正在加载图片...
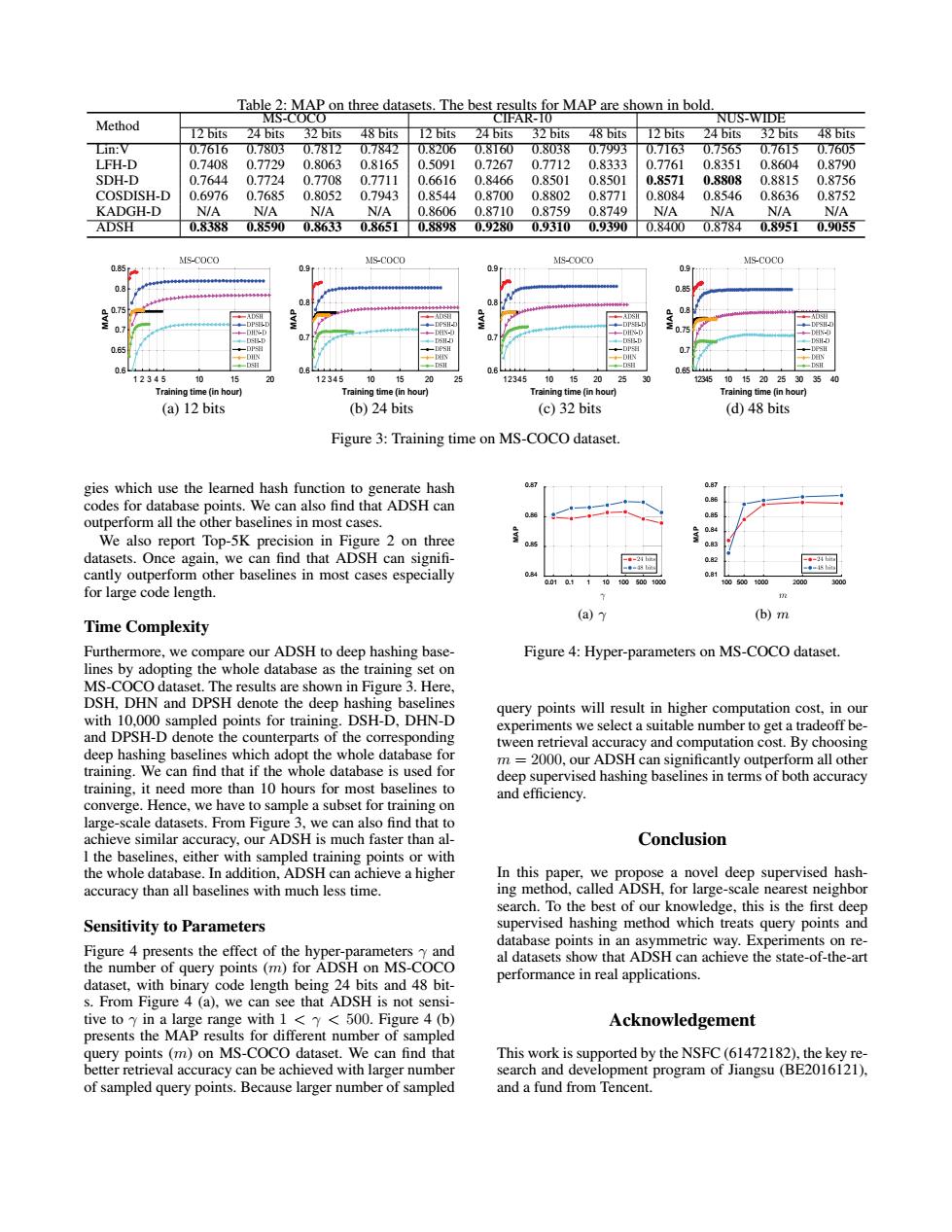
Table 2:MAP on three datasets.The best results for MAP are shown in bold. MS-COCO CIFAR-10 NUS-WIDE Method 12 bits 24 bits 32bits 48 bits 12 bits 24 bits 32 bits 48 bits 12 bits 24 bits 32 bits 48 bits Lin:V 0.76I60.7803 0.78T2 0.7842 0.8206 0.8I600.8038 0.7993 0.7T63 0.7565 0.7615 0.7605 LFH-D 0.7408 0.7729 0.8063 0.8165 0.5091 0.7267 0.7712 0.8333 0.7761 0.8351 0.8604 0.8790 SDH-D 0.7644 0.7724 0.7708 0.7711 0.6616 0.8466 0.8501 0.8501 0.8571 0.8808 0.8815 0.8756 COSDISH-D 0.6976 0.7685 0.8052 0.7943 0.8544 0.8700 0.8802 0.8771 0.8084 0.8546 0.8636 0.8752 KADGH-D N/A N/A N/A N/a 0.8606 0.8710 0.8759 0.8749 N/A N/A N/A N/A ADSH 083880.85900.8633 0.8651 0.88980.92800.93100.93900.8400 0.87840.8951 0.9055 MS-COCO MS-COCO MS-COCO MS-COCO 0.85 09 0.8 0.75 07 075 0.65 0.6 08 0.6 0.65 12345 10 15 12345 10 15 20 12345 101520 25 12345 101520253035 Training time(in hour) Training time(in hour) Training time(in hour) Training time(in hour) (a)12 bits (b)24 bits (c)32 bits (d)48 bits Figure 3:Training time on MS-COCO dataset. gies which use the learned hash function to generate hash 0.8 codes for database points.We can also find that ADSH can 0.86 .85 outperform all the other baselines in most cases. We also report Top-5K precision in Figure 2 on three 0.83 datasets.Once again,we can find that ADSH can signifi- 0.2 cantly outperform other baselines in most cases especially 0.81 001a11101005001080 1005001000 for large code length. (a)y (b)m Time Complexity Furthermore,we compare our ADSH to deep hashing base- Figure 4:Hyper-parameters on MS-COCO dataset. lines by adopting the whole database as the training set on MS-COCO dataset.The results are shown in Figure 3.Here, DSH,DHN and DPSH denote the deep hashing baselines query points will result in higher computation cost,in our with 10,000 sampled points for training.DSH-D,DHN-D experiments we select a suitable number to get a tradeoff be- and DPSH-D denote the counterparts of the corresponding tween retrieval accuracy and computation cost.By choosing deep hashing baselines which adopt the whole database for training.We can find that if the whole database is used for m =2000,our ADSH can significantly outperform all other deep supervised hashing baselines in terms of both accuracy training,it need more than 10 hours for most baselines to and efficiency. converge.Hence,we have to sample a subset for training on large-scale datasets.From Figure 3,we can also find that to achieve similar accuracy,our ADSH is much faster than