正在加载图片...
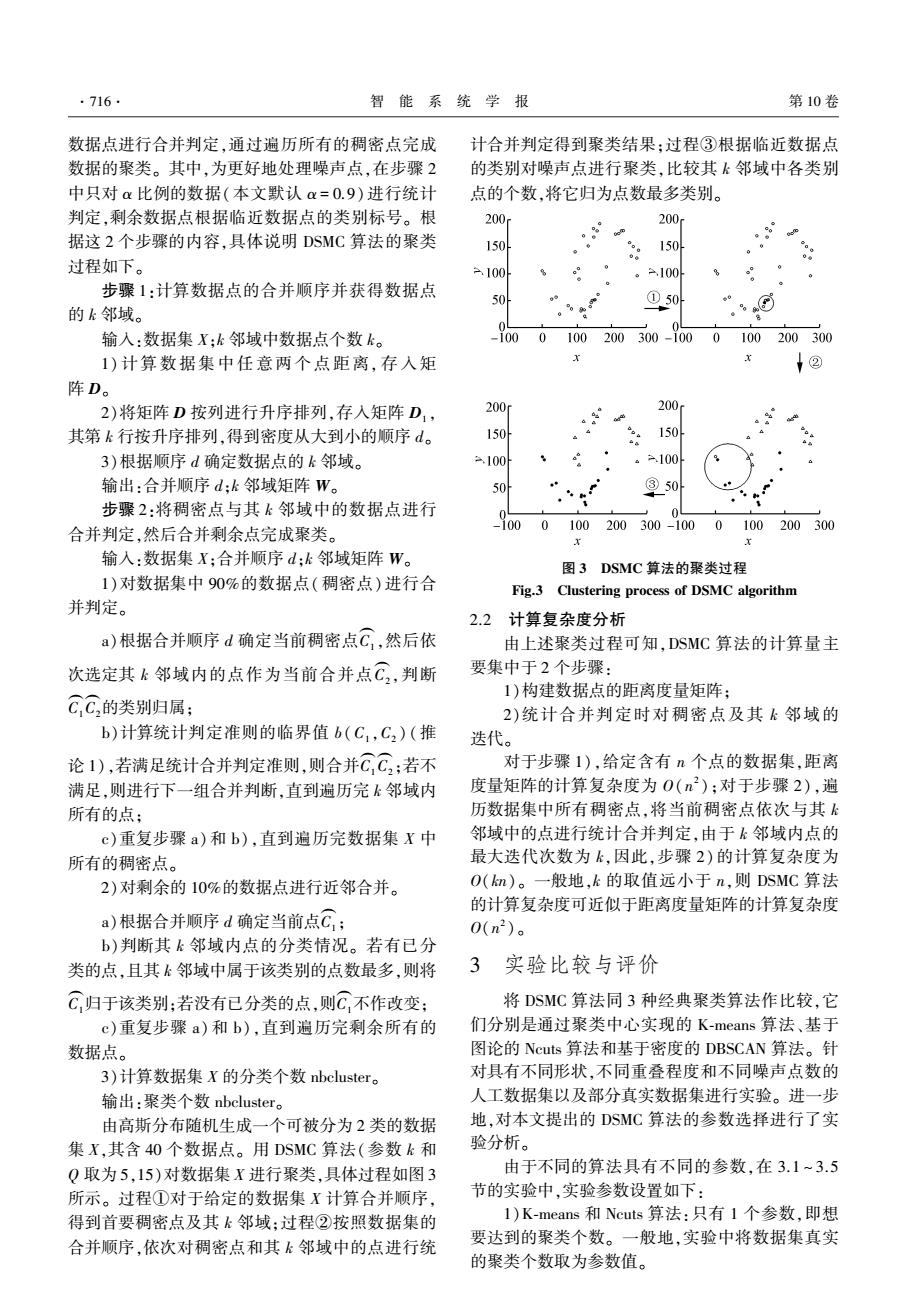
·716 智能系统学报 第10卷 数据点进行合并判定,通过遍历所有的稠密点完成 计合并判定得到聚类结果:过程③根据临近数据点 数据的聚类。其中,为更好地处理噪声点,在步骤2 的类别对噪声点进行聚类,比较其k邻域中各类别 中只对a比例的数据(本文默认α=0.9)进行统计 点的个数,将它归为点数最多类别。 判定,剩余数据点根据临近数据点的类别标号。根 200 200 据这2个步骤的内容,具体说明DSMC算法的聚类 150 150 过程如下。 100 。=.100 步骤1:计算数据点的合并顺序并获得数据点 50 的k邻域。 ①504 %⊙j 输入:数据集X;k邻域中数据点个数k。 1000100 200300-1000100200300 1)计算数据集中任意两个点距离,存入矩 1② 阵D。 2)将矩阵D按列进行升序排列,存入矩阵D, 200 200. 其第k行按升序排列,得到密度从大到小的顺序d。 150 150 3)根据顺序d确定数据点的k邻域。 a.100 。.100 输出:合并顺序d:k邻域矩阵W。 ③50 步骤2:将稠密点与其k邻域中的数据点进行 合并判定,然后合并剩余点完成聚类。 100 0100 200300-1000100200300 x 输入:数据集X;合并顺序d:k邻域矩阵W。 图3DSMC算法的聚类过程 1)对数据集中90%的数据点(稠密点)进行合 Fig.3 Clustering process of DSMC algorithm 并判定。 2.2计算复杂度分析 a)根据合并顺序d确定当前稠密点C,然后依 由上述聚类过程可知,DSMC算法的计算量主 次选定其k邻域内的点作为当前合并点C,判断 要集中于2个步骤: 1)构建数据点的距离度量矩阵: CC的类别归属: 2)统计合并判定时对稠密点及其k邻域的 b)计算统计判定准则的临界值b(C,C2)(推 迭代。 论1),若满足统计合并判定准则,则合并C,C,:若不 对于步骤1),给定含有n个点的数据集,距离 满足,则进行下一组合并判断,直到遍历完k邻域内 度量矩阵的计算复杂度为0(n2):对于步骤2),遍 所有的点: 历数据集中所有稠密点,将当前稠密点依次与其k c)重复步骤a)和b),直到遍历完数据集X中 邻域中的点进行统计合并判定,由于k邻域内点的 所有的稠密点。 最大迭代次数为k,因此,步骤2)的计算复杂度为 2)对剩余的10%的数据点进行近邻合并。 O(km)。一般地,k的取值远小于n,则DSMC算法 的计算复杂度可近似于距离度量矩阵的计算复杂度 a)根据合并顺序d确定当前点C; 0(n2)。 