正在加载图片...
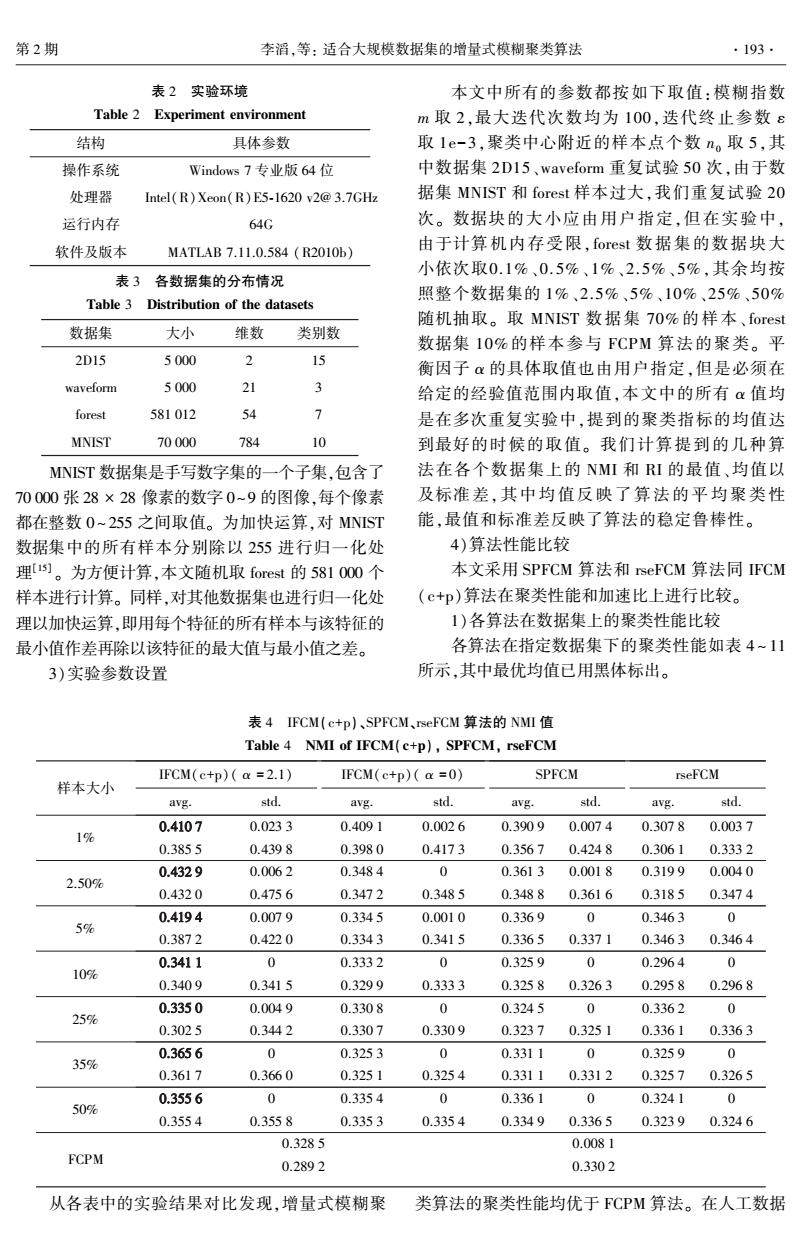
第2期 李滔,等:适合大规模数据集的增量式模糊聚类算法 ·193 表2实验环境 本文中所有的参数都按如下取值:模糊指数 Table 2 Experiment environment m取2,最大迭代次数均为100,迭代终止参数ε 结构 具体参数 取1e-3,聚类中心附近的样本点个数no取5,其 操作系统 Windows7专业版64位 中数据集2D15、waveform重复试验50次,由于数 处理器 Intel(R)Xeon(R)E5-1620 v2@3.7GHz 据集MNIST和forest样本过大,我们重复试验20 运行内存 64G 次。数据块的大小应由用户指定,但在实验中, 软件及版本 MATLAB7.11.0.584(R2010h) 由于计算机内存受限,forest数据集的数据块大 小依次取0.1%、0.5%、1%、2.5%、5%,其余均按 表3各数据集的分布情况 照整个数据集的1%、2.5%、5%、10%、25%、50% Table 3 Distribution of the datasets 随机抽取。取MNIST数据集70%的样本、forest 数据集 大小 维数 类别数 数据集10%的样本参与FCPM算法的聚类。平 2D15 5000 2 15 衡因子α的具体取值也由用户指定,但是必须在 waveform 5000 21 3 给定的经验值范围内取值,本文中的所有α值均 forest 581012 54 7 是在多次重复实验中,提到的聚类指标的均值达 MNIST 70000 784 10 到最好的时候的取值。我们计算提到的几种算 MNIST数据集是手写数字集的一个子集,包含了 法在各个数据集上的NMI和RI的最值、均值以 70000张28×28像素的数字0~9的图像,每个像素 及标准差,其中均值反映了算法的平均聚类性 都在整数0~255之间取值。为加快运算,对MNIST 能,最值和标准差反映了算法的稳定鲁棒性。 数据集中的所有样本分别除以255进行归一化处 4)算法性能比较 理1s。为方便计算,本文随机取forest的581000个 本文采用SPFCM算法和rseFCM算法同IFCM 样本进行计算。同样,对其他数据集也进行归一化处 (c+p)算法在聚类性能和加速比上进行比较。 理以加快运算,即用每个特征的所有样本与该特征的 1)各算法在数据集上的聚类性能比较 最小值作差再除以该特征的最大值与最小值之差。 各算法在指定数据集下的聚类性能如表4~11 3)实验参数设置 所示,其中最优均值已用黑体标出。 表4FCM(c+p)、SPFCM、rseFCM算法的NMI值 Table 4 NMI of IFCM(c+p),SPFCM,rseFCM FCM(c+p)(a=2.1) IFCM(c+p)(a=0) SPFCM rseFCM 样本大小 avg. std. avg. std. avg. std. avg. std. 0.4107 0.0233 0.4091 0.0026 0.3909 0.0074 0.3078 0.0037 1% 0.3855 0.4398 0.3980 0.4173 0.3567 0.4248 0.3061 0.3332 0.4329 0.0062 0.3484 0 0.3613 0.0018 0.3199 