正在加载图片...
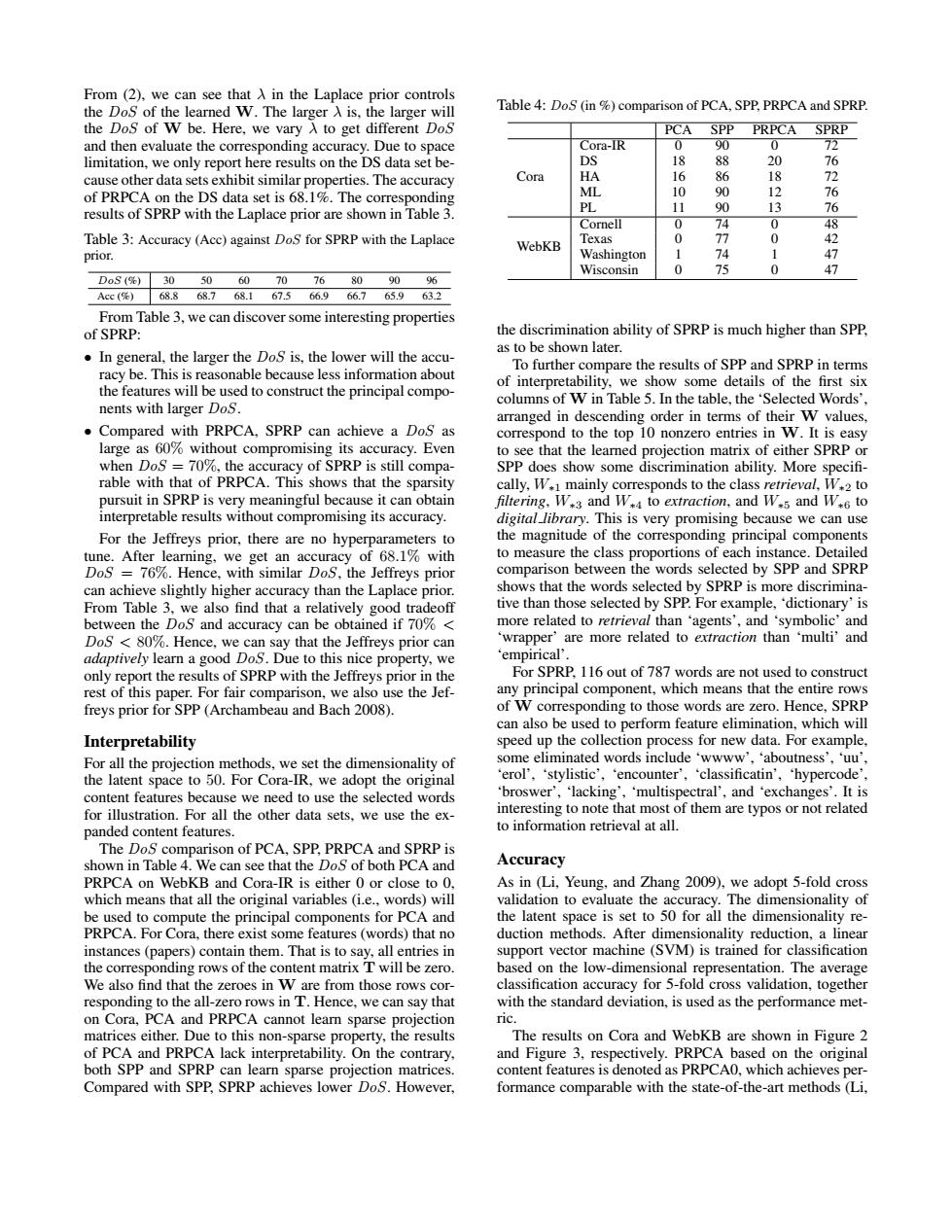
From(2).we can see that A in the Laplace prior controls the DoS of the learned W.The larger A is,the larger will Table 4:DoS (in %comparison of PCA,SPP.PRPCA and SPRP. the DoS of W be.Here,we vary A to get different DoS PCA SPP PRPCA SPRP and then evaluate the corresponding accuracy.Due to space Cora-IR 0 90 0 72 limitation,we only report here results on the DS data set be- DS 18 88 20 76 cause other data sets exhibit similar properties.The accuracy Cora HA 16 86 18 72 of PRPCA on the DS data set is 68.1%.The corresponding M 10 90 12 76 results of SPRP with the Laplace prior are shown in Table 3. PL 11 90 13 76 Cornell 0 74 0 48 Table 3:Accuracy(Acc)against DoS for SPRP with the Laplace Texas 0 77 0 WebKB 2 prior. Washington 74 1 47 Wisconsin 0 75 0 47 DoS(%)305060 707680 9096 Acc(%)68.868.768.167.566.966.7 65.963.2 From Table 3,we can discover some interesting properties of SPRP: the discrimination ability of SPRP is much higher than SPP, as to be shown later. In general,the larger the DoS is,the lower will the accu- racy be.This is reasonable because less information about To further compare the results of SPP and SPRP in terms of interpretability,we show some details of the first six the features will be used to construct the principal compo- columns of W in Table 5.In the table,the 'Selected Words'. nents with larger DoS. arranged in descending order in terms of their W values, Compared with PRPCA,SPRP can achieve a DoS as correspond to the top 10 nonzero entries in W.It is easy large as 60%without compromising its accuracy.Even to see that the learned projection matrix of either SPRP or when DoS =70%,the accuracy of SPRP is still compa- SPP does show some discrimination ability.More specifi- rable with that of PRPCA.This shows that the sparsity cally,W.mainly corresponds to the class retrieval,W.2 to pursuit in SPRP is very meaningful because it can obtain filtering,W.3 and W,4 to extraction,and W.5 and W.6 to interpretable results without compromising its accuracy. digital_library.This is very promising because we can use For the Jeffreys prior,there are no hyperparameters to the magnitude of the corresponding principal components tune.After learning,we get an accuracy of 68.1%with to measure the class proportions of each instance.Detailed DoS =76%.Hence,with similar DoS,the Jeffreys prior comparison between the words selected by SPP and SPRP can achieve slightly higher accuracy than the Laplace prior. shows that the words selected by SPRP is more discrimina- From Table 3,we also find that a relatively good tradeoff tive than those selected by SPP.For example,'dictionary'is between the DoS and accuracy can be obtained if 70%< more related to retrieval than 'agents',and 'symbolic'and DoS 80%.Hence,we can say that the Jeffreys prior can wrapper'are more related to extraction than 'multi'and adaptively learn a good DoS.Due to this nice property,we empirical'. only report the results of SPRP with the Jeffreys prior in the For SPRP.116 out of 787 words are not used to construct rest of this paper.For fair comparison,we also use the Jef- any principal component,which means that the entire rows freys prior for SPP(Archambeau and Bach 2008). of W corresponding to those words are zero.Hence,SPRP can also be used to perform feature elimination,which will Interpretability speed up the collection process for new data.For example, For all the projection methods,we set the dimensionality of some eliminated words include 'wwww',aboutness','uu' the latent space to 50.For Cora-IR,we adopt the original erol','stylistic','encounter','classificatin','hypercode' content features because we need