b)判断其k邻域内点的分类情况。若有已分 类的点,且其k邻域中属于该类别的点数最多,则将 3实验比较与评价 C归于该类别:若没有已分类的点,则C,不作改变: 将DSMC算法同3种经典聚类算法作比较,它 c)重复步骤a)和b),直到遍历完剩余所有的 们分别是通过聚类中心实现的K-means算法、基于 数据点。 图论的Ncuts算法和基于密度的DBSCAN算法。针 3)计算数据集X的分类个数nbcluster。 对具有不同形状,不同重叠程度和不同噪声点数的 输出:聚类个数nbcluster. 人工数据集以及部分真实数据集进行实验。进一步 由高斯分布随机生成一个可被分为2类的数据 地,对本文提出的DSMC算法的参数选择进行了实 集X,其含40个数据点。用DSMC算法(参数k和 验分析。 Q取为5,15)对数据集X进行聚类,具体过程如图3 由于不同的算法具有不同的参数,在3.1~3.5 所示。过程①对于给定的数据集X计算合并顺序, 节的实验中,实验参数设置如下: 得到首要稠密点及其k邻域:过程②按照数据集的 1)K-means和Ncuts算法:只有1个参数,即想 合并顺序,依次对稠密点和其k邻域中的点进行统 要达到的聚类个数。一般地,实验中将数据集真实 的聚类个数取为参数值。数据点进行合并判定,通过遍历所有的稠密点完成 数据的聚类。 其中,为更好地处理噪声点,在步骤 2 中只对 α 比例的数据(本文默认 α = 0.9)进行统计 判定,剩余数据点根据临近数据点的类别标号。 根 据这 2 个步骤的内容,具体说明 DSMC 算法的聚类 过程如下。 步骤 1:计算数据点的合并顺序并获得数据点 的 k 邻域。 输入:数据集 X;k 邻域中数据点个数 k。 1) 计 算 数 据 集 中 任 意 两 个 点 距 离, 存 入 矩 阵 D。 2)将矩阵 D 按列进行升序排列,存入矩阵 D1 , 其第 k 行按升序排列,得到密度从大到小的顺序 d。 3)根据顺序 d 确定数据点的 k 邻域。 输出:合并顺序 d;k 邻域矩阵 W。 步骤 2:将稠密点与其 k 邻域中的数据点进行 合并判定,然后合并剩余点完成聚类。 输入:数据集 X;合并顺序 d;k 邻域矩阵 W。 1)对数据集中 90%的数据点(稠密点)进行合 并判定。 a)根据合并顺序 d 确定当前稠密点C1 ( ,然后依 次选定其 k 邻域内的点作为当前合并点C2 ( ,判断 C1 ( C2 ( 的类别归属; b)计算统计判定准则的临界值 b(C1 ,C2 ) (推 论 1),若满足统计合并判定准则,则合并C1 ( C2 ( ;若不 满足,则进行下一组合并判断,直到遍历完 k 邻域内 所有的点; c)重复步骤 a)和 b),直到遍历完数据集 X 中 所有的稠密点。 