0.0040 2.50% 0.4320 0.4756 0.3472 0.3485 0.3488 0.3616 0.3185 0.3474 0.4194 0.0079 0.3345 0.0010 0.3369 0 0.3463 0 5% 0.3872 0.4220 0.3343 0.3415 0.3365 0.3371 0.3463 0.3464 0.3411 a 0.3332 0 0.3259 0 0.2964 0 10% 0.3409 0.3415 0.3299 0.3333 0.3258 0.3263 0.2958 0.2968 0.3350 0.0049 0.3308 0 0.3245 0 0.3362 0 25% 0.3025 0.3442 0.3307 0.3309 0.3237 0.3251 0.3361 0.3363 0.3656 0 0.3253 0 0.3311 0 0.3259 0 35% 0.3617 0.3660 0.3251 0.3254 0.3311 0.3312 0.3257 0.3265 0.3556 0 0.3354 0 0.3361 0 0.3241 50% 0 0.3554 0.3558 0.3353 0.3354 0.3349 0.3365 0.3239 0.3246 0.3285 0.0081 FCPM 0.2892 0.3302 从各表中的实验结果对比发现,增量式模糊聚 类算法的聚类性能均优于FCPM算法。在人工数据表 2 实验环境 Table 2 Experiment environment 结构 具体参数 操作系统 Windows 7 专业版 64 位 处理器 Intel(R)Xeon(R)E5⁃1620 v2@ 3.7GHz 运行内存 64G 软件及版本 MATLAB 7.11.0.584 (R2010b) 表 3 各数据集的分布情况 Table 3 Distribution of the datasets 数据集 大小 维数 类别数 2D15 5 000 2 15 waveform 5 000 21 3 forest 581 012 54 7 MNIST 70 000 784 10 MNIST 数据集是手写数字集的一个子集,包含了 70 000 张 28 × 28 像素的数字 0~9 的图像,每个像素 都在整数 0 ~ 255 之间取值。 为加快运算,对 MNIST 数据集中的所有样本分别除以 255 进行归一化处 理[15] 。 为方便计算,本文随机取 forest 的 581 000 个 样本进行计算。 同样,对其他数据集也进行归一化处 理以加快运算,即用每个特征的所有样本与该特征的 最小值作差再除以该特征的最大值与最小值之差。 3)实验参数设置 本文中所有的参数都按如下取值:模糊指数 m 取 2,最大迭代次数均为 100,迭代终止参数 ε 取 1e-3,聚类中心附近的样本点个数 n0 取 5,其 中数据集 2D15、waveform 重复试验 50 次,由于数 据集 MNIST 和 forest 样本过大,我们重复试验 20 次。 数据块的大小应由用户指定,但在实验中, 由于计算机内存受限, forest 数据集的数据块大 小依次取0.1%、0. 5%、1%、2. 5%、5%,其余均按 照整个数据集的 1%、2.5%、5%、10%、25%、50% 随机抽取。 