正在加载图片...
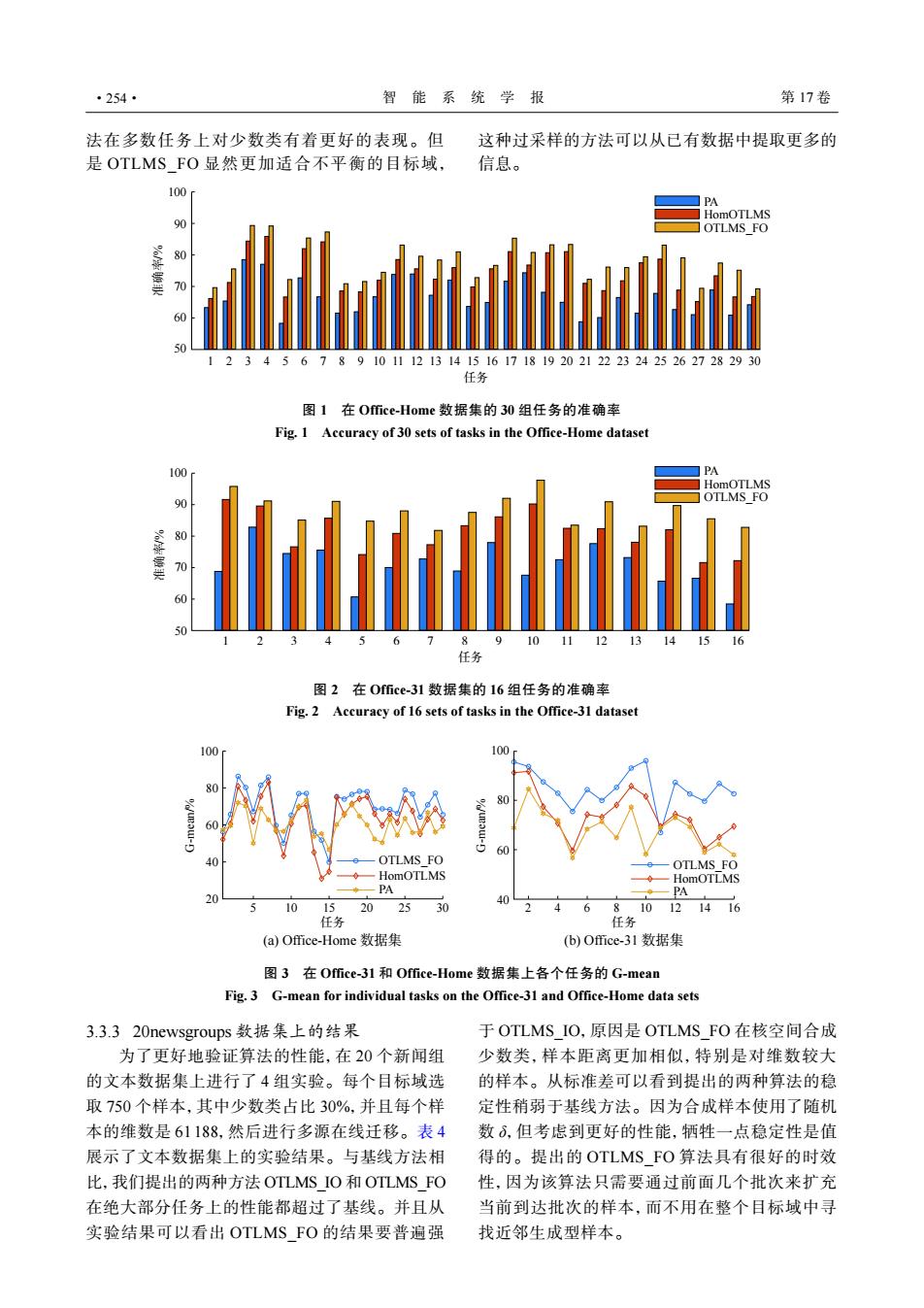
·254· 智能系统学报 第17卷 法在多数任务上对少数类有着更好的表现。但 这种过采样的方法可以从已有数据中提取更多的 是OTLMS FO显然更加适合不平衡的目标域, 信息。 100 PA ☐HomOTLMS % OTLMS FO 70 60 50 56789101112131415161718192021222324252627282930 任务 图1在Office-Home数据集的30组任务的准确率 Fig.1 Accuracy of 30 sets of tasks in the Office-Home dataset 100 PA HomOTLMS % OTLMS FO 00 60 7 8 9 10 11 12 任务 图2在Office-31数据集的16组任务的准确率 Fig.2 Accuracy of 16 sets of tasks in the Office-31 dataset 100 100 80 60 OTLMS FO OTLMS FO HomOTLMS -HomOTLMS -PA PA 20 10 15 20 25 30 6 81012 1416 任务 任务 (a)Office-Home数据集 (b)O压ice-31数据集 图3在Office-31和Office-Home数据集上各个任务的G-mean Fig.3 G-mean for individual tasks on the Office-31 and Office-Home data sets 3.3.320 newsgroups数据集上的结果 于OTLMS IO,原因是OTLMS FO在核空间合成 为了更好地验证算法的性能,在20个新闻组 少数类,样本距离更加相似,特别是对维数较大 的文本数据集上进行了4组实验。每个目标域选 的样本。从标准差可以看到提出的两种算法的稳 取750个样本,其中少数类占比30%,并且每个样 定性稍弱于基线方法。因为合成样本使用了随机 本的维数是61188,然后进行多源在线迁移。表4 数δ,但考虑到更好的性能,牺牲一点稳定性是值 展示了文本数据集上的实验结果。与基线方法相 得的。提出的OTLMS FO算法具有很好的时效 比,我们提出的两种方法OTLMS IO和OTLMS FO 性,因为该算法只需要通过前面几个批次来扩充 在绝大部分任务上的性能都超过了基线。并且从 当前到达批次的样本,而不用在整个目标域中寻 实验结果可以看出OTLMS FO的结果要普遍强 找近邻生成型样本。法在多数任务上对少数类有着更好的表现。但 是 OTLMS_FO 显然更加适合不平衡的目标域, 这种过采样的方法可以从已有数据中提取更多的 信息。 