2)对剩余的 10%的数据点进行近邻合并。 a)根据合并顺序 d 确定当前点C1 ( ; b)判断其 k 邻域内点的分类情况。 若有已分 类的点,且其 k 邻域中属于该类别的点数最多,则将 C1 ( 归于该类别;若没有已分类的点,则C1 ( 不作改变; c)重复步骤 a)和 b),直到遍历完剩余所有的 数据点。 3)计算数据集 X 的分类个数 nbcluster。 输出:聚类个数 nbcluster。 由高斯分布随机生成一个可被分为 2 类的数据 集 X,其含 40 个数据点。 用 DSMC 算法(参数 k 和 Q 取为 5,15)对数据集 X 进行聚类,具体过程如图 3 所示。 过程①对于给定的数据集 X 计算合并顺序, 得到首要稠密点及其 k 邻域;过程②按照数据集的 合并顺序,依次对稠密点和其 k 邻域中的点进行统 计合并判定得到聚类结果;过程③根据临近数据点 的类别对噪声点进行聚类,比较其 k 邻域中各类别 点的个数,将它归为点数最多类别。 图 3 DSMC 算法的聚类过程 Fig.3 Clustering process of DSMC algorithm 2.2 计算复杂度分析 由上述聚类过程可知,DSMC 算法的计算量主 要集中于 2 个步骤: 1)构建数据点的距离度量矩阵; 2)统计合并判定时对稠密点及其 k 邻域的 迭代。 对于步骤 1),给定含有 n 个点的数据集,距离 度量矩阵的计算复杂度为 O(n 2 );对于步骤 2),遍 历数据集中所有稠密点,将当前稠密点依次与其 k 邻域中的点进行统计合并判定,由于 k 邻域内点的 最大迭代次数为 k,因此,步骤 2) 的计算复杂度为 O(kn)。 一般地,k 的取值远小于 n,则 DSMC 算法 的计算复杂度可近似于距离度量矩阵的计算复杂度 O(n 2 )。 3 实验比较与评价 将 DSMC 算法同 3 种经典聚类算法作比较,它 们分别是通过聚类中心实现的 K⁃means 算法、基于 图论的 Ncuts 算法和基于密度的 DBSCAN 算法。 针 对具有不同形状,不同重叠程度和不同噪声点数的 人工数据集以及部分真实数据集进行实验。 进一步 地,对本文提出的 DSMC 算法的参数选择进行了实 验分析。 由于不同的算法具有不同的参数,在 3.1 ~ 3.5 节的实验中,实验参数设置如下: 1)K⁃means 和 Ncuts 算法:只有 1 个参数,即想 要达到的聚类个数。 一般地,实验中将数据集真实 的聚类个数取为参数值。 ·716· 智 能 系 统 学 报 第 10 卷