正在加载图片...
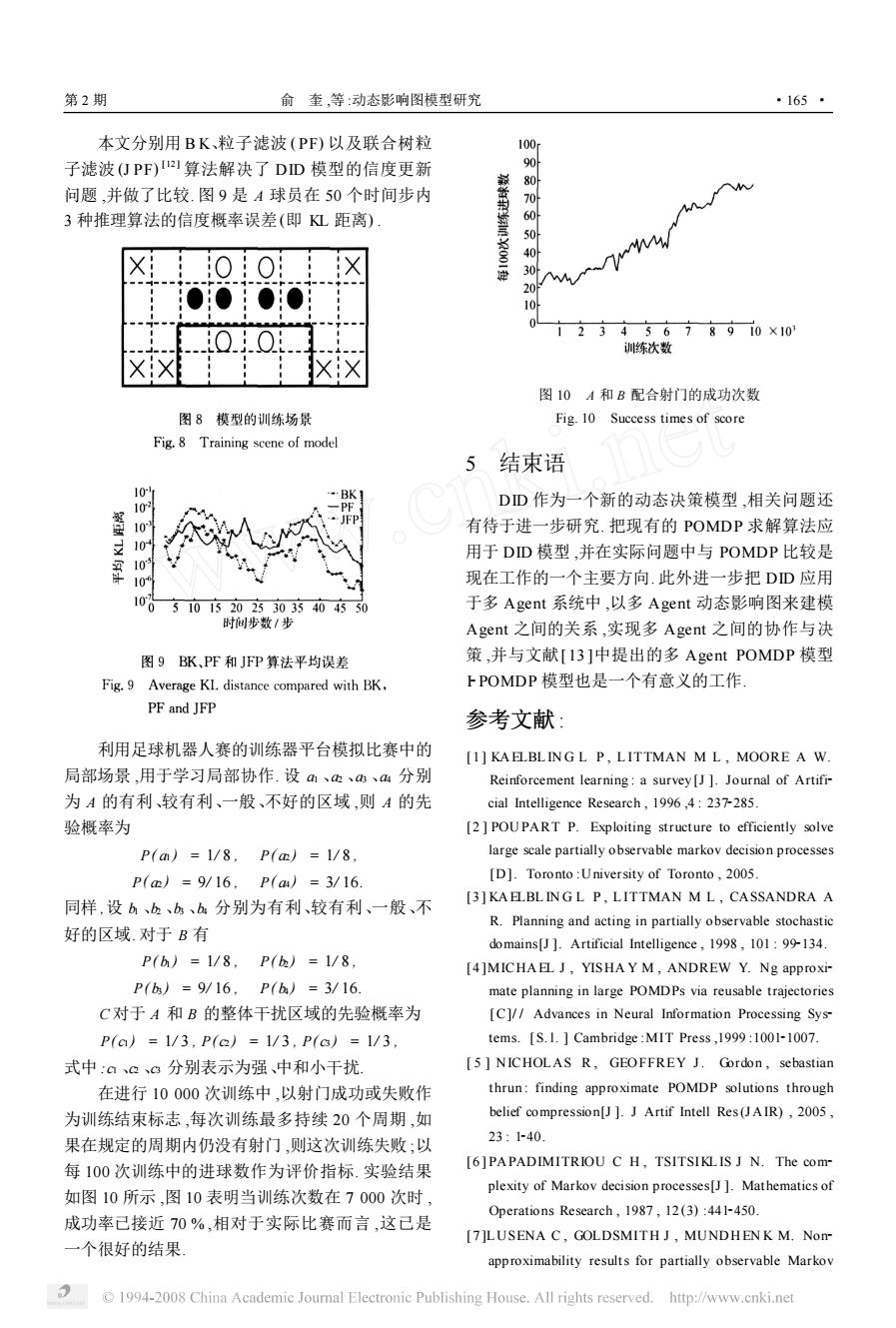
第2期 俞奎,等:动态影响图模型研究 ·165· 本文分别用BK、粒子滤波(PF)以及联合树粒 100 子滤波(仃PF)2算法解决了DD模型的信度更新 问题,并做了比较.图9是A球员在50个时间步内 3种推理算法的信度概率误差(即L距离) 40 M 30 20 00 10 0..0 2345678910×10 训练次数 图10A和B配合射门的成功次数 图8模型的训练场景 Fig.10 Success times of score Fig.8 Training scene of model 5结束语 0 BK】 10 DD作为一个新的动态决策模型,相关问题还 有待于进一步研究.把现有的POMDP求解算法应 10 用于DD模型,并在实际问题中与POMDP比较是 109 现在工作的一个主要方向.此外进一步把DD应用 100 5101520233035404550 于多Agent系统中,以多Agent动态影响图来建模 时间步数/步 Agent之间的关系,实现多Agent之间的协作与决 图9BK、PF和JFP算法平均误差 策,并与文献[I3]中提出的多Agent POMDP模型 Fig.9 Average KL distance compared with BK, FPOMDP模型也是一个有意义的工作 PF and JFP 参考文献: 利用足球机器人赛的训练器平台模拟比赛中的 [1]KAELBLINGL P,LITTMAN M L,MOORE A W 局部场景,用于学习局部协作.设m、、、4分别 Reinforcement learning:a survey [J ]Journal of Artifi- 为A的有利、较有利、一般、不好的区域,则A的先 cial Intelligence Research,1996,4:237-285. 验概率为 [2]POUPART P.Exploiting structure to efficiently solve P(am)=1/8,P(m)=1/8, large scale partially observable markov decision processes P(m)=9/16,P(aa)=3/16 [D].Toronto:University of Toronto,2005. [3]KA ELBLINGL P,LITTMAN M L,CASSANDRA A 同样,设b、b、bs、b分别为有利、较有利、一般、不 R.Planning and acting in partially observable stochastic 好的区域.对于B有 domains[J ]Artificial Intelligence,1998,101:99-134. P(h)=1/8,P()=1/8, [4]MICHAEL J,YISHA Y M,ANDREW Y.Ng approxi- P(b)=9/16,P(h)=3/16 mate planning in large POMDPs via reusable trajectories C对于A和B的整体干扰区域的先验概率为 [C]//Advances in Neural Information Processing Sys- P(ca)=1/3,P(a)=1/3,P(c6)=1/3 tems.[S.1.Cambridge:MIT Press,1999:1001-1007. 式中:a。3分别表示为强、中和小千扰 [5 NICHOLAS R,GEOFFREY J.Gordon,sebastian 在进行10000次训练中,以射门成功或失败作 thrun:finding approximate POMDP solutions through 为训练结束标志,每次训练最多持续20个周期,如 belief compression[J ]J Artif Intell Res(JAIR),2005, 果在规定的周期内仍没有射门,则这次训练失败;以 23:1-40. 每100次训练中的进球数作为评价指标.实验结果 [6]PAPADIMITRIOU C H,TSITSIKLIS J N.The com- plexity of Markov decision processes[J ]Mathematics of 如图10所示,图10表明当训练次数在7000次时, Operations Research,1987,12(3):441-450. 成功率己接近70%,相对于实际比赛而言,这己是 [7]LUSENA C,GOLDSMITH J,MUNDHENK M.Nom 一个很好的结果 approximability results for partially observable Markov 1994-2008 China Academic Journal Electronic Publishing House.All rights reserved.http://www.cnki.net本文分别用 B K、粒子滤波 (PF) 以及联合树粒 子滤波 (J PF) [12 ] 算法解决了 DID 模型的信度更新 问题 ,并做了比较. 