100 90 80 70 60 50 准确率/% PA HomOTLMS OTLMS_FO 任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 图 1 在 Office-Home 数据集的 30 组任务的准确率 Fig. 1 Accuracy of 30 sets of tasks in the Office-Home dataset 任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 100 90 80 70 60 50 PA HomOTLMS OTLMS_FO 准确率/% 图 2 在 Office-31 数据集的 16 组任务的准确率 Fig. 2 Accuracy of 16 sets of tasks in the Office-31 dataset 100 80 60 40 20 5 10 15 20 25 30 任务 2 4 6 8 10 12 14 16 任务 OTLMS_FO HomOTLMS PA OTLMS_FO HomOTLMS PA G-mean/% 100 80 60 40 G-mean/% (a) Office-Home 数据集 (b) Office-31 数据集 图 3 在 Office-31 和 Office-Home 数据集上各个任务的 G-mean Fig. 3 G-mean for individual tasks on the Office-31 and Office-Home data sets 3.3.3 20newsgroups 数据集上的结果 为了更好地验证算法的性能,在 20 个新闻组 的文本数据集上进行了 4 组实验。每个目标域选 取 750 个样本,其中少数类占比 30%,并且每个样 本的维数是 61 188,然后进行多源在线迁移。表 4 展示了文本数据集上的实验结果。与基线方法相 比,我们提出的两种方法 OTLMS_IO 和 OTLMS_FO 在绝大部分任务上的性能都超过了基线。并且从 实验结果可以看出 OTLMS_FO 的结果要普遍强 于 OTLMS_IO,原因是 OTLMS_FO 在核空间合成 少数类,样本距离更加相似,特别是对维数较大 的样本。从标准差可以看到提出的两种算法的稳 定性稍弱于基线方法。因为合成样本使用了随机 数 δ,但考虑到更好的性能,牺牲一点稳定性是值 得的。提出的 OTLMS_FO 算法具有很好的时效 性,因为该算法只需要通过前面几个批次来扩充 当前到达批次的样本,而不用在整个目标域中寻 找近邻生成型样本。 ·254· 智 能 系 统 学 报 第 17 卷