al- Conclusion I the baselines,either with sampled training points or with the whole database.In addition,ADSH can achieve a higher In this paper,we propose a novel deep supervised hash- accuracy than all baselines with much less time. ing method,called ADSH,for large-scale nearest neighbor search.To the best of our knowledge,this is the first deep Sensitivity to Parameters supervised hashing method which treats query points and database points in an asymmetric way.Experiments on re- Figure 4 presents the effect of the hyper-parameters y and al datasets show that ADSH can achieve the state-of-the-art the number of query points(m)for ADSH on MS-COCO dataset,with binary code length being 24 bits and 48 bit- performance in real applications. s.From Figure 4(a),we can see that ADSH is not sensi- tive to y in a large range with 1 <y<500.Figure 4 (b) Acknowledgement presents the MAP results for different number of sampled query points (m)on MS-COCO dataset.We can find that This work is supported by the NSFC(61472182),the key re- better retrieval accuracy can be achieved with larger number search and development program of Jiangsu(BE2016121), of sampled query points.Because larger number of sampled and a fund from Tencent.Table 2: MAP on three datasets. The best results for MAP are shown in bold. Method MS-COCO CIFAR-10 NUS-WIDE 12 bits 24 bits 32 bits 48 bits 12 bits 24 bits 32 bits 48 bits 12 bits 24 bits 32 bits 48 bits Lin:V 0.7616 0.7803 0.7812 0.7842 0.8206 0.8160 0.8038 0.7993 0.7163 0.7565 0.7615 0.7605 LFH-D 0.7408 0.7729 0.8063 0.8165 0.5091 0.7267 0.7712 0.8333 0.7761 0.8351 0.8604 0.8790 SDH-D 0.7644 0.7724 0.7708 0.7711 0.6616 0.8466 0.8501 0.8501 0.8571 0.8808 0.8815 0.8756 COSDISH-D 0.6976 0.7685 0.8052 0.7943 0.8544 0.8700 0.8802 0.8771 0.8084 0.8546 0.8636 0.8752 KADGH-D N/A N/A N/A N/A 0.8606 0.8710 0.8759 0.8749 N/A N/A N/A N/A ADSH 0.8388 0.8590 0.8633 0.8651 0.8898 0.9280 0.9310 0.9390 0.8400 0.8784 0.8951 0.9055 Training time (in hour) 12 34 5 10 15 20 MAP 0.6 0.65 0.7 0.75 0.8 0.85 (a) 12 bits Training time (in hour) 12345 10 15 20 25 MAP 0.6 0.7 0.8 0.9 (b) 24 bits Training time (in hour) 12345 10 15 20 25 30 MAP 0.6 0.7 0.8 0.9 (c) 32 bits Training time (in hour) 12345 10 15 20 25 30 35 40 MAP 0.65 0.7 0.75 0.8 0.85 0.9 (d) 48 bits Figure 3: Training time on MS-COCO dataset. gies which use the learned hash function to generate hash codes for database points. We can also find that ADSH can outperform all the other baselines in most cases. We also report Top-5K precision in Figure 2 on three datasets. Once