正在加载图片...
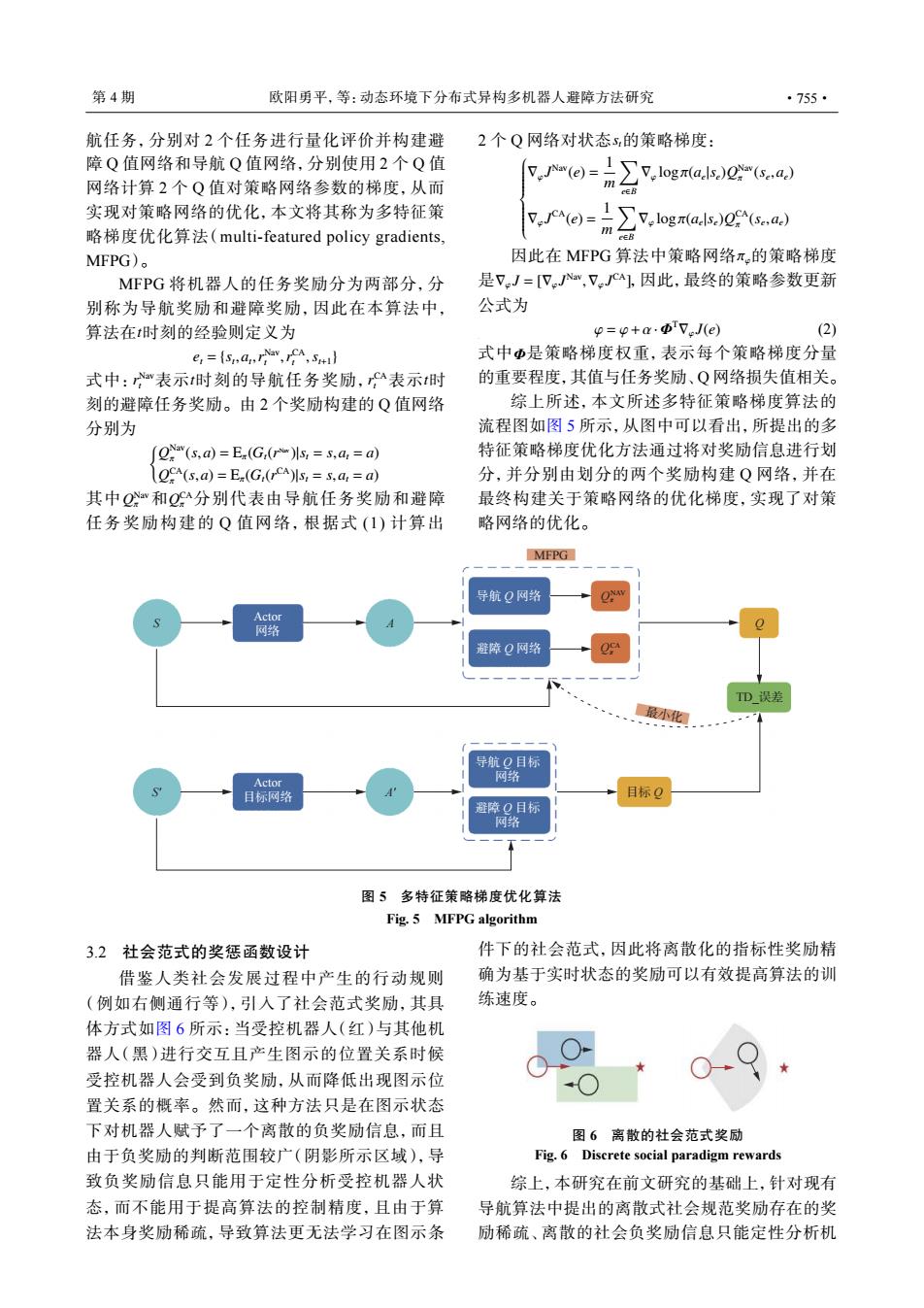
第4期 欧阳勇平,等:动态环境下分布式异构多机器人避障方法研究 ·755· 航任务,分别对2个任务进行量化评价并构建避 2个Q网络对状态s的策略梯度: 障Q值网络和导航Q值网络,分别使用2个Q值 (e)= 网络计算2个Q值对策略网络参数的梯度,从而 1又,.logr(a.ls.)0(sa.) cEB 实现对策略网络的优化,本文将其称为多特征策 (e)= 略梯度优化算法(multi-.featured policy gradients, ∑7,og((a MFPG)。 因此在MFPG算法中策略网络π,的策略梯度 MFPG将机器人的任务奖励分为两部分,分 是7J=[VJav,VJCa],因此,最终的策略参数更新 别称为导航奖励和避障奖励,因此在本算法中, 公式为 算法在t时刻的经验则定义为 p=p+a.Φ7eJ(e) (2) e:=(smarra,ICA,s 式中Φ是策略梯度权重,表示每个策略梯度分量 式中:表示t时刻的导航任务奖励,表示t时 的重要程度,其值与任务奖励、Q网络损失值相关。 刻的避障任务奖励。由2个奖励构建的Q值网络 综上所述,本文所述多特征策略梯度算法的 分别为 流程图如图5所示,从图中可以看出,所提出的多 (ON(s,a)=Ex(G(r)Is,=s,a,=a) 特征策略梯度优化方法通过将对奖励信息进行划 OCA(s,a)=E(G(rCA)Is,=s.a,=a) 分,并分别由划分的两个奖励构建Q网络,并在 其中Q公和Q分别代表由导航任务奖励和避障 最终构建关于策略网络的优化梯度,实现了对策 任务奖励构建的Q值网络,根据式(1)计算出 略网络的优化。 MFPG 导航Q网路 Actor 网络 避障Q网络 TD_误差 最小化 导航Q目标 Actor 网络 目标网络 目标Q 避障O目标 网络 图5多特征策略梯度优化算法 Fig.5 MFPG algorithm 3.2社会范式的奖惩函数设计 件下的社会范式,因此将离散化的指标性奖励精 借鉴人类社会发展过程中产生的行动规则 确为基于实时状态的奖励可以有效提高算法的训 (例如右侧通行等),引入了社会范式奖励,其具 练速度。 体方式如图6所示:当受控机器人(红)与其他机 器人(黑)进行交互且产生图示的位置关系时候 受控机器人会受到负奖励,从而降低出现图示位 置关系的概率。然而,这种方法只是在图示状态 下对机器人赋予了一个离散的负奖励信息,而且 图6离散的社会范式奖励 由于负奖励的判断范围较广(阴影所示区域),导 Fig.6 Discrete social paradigm rewards 致负奖励信息只能用于定性分析受控机器人状 综上,本研究在前文研究的基础上,针对现有 态,而不能用于提高算法的控制精度,且由于算 导航算法中提出的离散式社会规范奖励存在的奖 法本身奖励稀疏,导致算法更无法学习在图示条 励稀疏、离散的社会负奖励信息只能定性分析机航任务,分别对 2 个任务进行量化评价并构建避 障 Q 值网络和导航 Q 值网络,分别使用 2 个 Q 值 网络计算 2 个 Q 值对策略网络参数的梯度,从而 实现对策略网络的优化,本文将其称为多特征策 略梯度优化算法(multi-featured policy gradients, MFPG)。 