正在加载图片...
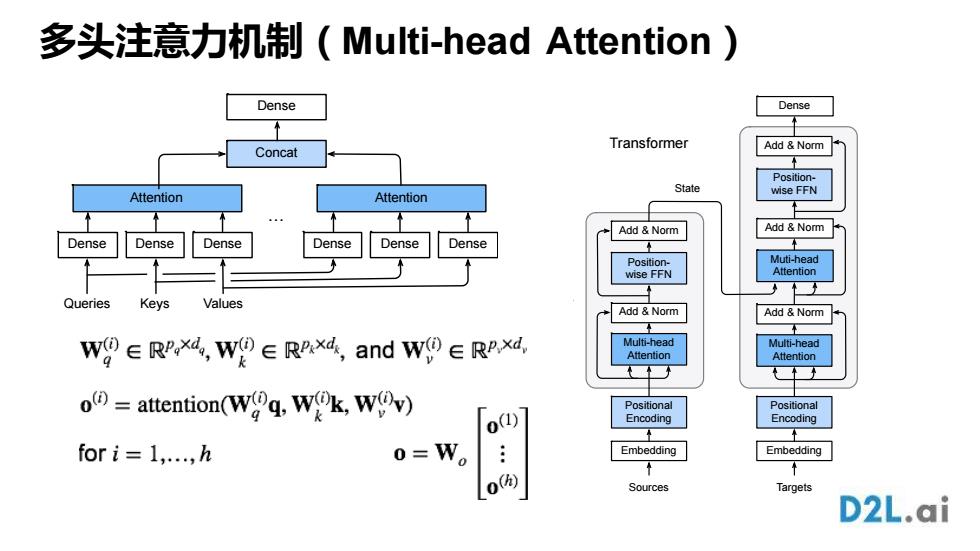
多头注意力机制(Multi--head Attention) Dense Dense Transformer Concat Add Norm Position- State wise FFN Attention Attention Add Norm Add Norm Dense Dense De Dense Dense Dense Position- Muti-head wise FFN Attention Queries Keys Values Add Norm Add Norm W9∈RP,x4,W9∈RPx4,andW0∈RP,xa, Multi-head Multi-head Attention Attention ()=attention(Wq Wk,Wv) Positional Positional Encoding Encoding for i=1,...,h 0=W。 Embedding Embedding Sources Targets D2L.ai多头注意力机制(Multi-head Attention) Dense Attention Queries Keys Values Dense Dense … Dense Attention Dense Dense Concat Dense Multi-head Attention Add & Norm Positional Encoding Embedding Positionwise FFN Add & Norm Muti-head Attention Add & Norm Positionwise FFN Add & Norm Sources Dense Multi-head Attention Add & Norm Positional Encoding Embedding Targets x n n x State Embedding Sources Decoder n x Embedding Targets Dense Encoder Attention Recurrent layer Recurrent layer x n Seq2seq with Attention Transformer