图 9 是 A 球员在 50 个时间步内 3 种推理算法的信度概率误差(即 KL 距离) . 利用足球机器人赛的训练器平台模拟比赛中的 局部场景 ,用于学习局部协作. 设 a1 、a2 、a3 、a4 分别 为 A 的有利、较有利、一般、不好的区域 ,则 A 的先 验概率为 P( a1 ) = 1/ 8 , P( a2 ) = 1/ 8 , P( a2 ) = 9/ 16 , P( a4 ) = 3/ 16. 同样 ,设 b1 、b2 、b3 、b4 分别为有利、较有利、一般、不 好的区域. 对于 B 有 P( b1 ) = 1/ 8 , P( b2 ) = 1/ 8 , P( b3 ) = 9/ 16 , P( b4 ) = 3/ 16. C 对于 A 和 B 的整体干扰区域的先验概率为 P( c1 ) = 1/ 3 , P( c2 ) = 1/ 3 , P( c3 ) = 1/ 3 , 式中 :c1 、c2 、c3 分别表示为强、中和小干扰. 在进行 10 000 次训练中 ,以射门成功或失败作 为训练结束标志 ,每次训练最多持续 20 个周期 ,如 果在规定的周期内仍没有射门 ,则这次训练失败 ;以 每 100 次训练中的进球数作为评价指标. 实验结果 如图 10 所示 ,图 10 表明当训练次数在 7 000 次时 , 成功率已接近 70 % ,相对于实际比赛而言 ,这已是 一个很好的结果. 图 10 A 和 B 配合射门的成功次数 Fig. 10 Success times of score 5 结束语 DID 作为一个新的动态决策模型 ,相关问题还 有待于进一步研究. 把现有的 POMDP 求解算法应 用于 DID 模型 ,并在实际问题中与 POMDP 比较是 现在工作的一个主要方向. 此外进一步把 DID 应用 于多 Agent 系统中 ,以多 Agent 动态影响图来建模 Agent 之间的关系 ,实现多 Agent 之间的协作与决 策 ,并与文献[ 13 ]中提出的多 Agent POMDP 模型 I2POMDP 模型也是一个有意义的工作. 参考文献 : [1 ] KA ELBL IN G L P , L ITTMAN M L , MOORE A W. Reinforcement learning : a survey[J ]. Journal of Artifi2 cial Intelligence Research , 1996 ,4 : 2372285. [2 ] POUPART P. Exploiting structure to efficiently solve large scale partially observable markov decision processes [D]. Toronto :University of Toronto , 2005. [3 ] KA ELBL IN G L P , L ITTMAN M L , CASSANDRA A R. Planning and acting in partially observable stochastic domains[J ]. Artificial Intelligence , 1998 , 101 : 992134. [4 ]MICHA EL J , YISHA Y M , ANDREW Y. Ng approxi2 mate planning in large POMDPs via reusable trajectories [C]/ / Advances in Neural Information Processing Sys2 tems. [ S. l. ] Cambridge :MIT Press ,1999 :100121007. [ 5 ] NICHOLAS R , GEOFFREY J. Gordon , sebastian thrun : finding approximate POMDP solutions through belief compression[J ]. J Artif Intell Res(J AIR) , 2005 , 23 : 1240. [6 ] PAPADIMITRIOU C H , TSITSIKL IS J N. The com2 plexity of Markov decision processes[J ]. Mathematics of Operations Research , 1987 , 12 (3) :4412450. [7 ]LUSENA C , GOLDSMITH J , MUNDHEN K M. Non2 approximability results for partially observable Markov 第 2 期 俞 奎 ,等 :动态影响图模型研究 · 561 ·