to use the selected words broswer','lacking','multispectral',and 'exchanges'.It is for illustration.For all the other data sets.we use the ex- interesting to note that most of them are typos or not related panded content features. to information retrieval at all. The DoS comparison of PCA,SPP,PRPCA and SPRP is shown in Table 4.We can see that the DoS of both PCA and Accuracy PRPCA on WebKB and Cora-IR is either 0 or close to 0. As in (Li,Yeung,and Zhang 2009),we adopt 5-fold cross which means that all the original variables (i.e.,words)will validation to evaluate the accuracy.The dimensionality of be used to compute the principal components for PCA and the latent space is set to 50 for all the dimensionality re- PRPCA.For Cora,there exist some features (words)that no duction methods.After dimensionality reduction,a linear instances (papers)contain them.That is to say,all entries in support vector machine (SVM)is trained for classification the corresponding rows of the content matrix T will be zero. based on the low-dimensional representation.The average We also find that the zeroes in W are from those rows cor- classification accuracy for 5-fold cross validation,together responding to the all-zero rows in T.Hence,we can say that with the standard deviation,is used as the performance met- on Cora,PCA and PRPCA cannot learn sparse projection ric matrices either.Due to this non-sparse property,the results The results on Cora and WebKB are shown in Figure 2 of PCA and PRPCA lack interpretability.On the contrary, and Figure 3,respectively.PRPCA based on the original both SPP and SPRP can learn sparse projection matrices content features is denoted as PRPCA0,which achieves per- Compared with SPP,SPRP achieves lower DoS.However, formance comparable with the state-of-the-art methods (Li,From (2), we can see that λ in the Laplace prior controls the DoS of the learned W. The larger λ is, the larger will the DoS of W be. Here, we vary λ to get different DoS and then evaluate the corresponding accuracy. Due to space limitation, we only report here results on the DS data set because other data sets exhibit similar properties. The accuracy of PRPCA on the DS data set is 68.1%. The corresponding results of SPRP with the Laplace prior are shown in Table 3. Table 3: Accuracy (Acc) against DoS for SPRP with the Laplace prior. DoS (%) 30 50 60 70 76 80 90 96 Acc (%) 68.8 68.7 68.1 67.5 66.9 66.7 65.9 63.2 From Table 3, we can discover some interesting properties of SPRP: • In general, the larger the DoS is, the lower will the accuracy be. This is reasonable because less information about the features will be used to construct the principal components with larger DoS. • Compared with PRPCA, SPRP can achieve a DoS as large as 60% without compromising its accuracy. Even when DoS = 70%, the accuracy of SPRP is still comparable with that of PRPCA. This shows that the sparsity pursuit in SPRP is very meaningful because it can obtain interpretable results without compromising its accuracy. For the Jeffreys prior, there are no hyperparameters to tune. After learning, we get an accuracy of 68.1% with DoS = 76%. Hence, with similar DoS, the Jeffreys prior can achieve slightly higher accuracy than the Laplace prior. From Table 3, we also find that a relatively good tradeoff between the DoS and accuracy can be obtained if 70% < DoS < 80%. Hence, we can say that the Jeffreys prior can adaptively learn a good DoS. Due to this nice property, we only report the results of SPRP with the Jeffreys prior in the rest of this paper. For fair comparison, we also use the Jeffreys prior for SPP (Archambeau and Bach 2008). Interpretability For all the projection methods, we