正在加载图片...
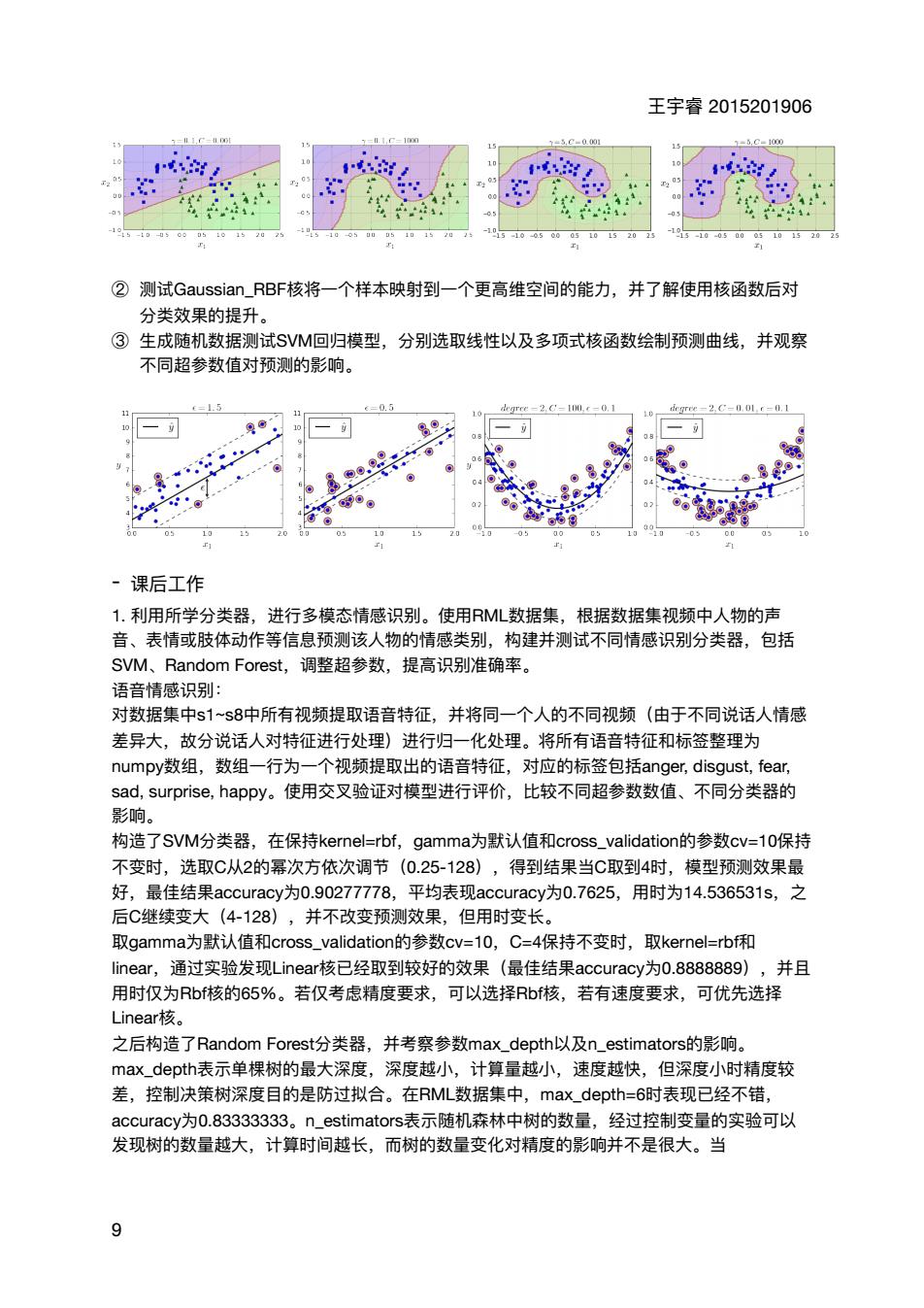
王字春2015201906 的, ②测测试Gaussian rBe核将一个样本映射到一个更高维空间的能力.并了解使用核函数后对 分类效果的提升 ③生成随机数据测试SV回归模型,分别选取线性以及多项式核函数绘制预测曲线,并观察 不同超参数值对预测的影响。 2C-1t0 1019 ·课后工作 1利用所学分类翠 进行多模态情感识别。使用ML数据集,根据数据集视频中人物的声 音、 表情或肢体动作等信息预测该 人 情感类别, 构建并测试不同情感识别分类器,包括 SVM、Random Forest,调整超参数,提高识别准确率。 语音情感识别: 对数据集中s1~s8中所有视频提取语音特征,并将同一个人的不同视频(由于不同说话人情感 差异大,故分说话人对特征进行处理)进行归一化处理。将所有语音特征和标签整理为 numpy数组,数组一行为一个视频提取出的语音特征,对应的标签包括anger,,disgust,.fear sad,surprise,.happy。.使用交叉验证对模型进行评价,比较不同超参数数值、不同分类器的 影响 构造了SVM分类器,在保持kernel-=rbf,gamma为默认值和cross_.validation的参数cv=10保持 不变时,选取C从2的幂次方依次调节(0.25-128),得到结果当C取到4时,模型预测效果最 好,最佳结果accuracy:为0.90277778,平均表现accuracy?为0.7625,用时为14.536531s,之 后C继续变大 (4-128) ,并不改变 效里 但用时变长 取gamma为默认值和cross_.validation的参数cv=10,C=4保持不变时,取kernel--rbf和 linear,通过实验发现Lineart核已经取到较好的效果(最佳结果accuracy为0.8888889),并且 用时仅为b核的65%。若仅考虑精度要求,可以选择Rbf核,若有速度要求,可优先选择 Linear核。 之后构造了Random Forest:分类器,并考察参数max_depth以及n_estimators的影响。 max depth表示单棵树的最大深度.深度越小.计草量越小.速度越快.但深度小时精度较 差,控制决策树深度目的是防过拟合。 在RML数据集中,max_depth=6时表现已经不错 accuracy为0.83333333。n_estimators表示随机森林中树的数量,经过控制变量的实验可以 发现树的数量越大,计算时间越长,而树的数量变化对精度的影响并不是很大。