< $ #<;:%= 徐州 #=#= <<7:## #; %$7:<; #; #9;:5$ %+7:5; #; 7;:+; 平均 ==9:== $$#:75 ##5:;5 $55:$; %;:$5 从表 +可见"&’()*估值的预测差平均为 %;:$5@ABCDE+ "相当于验证总均值 ==9:==@AB CDE+的 %:==FG而 算 术 平 均 值 的 预 测 差 平 均 为 ##5:;5@ABCDE+ "相 当 于 验 证 总 均 值 的 #+H77F,从这一点来看"&’()*估值的预测精度高出算术平均值近 #倍,也就是说"用第 #年 试验的 &’()*估值来推断各品种在后 5年的总表现"其准确程度比用算术平均值提高了 #倍 左右,另外"就品种排名来看"&’()*估值的排名结果与验证值较为一致"但算术平均值的排名 结果则与验证值差别较大"共 9处不同"说明 &’()*估值在品种排名上也比算术平均值准确,+ 种估值特性的差异还可以从它们与验证值之间的相关系数上反映出来I&’()*估值与验证值 的相关系数为 ;:$%5"对品种排名的秩相关为 ;:$7%G算术平均值的这 +种相关系数分别为 ;H=%7和 ;:=5;,这些都说明"在预测的意义上看"&’()*估值的效果比算术平均值更好, J 讨论 试验中"品种均值的 &’()*估值比算术平均值具有更好的预测效果,这可能是因为 &’()* 估计利用各试点试验误差的倒数进行加权计算"更为充分地利用了试验中的变异信息,就其实 际含义来看"&’()*估值意味着"某试点的试验误差越大"其权重就越小"那么该试点上的数值 对品种总均值的贡献就越小,也就是说"若某试点误差越大"我们对其结果的K相信程度L越低" 第 5期 张群远等I作物品种区域试验中品种均值的 &’()*估计 97 万方数据