again, we can find that ADSH can signifi- cantly outperform other baselines in most cases especially for large code length. Time Complexity Furthermore, we compare our ADSH to deep hashing baselines by adopting the whole database as the training set on MS-COCO dataset. The results are shown in Figure 3. Here, DSH, DHN and DPSH denote the deep hashing baselines with 10,000 sampled points for training. DSH-D, DHN-D and DPSH-D denote the counterparts of the corresponding deep hashing baselines which adopt the whole database for training. We can find that if the whole database is used for training, it need more than 10 hours for most baselines to converge. Hence, we have to sample a subset for training on large-scale datasets. From Figure 3, we can also find that to achieve similar accuracy, our ADSH is much faster than all the baselines, either with sampled training points or with the whole database. In addition, ADSH can achieve a higher accuracy than all baselines with much less time. Sensitivity to Parameters Figure 4 presents the effect of the hyper-parameters γ and the number of query points (m) for ADSH on MS-COCO dataset, with binary code length being 24 bits and 48 bits. From Figure 4 (a), we can see that ADSH is not sensitive to γ in a large range with 1 < γ < 500. Figure 4 (b) presents the MAP results for different number of sampled query points (m) on MS-COCO dataset. We can find that better retrieval accuracy can be achieved with larger number of sampled query points. Because larger number of sampled 0.01 0.1 1 10 100 500 1000 MAP 0.84 0.85 0.86 0.87 (a) γ 100 500 1000 2000 3000 MAP 0.81 0.82 0.83 0.84 0.85 0.86 0.87 (b) m Figure 4: Hyper-parameters on MS-COCO dataset. query points will result in higher computation cost, in our experiments we select a suitable number to get a tradeoff between retrieval accuracy and computation cost. By choosing m = 2000, our ADSH can significantly outperform all other deep supervised hashing baselines in terms of both accuracy and efficiency. Conclusion In this paper, we propose a novel deep supervised hashing method, called ADSH, for large-scale nearest neighbor search. To the best of our knowledge, this is the first deep supervised hashing method which treats query points and database points in an asymmetric way. Experiments on real datasets show that ADSH can achieve the state-of-the-art performance in real applications. Acknowledgement This work is supported by the NSFC (61472182), the key research and development program of Jiangsu (BE2016121), and a fund from Tencent