当 9 王宇睿 2015201906 ② 测试Gaussian_RBF核将⼀个样本映射到⼀个更⾼维空间的能⼒,并了解使⽤核函数后对 分类效果的提升。 ③ ⽣成随机数据测试SVM回归模型,分别选取线性以及多项式核函数绘制预测曲线,并观察 不同超参数值对预测的影响。 - 课后⼯作 1. 利⽤所学分类器,进⾏多模态情感识别。使⽤RML数据集,根据数据集视频中⼈物的声 ⾳、表情或肢体动作等信息预测该⼈物的情感类别,构建并测试不同情感识别分类器,包括 SVM、Random Forest,调整超参数,提⾼识别准确率。 语⾳情感识别: 对数据集中s1~s8中所有视频提取语⾳特征,并将同⼀个⼈的不同视频(由于不同说话⼈情感 差异⼤,故分说话⼈对特征进⾏处理)进⾏归⼀化处理。将所有语⾳特征和标签整理为 numpy数组,数组⼀⾏为⼀个视频提取出的语⾳特征,对应的标签包括anger, disgust, fear, sad, surprise, happy。使⽤交叉验证对模型进⾏评价,⽐较不同超参数数值、不同分类器的 影响。 构造了SVM分类器,在保持kernel=rbf,gamma为默认值和cross_validation的参数cv=10保持 不变时,选取C从2的幂次⽅依次调节(0.25-128),得到结果当C取到4时,模型预测效果最 好,最佳结果accuracy为0.90277778,平均表现accuracy为0.7625,⽤时为14.536531s,之 后C继续变⼤(4-128),并不改变预测效果,但⽤时变⻓。 取gamma为默认值和cross_validation的参数cv=10,C=4保持不变时,取kernel=rbf和 linear,通过实验发现Linear核已经取到较好的效果(最佳结果accuracy为0.8888889),并且 ⽤时仅为Rbf核的65%。若仅考虑精度要求,可以选择Rbf核,若有速度要求,可优先选择 Linear核。 之后构造了Random Forest分类器,并考察参数max_depth以及n_estimators的影响。 max_depth表示单棵树的最⼤深度,深度越⼩,计算量越⼩,速度越快,但深度⼩时精度较 差,控制决策树深度⽬的是防过拟合。在RML数据集中,max_depth=6时表现已经不错, accuracy为0.83333333。n_estimators表示随机森林中树的数量,经过控制变量的实验可以 发现树的数量越⼤,计算时间越⻓,⽽树的数量变化对精度的影响并不是很⼤。当 9