正在加载图片...
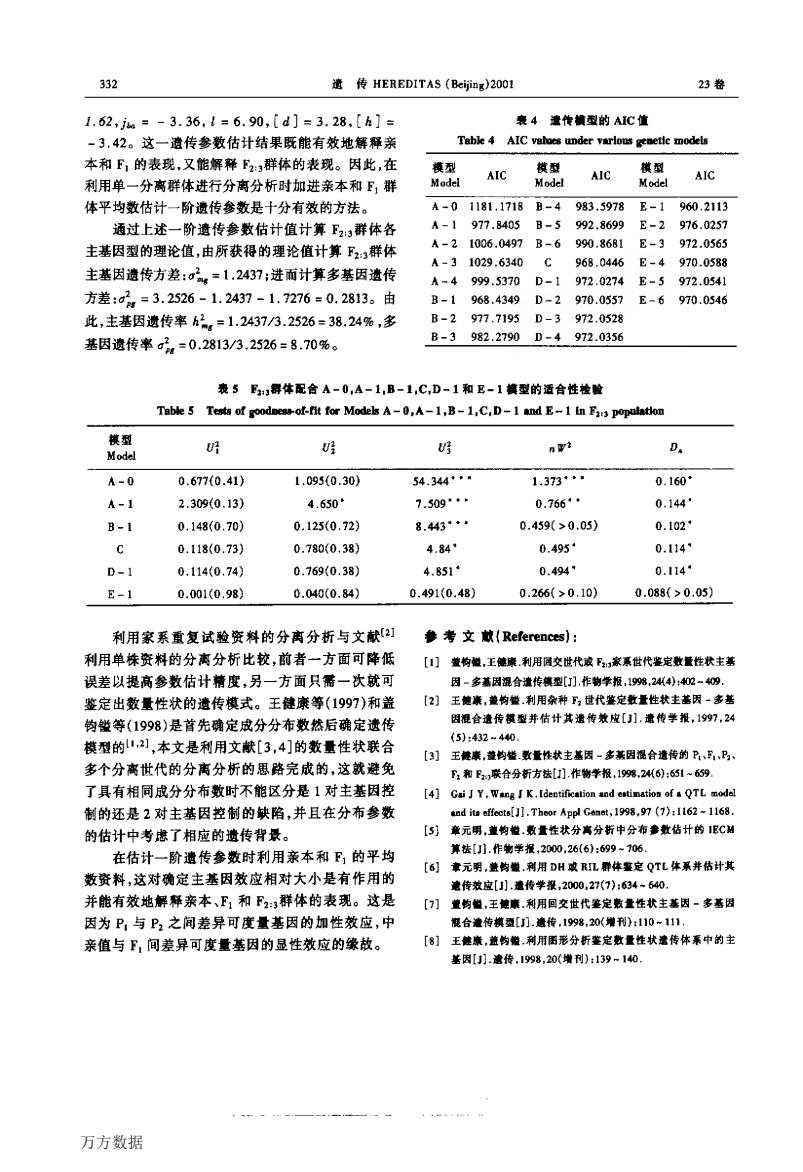
332 传HEREDITAS(Big200 23卷 1.62.=-3.36.1=6.90.「d1=3.28.【k1 囊4遭传横型的AC值 -3.42。这一遗传参数估计结果既能有教地解释亲 Tabl 4 AIC vuloes under varlous genetle models 本和F,的表现又能解解,腊体的表现。因比,在 模型 到用单 分南群体行分离分析时加进亲本和,群 AIC AIC AIC 体平均数估切 一阶遗传参数是十分有效的方法 181.1718B- 0 通过上述一阶遗传参数估计值计算F,群体各 ,4 43 主基因型的理论值,由所获得的理论值计算,群体 A-31029.6340 Q6R044 E-497005R8 主基因遗传方差:,=1,2437:进而计算多基因渣传 A-4999.5370D-1 972.0274E-5972.0341 方差:=3.2526 -1.2437-1.7276=0.2813。由 B-1968.4349D-2970.055 E-6970.0546 此.主基因遗传室62=1.24373.2526=38.24%多 B-2977.7195D-3 972.052 基因遗传率,=0.2813/3.2526=8.70%。 B-3 982.2790D-4972.0356 表5舞体配合A一0,A-1,B-1,C,D-1和E-1摘型的适合性检酸 Tabw5 Tests af。 of-ft for Modeks A-0,A-1.B-1.C.D-1 and E-1 in Fa popalation 0… A-0 0.677(0.41) 1.095(0.30) 54.344* 1.373** 0.160* A1 2.3090.13) 4.650 7.509 0.766· 0.144 B-1 0.1480.70) 0.125(0.72 0.459(>0.05) 0.l02 0.118(0.73) 0.780(0.38 4.841 0.495 0.114 n-1 0114f0.74 0.7690.38】 4R51· 0.494 0.1149 E-1 0.0m1(0.98) 0.040(0.a4 0.491(0.48) 0.266(>0.10) 0.088(>0.05) 利用家系重复试验资斜的分离分析与文献 参考文(References): 利用单候密料的分惠分析比较前者一方面可降: 】莹构,王储利用周交世代衣,家系代完数量性状主基 误差以提高参数估计精度,另一方面只需一次就可 因-多因合逢传型们.作物学报,%,241-4。 鉴定出数量性状的造 专模式。王键康等(1997)和盖 21 王偏廉,藏钩整利用杂种设代鉴定数重性状主兹因一多善 钩等(1998)是首先确定成分分布数然后确定速 因混合遗传模型并估什其遭传效皮[山小.意传学报,1997,24 模型的2),本文是利用文献[3,4]的数量性状联合 5)r432=440 多个分离世代的分离分析的思路完成的,这就意免 了具有相同成分分布敷时不能区分是1对主基因控 4】 制的还是2对主基因控制的缺陷,并且在分布参数 的估计中考患了相应的遗传背景, 章元明,盖购版.数量性状分高分析中分布参数估计的1BC过 算接1J小.作物学,2000.266):699-06 在估计一阶造传参数时利用亲本和F的平均 章元,药.利 数资料,这对确定主基因效应相对大小是有作用的 DH攻L群体定QTL体系并估计其 传 并能有效地解亲本、,和F,,体的表现。