正在加载图片...
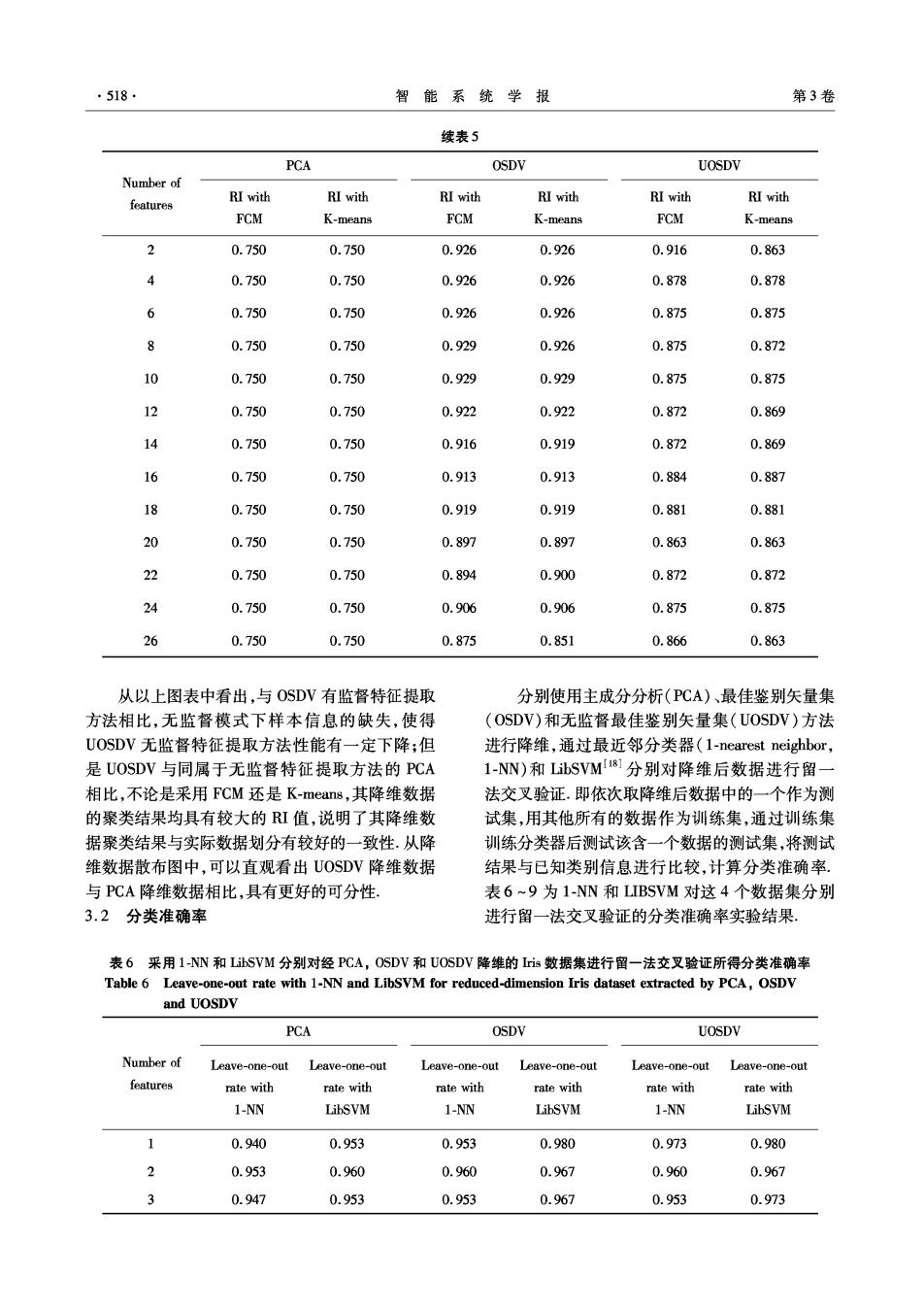
·518. 智能系统学报 第3卷 续表5 PCA OSDV UOSDV Number of RI with RI with RI with RI with RI with features RI with FCM K-means FCM K-means FCM K-means 2 0.750 0.750 0.926 0.926 0.916 0.863 4 0.750 0.750 0.926 0.926 0.878 0.878 6 0.750 0.750 0.926 0.926 0.875 0.875 8 0.750 0.750 0.929 0.926 0.875 0.872 10 0.750 0.750 0.929 0.929 0.875 0.875 12 0.750 0.750 0.922 0.922 0.872 0.869 14 0.750 0.750 0.916 0.919 0.872 0.869 16 0.750 0.750 0.913 0.913 0.884 0.887 18 0.750 0.750 0.919 0.919 0.881 0.881 20 0.750 0.750 0.897 0.897 0.863 0.863 22 0.750 0.750 0.894 0.900 0.872 0.872 24 0.750 0.750 0.906 0.906 0.875 0.875 26 0.750 0.750 0.875 0.851 0.866 0.863 从以上图表中看出,与OSDV有监督特征提取 分别使用主成分分析(PCA)、最佳鉴别矢量集 方法相比,无监督模式下样本信息的缺失,使得 (OSDV)和无监督最佳鉴别矢量集(UOSDV)方法 UOSDV无监督特征提取方法性能有一定下降;但 进行降维,通过最近邻分类器(1-nearest neighbor, 是UOSDV与同属于无监督特征提取方法的PCA 1-NN)和LibSVM81分别对降维后数据进行留 相比,不论是采用FCM还是K-means,其降维数据 法交叉验证.即依次取降维后数据中的一个作为测 的聚类结果均具有较大的I值,说明了其降维数 试集,用其他所有的数据作为训练集,通过训练集 据聚类结果与实际数据划分有较好的一致性.从降 训练分类器后测试该含一个数据的测试集,将测试 维数据散布图中,可以直观看出UOSDV降维数据 结果与已知类别信息进行比较,计算分类准确率. 与P℃A降维数据相比,具有更好的可分性。 表6~9为1-NN和LIBSVM对这4个数据集分别 3.2分类准确率 进行留一法交叉验证的分类淮确率实验结果, 表6采用1-NN和LibSVM分别对经PCA,OSDV和UOSDV降维的is数据集进行留一法交叉验证所得分类准确率 Table 6 Leave-one-out rate with 1-NN and LibSVM for reduced-dimension Iris dataset extracted by PCA,OSDV and UOSDV PCA OSDV UOSDV Number of Leave-one-out Leave-one-out Leave-one-out Leave-one-out Leave-one-out Leave-one-out features rate with rate with rate with rate with rate with rate with 1-NN LibSVM 1-NN LibSVM 1-NN LibSVM 1 0.940 0.953 0.953 0.980 0.973 0.980 2 0.953 0.960 0.960 0.967 0.960 0.967 3 0.947 0.953 0.953 0.967 0.953 0.973