正在加载图片...
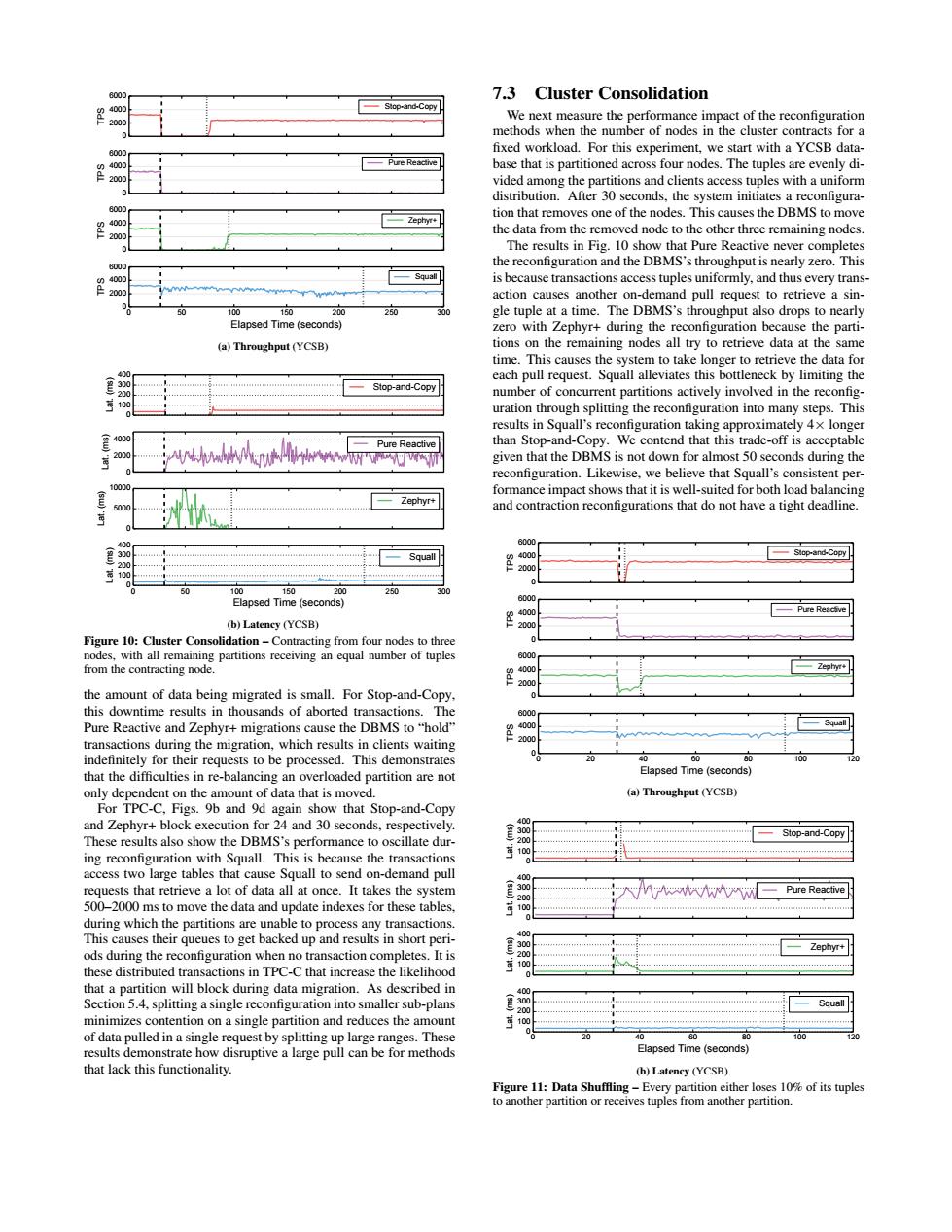
Sicp-ano.Coo 7.3 Cluster Consolidation the with a YCSB data base that is pa toned acro our node The tuples the DrMs the data from ther the thus eveyrsn 0 psedTreaon 20 MS'sthrougputoo (a)Throughput (YCSB) Stop-and-Copy uration thr ugh splitting the reconf ration into many Thi at the py is not do th Slep-and-Copy t of data hei Elapsed Tin (a)Throughput (YCSB Stop-and-Copy all at once.It takes the 2 the data and update indexes for these t es to get ked up and naller sub-pan es the an disruptive a large pull can be for method0 2000 4000 6000 TPS Stop-and-Copy 0 2000 4000 6000 TPS Pure Reactive 0 2000 4000 6000 TPS Zephyr+ 0 50 100 150 200 250 300 Elapsed Time (seconds) 0 2000 4000 6000 TPS Squall (a) Throughput (YCSB) 0 100 200 300 400 Lat. (ms) Stop-and-Copy 0 2000 4000 Lat. (ms) Pure Reactive 0 5000 10000 Lat. (ms) Zephyr+ 0 50 100 150 200 250 300 Elapsed Time (seconds) 0 100 200 300 400 Lat. (ms) Squall (b) Latency (YCSB) Figure 10: Cluster Consolidation – Contracting from four nodes to three nodes, with all remaining partitions receiving an equal number of tuples from the contracting node. the amount of data being migrated is small. For Stop-and-Copy, this downtime results in thousands of aborted transactions. The Pure Reactive and Zephyr+ migrations cause the DBMS to “hold” transactions during the migration, which results in clients waiting indefinitely for their requests to be processed. This demonstrates that the difficulties in re-balancing an overloaded partition are not only dependent on the amount of data that is moved. For TPC-C, Figs. 9b and 9d again show that Stop-and-Copy and Zephyr+ block execution for 24 and 30 seconds, respectively. These results also show the DBMS’s performance to oscillate during reconfiguration with Squall. This is because the transactions access two large tables that cause Squall to send on-demand pull requests that retrieve a lot of data all at once. It takes the system 500–2000 ms to move the data and update indexes for these tables, during which the partitions are unable to process any transactions. This causes their queues to get backed up and results in short periods during the reconfiguration when no transaction completes. It is these distributed transactions in TPC-C that increase the likelihood that a partition will block during data migration. As described in Section 5.4, splitting a single reconfiguration into smaller sub-plans minimizes contention on a single partition and reduces the amount of data pulled in a single request by splitting up large ranges. These results demonstrate how disruptive a large pull can be for methods that lack this functionality. 