这是 因为B,与P 之闷差异可度量基因的加性效应,中 亲值与F,间差异可度量基因的显性效应的缘故 [8]】王能康,盖药量利月函形分析鉴定数量性状蜜传体系中的主 基因】.流传,1998,20(增利):139-140 万方数据 遗传HEREDITAS(Btijing)2001 23卷 』.酏,k=一3.36,b 6.90,[d]=3.28,[h]= 一3.42。这一遗传参数估计结果既能有效地解释亲 本和F,的表现,又能解释F2:3群体的表现。因此,在 利用单一分离群体进行分离分析时加进亲本和F1群 体平均数估计一阶遗传参数是十分有效的方法。 通过上述一阶遗传参数估计值计算F2:3群体各 主基因型的理论值,由所获得的理论值计算F2:,群体 主基因遗传方差:口乙=1.2437;进而计算多基因遗传 方差:口:.=3.2526—1.2437—1.7276=0.2813。由 此,主基因遗传率^:.=1.2437/3.2526=38.24%,多 基因遗传率口:.=0.2813/3.2526=8.70%。 寰4遗传囊型的Me位 Table 4 AIC va№lIⅡder variom gelefle models 衰5 B:3群体配合A一0.A一1.B一1.C.D一1和E一1曩型的适合性控譬 TBble 5 T柏of陋of-fltfzrModekA一0·A一1,B一1-c—D一1蛐dE一1 inBt3 population 利用家系重复试验资料的分离分析与文献”J 利用单株资料的分离分析比较,前者一方面可降低 误差以提高参数估计精度,另一方面只需一次就可 鉴定出数量性状的遗传模式。王健康等(1997)和盖 钧镒等(1998)是首先确定成分分布数然后确定遗传 模型的【I,2],本文是利用文献[3,4]的数量性状联合 多个分离世代的分离分析的思路完成的,这就避免 了具有相同成分分布数时不能区分是1对主基因控 制的还是2对主基因控制的缺陷,并且在分布参数 的估计中考虑了相应的遗传背景。 在估计一阶遗传参数时利用亲本和F1的平均 数资料,这对确定主基因效应相对太小是有作用的 并能有效地解释亲本、F1和F2:,群体的表现。这是 因为P.与P2之间差异可度量基因的加性效应,中 亲值与F.间差异可度量基因的显性效应的缘故。 ●考文献(Re缸rp,llcdg): [1]盏钧幢.王健康.利用回空世代或B:,采系世代鉴定鼓量性状主基 周一多基周摁合遗传模型[J].作钓学报.1998.24(4):舯2—403. [2]王健康,董均蟹.利用杂种F2世代鉴定数量性状主基因一刍基 因程合遗传模型井估计其遗传效应[J].遗传学报,1997.24 (5):432—440. [3]王量康,盏均坐.数量性状主基因一多基因混台遗传舶PI、FI、B、 R和F2:,联合分折方法[J]作物学报.19孵,2“时:651—659 [4]Gai J Y,Wang J K.[dentifiealinn and ettlmatloa of-QTL model andit*tfff∞ts[J1.Thoor^P—G,eltm,1998.97(7):1162—1168. [5]章元嚼,董犄崔.数量性状分离分析中分布’散估计的IEC~I 算法[J】.作物学报,2000,26(6):699—706 [6】章元明.盖钧■.利用DH或RIL群体鉴定QTL体系井估计其 遗传赦应[J].量传学报,2∞o.27(7):634—640. [7]董钧■,王健摩.利用回交世代鉴定数量性状主基因一多基因 混合鼍传模盘[J].遗传.1998,20(增刊):110—111 [8]王健康.盏钧崔.刺用图形分析鉴定教量性壮遗传体车中的主 基因[J].遗传.1998,20(增刊):139—140 万方数据