取 MNIST 数据集 70% 的样本、 forest 数据集 10% 的样本参与 FCPM 算法的聚类。 平 衡因子 α 的具体取值也由用户指定,但是必须在 给定的经验值范围内取值,本文中的所有 α 值均 是在多次重复实验中,提到的聚类指标的均值达 到最好的时候的取值。 我们计算提到的几种算 法在各个数据集上的 NMI 和 RI 的最值、均值以 及标准差,其中均值反映了算法的 平 均 聚 类 性 能,最值和标准差反映了算法的稳定鲁棒性。 4)算法性能比较 本文采用 SPFCM 算法和 rseFCM 算法同 IFCM (c+p)算法在聚类性能和加速比上进行比较。 1)各算法在数据集上的聚类性能比较 各算法在指定数据集下的聚类性能如表 4 ~ 11 所示,其中最优均值已用黑体标出。 表 4 IFCM(c+p)、SPFCM、rseFCM 算法的 NMI 值 Table 4 NMI of IFCM(c+p), SPFCM, rseFCM 样本大小 IFCM(c+p)( α = 2.1) avg. std. IFCM(c+p)( α = 0) avg. std. SPFCM avg. std. rseFCM avg. std. 1% 0.410 7 0.023 3 0.409 1 0.002 6 0.390 9 0.007 4 0.307 8 0.003 7 0.385 5 0.439 8 0.398 0 0.417 3 0.356 7 0.424 8 0.306 1 0.333 2 2.50% 0.432 9 0.006 2 0.348 4 0 0.361 3 0.001 8 0.319 9 0.004 0 0.432 0 0.475 6 0.347 2 0.348 5 0.348 8 0.361 6 0.318 5 0.347 4 5% 0.419 4 0.007 9 0.334 5 0.001 0 0.336 9 0 0.346 3 0 0.387 2 0.422 0 0.334 3 0.341 5 0.336 5 0.337 1 0.346 3 0.346 4 10% 0.341 1 0 0.333 2 0 0.325 9 0 0.296 4 0 0.340 9 0.341 5 0.329 9 0.333 3 0.325 8 0.326 3 0.295 8 0.296 8 25% 0.335 0 0.004 9 0.330 8 0 0.324 5 0 0.336 2 0 0.302 5 0.344 2 0.330 7 0.330 9 0.323 7 0.325 1 0.336 1 0.336 3 35% 0.365 6 0 0.325 3 0 0.331 1 0 0.325 9 0 0.361 7 0.366 0 0.325 1 0.325 4 0.331 1 0.331 2 0.325 7 0.326 5 50% 0.355 6 0 0.335 4 0 0.336 1 0 0.324 1 0 0.355 4 0.355 8 0.335 3 0.335 4 0.334 9 0.336 5 0.323 9 0.324 6 FCPM 0.328 5 0.008 1 0.289 2 0.330 2 从各表中的实验结果对比发现,增量式模糊聚 类算法的聚类性能均优于 FCPM 算法。 在人工数据 第 2 期 李滔,等: 适合大规模数据集的增量式模糊聚类算法 ·193·