7.3 Cluster Consolidation We next measure the performance impact of the reconfiguration methods when the number of nodes in the cluster contracts for a fixed workload. For this experiment, we start with a YCSB database that is partitioned across four nodes. The tuples are evenly divided among the partitions and clients access tuples with a uniform distribution. After 30 seconds, the system initiates a reconfiguration that removes one of the nodes. This causes the DBMS to move the data from the removed node to the other three remaining nodes. The results in Fig. 10 show that Pure Reactive never completes the reconfiguration and the DBMS’s throughput is nearly zero. This is because transactions access tuples uniformly, and thus every transaction causes another on-demand pull request to retrieve a single tuple at a time. The DBMS’s throughput also drops to nearly zero with Zephyr+ during the reconfiguration because the partitions on the remaining nodes all try to retrieve data at the same time. This causes the system to take longer to retrieve the data for each pull request. Squall alleviates this bottleneck by limiting the number of concurrent partitions actively involved in the reconfiguration through splitting the reconfiguration into many steps. This results in Squall’s reconfiguration taking approximately 4× longer than Stop-and-Copy. We contend that this trade-off is acceptable given that the DBMS is not down for almost 50 seconds during the reconfiguration. Likewise, we believe that Squall’s consistent performance impact shows that it is well-suited for both load balancing and contraction reconfigurations that do not have a tight deadline. 0 2000 4000 6000 TPS Stop-and-Copy 0 2000 4000 6000 TPS Pure Reactive 0 2000 4000 6000 TPS Zephyr+ 0 20 40 60 80 100 120 Elapsed Time (seconds) 0 2000 4000 6000 TPS Squall (a) Throughput (YCSB) 0 100 200 300 400 Lat. (ms) Stop-and-Copy 0 100 200 300 400 Lat. (ms) Pure Reactive 0 100 200 300 400 Lat. (ms) Zephyr+ 0 20 40 60 80 100 120 Elapsed Time (seconds) 0 100 200 300 400 Lat. (ms) Squall (b) Latency (YCSB) Figure 11: Data Shuffling – Every partition either loses 10% of its tuples to another partition or receives tuples from another partition