t MFPG 将机器人的任务奖励分为两部分,分 别称为导航奖励和避障奖励,因此在本算法中, 算法在 时刻的经验则定义为 et = {st ,at ,r Nav t ,r CA t ,st+1} r Nav t t r CA t 式中: 表示 时刻的导航任务奖励, 表示 t 时 刻的避障任务奖励。由 2 个奖励构建的 Q 值网络 分别为 { Q Nav π (s,a) = Eπ(Gt(r Nav )|st = s,at = a) Q CA π (s,a) = Eπ(Gt(r CA)|st = s,at = a) Q Nav π Q CA 其中 和 π 分别代表由导航任务奖励和避障 任务奖励构建的 Q 值网络,根据式 (1) 计算出 2 个 Q 网络对状态 st的策略梯度: ∇φ J Nav(e) = 1 m ∑ e∈B ∇φ logπ(ae |se)Q Nav π (se ,ae) ∇φ J CA(e) = 1 m ∑ e∈B ∇φ logπ(ae |se)Q CA π (se ,ae) πφ ∇φ J = [∇φ J Nav ,∇φ J CA] 因此在 MFPG 算法中策略网络 的策略梯度 是 ,因此,最终的策略参数更新 公式为 φ = φ+α·Φ T∇φ J(e) (2) 式中 Φ 是策略梯度权重,表示每个策略梯度分量 的重要程度,其值与任务奖励、Q 网络损失值相关。 综上所述,本文所述多特征策略梯度算法的 流程图如图 5 所示,从图中可以看出,所提出的多 特征策略梯度优化方法通过将对奖励信息进行划 分,并分别由划分的两个奖励构建 Q 网络,并在 最终构建关于策略网络的优化梯度,实现了对策 略网络的优化。 导航 Q 目标 网络 避障 Q 目标 网络 导航 Q 网络 避障 Q 网络 Actor 目标网络 Actor 网络 A Q Qπ NAV Qπ CA A' S S' MFPG 目标 Q 最小化 TD_误差 图 5 多特征策略梯度优化算法 Fig. 5 MFPG algorithm 3.2 社会范式的奖惩函数设计 借鉴人类社会发展过程中产生的行动规则 (例如右侧通行等),引入了社会范式奖励,其具 体方式如图 6 所示:当受控机器人(红)与其他机 器人(黑)进行交互且产生图示的位置关系时候 受控机器人会受到负奖励,从而降低出现图示位 置关系的概率。然而,这种方法只是在图示状态 下对机器人赋予了一个离散的负奖励信息,而且 由于负奖励的判断范围较广(阴影所示区域),导 致负奖励信息只能用于定性分析受控机器人状 态,而不能用于提高算法的控制精度,且由于算 法本身奖励稀疏,导致算法更无法学习在图示条 件下的社会范式,因此将离散化的指标性奖励精 确为基于实时状态的奖励可以有效提高算法的训 练速度。 图 6 离散的社会范式奖励 Fig. 6 Discrete social paradigm rewards 综上,本研究在前文研究的基础上,针对现有 导航算法中提出的离散式社会规范奖励存在的奖 励稀疏、离散的社会负奖励信息只能定性分析机 第 4 期 欧阳勇平,等:动态环境下分布式异构多机器人避障方法研究 ·755·