set the dimensionality of the latent space to 50. For Cora-IR, we adopt the original content features because we need to use the selected words for illustration. For all the other data sets, we use the expanded content features. The DoS comparison of PCA, SPP, PRPCA and SPRP is shown in Table 4. We can see that the DoS of both PCA and PRPCA on WebKB and Cora-IR is either 0 or close to 0, which means that all the original variables (i.e., words) will be used to compute the principal components for PCA and PRPCA. For Cora, there exist some features (words) that no instances (papers) contain them. That is to say, all entries in the corresponding rows of the content matrix T will be zero. We also find that the zeroes in W are from those rows corresponding to the all-zero rows in T. Hence, we can say that on Cora, PCA and PRPCA cannot learn sparse projection matrices either. Due to this non-sparse property, the results of PCA and PRPCA lack interpretability. On the contrary, both SPP and SPRP can learn sparse projection matrices. Compared with SPP, SPRP achieves lower DoS. However, Table 4: DoS (in %) comparison of PCA, SPP, PRPCA and SPRP. PCA SPP PRPCA SPRP Cora Cora-IR 0 90 0 72 DS 18 88 20 76 HA 16 86 18 72 ML 10 90 12 76 PL 11 90 13 76 WebKB Cornell 0 74 0 48 Texas 0 77 0 42 Washington 1 74 1 47 Wisconsin 0 75 0 47 the discrimination ability of SPRP is much higher than SPP, as to be shown later. To further compare the results of SPP and SPRP in terms of interpretability, we show some details of the first six columns of W in Table 5. In the table, the ‘Selected Words’, arranged in descending order in terms of their W values, correspond to the top 10 nonzero entries in W. It is easy to see that the learned projection matrix of either SPRP or SPP does show some discrimination ability. More specifi- cally, W∗1 mainly corresponds to the class retrieval, W∗2 to filtering, W∗3 and W∗4 to extraction, and W∗5 and W∗6 to digital library. This is very promising because we can use the magnitude of the corresponding principal components to measure the class proportions of each instance. Detailed comparison between the words selected by SPP and SPRP shows that the words selected by SPRP is more discriminative than those selected by SPP. For example, ‘dictionary’ is more related to retrieval than ‘agents’, and ‘symbolic’ and ‘wrapper’ are more related to extraction than ‘multi’ and ‘empirical’. For SPRP, 116 out of 787 words are not used to construct any principal component, which means that the entire rows of W corresponding to those words are zero. Hence, SPRP can also be used to perform feature elimination, which will speed up the collection process for new data. For example, some eliminated words include ‘wwww’, ‘aboutness’, ‘uu’, ‘erol’, ‘stylistic’, ‘encounter’, ‘classificatin’, ‘hypercode’, ‘broswer’, ‘lacking’, ‘multispectral’, and ‘exchanges’. It is interesting to note that most of them are typos or not related to information retrieval at all. Accuracy As in (Li, Yeung, and Zhang 2009), we adopt 5-fold cross validation to evaluate the accuracy. The dimensionality of the latent space is set to 50 for all the dimensionality reduction methods. After dimensionality reduction, a linear support vector machine (SVM) is trained for classification based on the low-dimensional representation. The average classification accuracy for 5-fold cross validation, together with the standard deviation, is used as the performance metric. The results on Cora and WebKB are shown in Figure 2 and Figure 3, respectively. PRPCA based on the original content features is denoted as PRPCA0, which achieves performance comparable with the state-of-the-art methods (Li