正在加载图片...
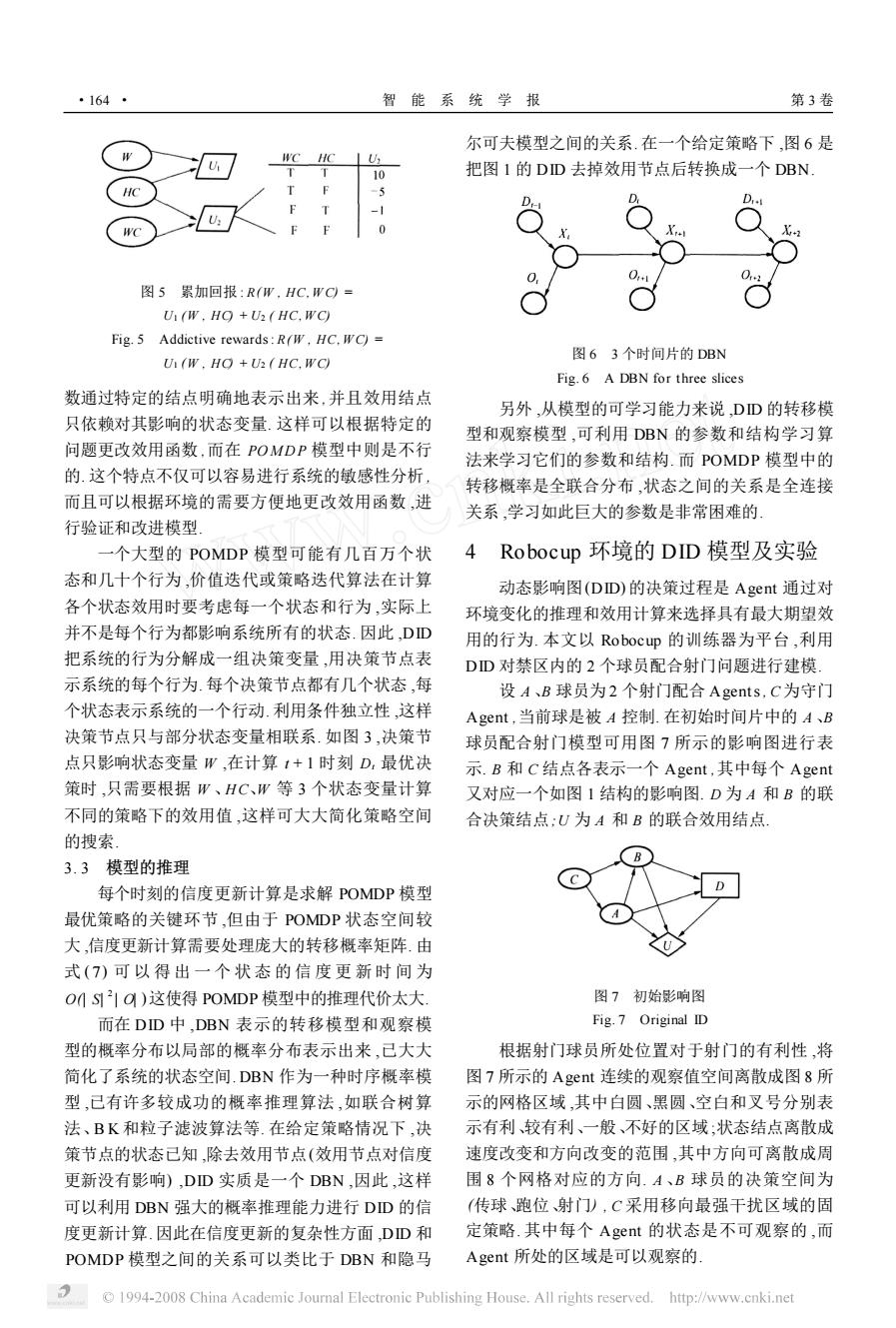
·164- 智能系统学报 第3卷 尔可夫模型之间的关系.在一个给定策略下,图6是 WC HC 10 把图I的DD去掉效用节点后转换成一个DBN 图5累加回报:R(W,HC.WC= U(W.HO +U(HC.WC) Fig.5 Addictive rewards:R(W,HC.WC)= 图63个时间片的DBN U(W.HO +U2(HC.WC) Fig.6 A DBN for three slices 数通过特定的结点明确地表示出来,并且效用结点 另外,从模型的可学习能力来说,DD的转移模 只依赖对其影响的状态变量.这样可以根据特定的 型和观察模型,可利用DBN的参数和结构学习算 问题更改效用函数,而在POMDP模型中则是不行 法来学习它们的参数和结构.而POMDP模型中的 的.这个特点不仅可以容易进行系统的敏感性分析, 转移概率是全联合分布,状态之间的关系是全连接 而且可以根据环境的需要方便地更改效用函数,进 关系,学习如此巨大的参数是非常困难的」 行验证和改进模型 一个大型的POMDP模型可能有几百万个状 4 Robocup环境的DID模型及实验 态和几十个行为,价值迭代或策略迭代算法在计算 动态影响图(DD)的决策过程是Agent通过对 各个状态效用时要考虑每一个状态和行为,实际上 环境变化的推理和效用计算来选择具有最大期望效 并不是每个行为都影响系统所有的状态.因此,DD 用的行为.本文以Robocup的训练器为平台,利用 把系统的行为分解成一组决策变量,用决策节点表 DD对禁区内的2个球员配合射门问题进行建模: 示系统的每个行为.每个决策节点都有几个状态,每 设A、B球员为2个射门配合Agents,C为守门 个状态表示系统的一个行动.利用条件独立性,这样 Agent,当前球是被A控制.在初始时间片中的A、B 决策节点只与部分状态变量相联系.如图3,决策节 球员配合射门模型可用图7所示的影响图进行表 点只影响状态变量W,在计算1+1时刻D,最优决 示.B和C结点各表示一个Agent,其中每个Agent 策时,只需要根据W、HC、W等3个状态变量计算 又对应一个如图1结构的影响图.D为A和B的联 不同的策略下的效用值,这样可大大简化策略空间 合决策结点:U为A和B的联合效用结点 的搜索。 3.3模型的推理 每个时刻的信度更新计算是求解POMDP模型 最优策略的关键环节,但由于POMDP状态空间较 大,信度更新计算需要处理庞大的转移概率矩阵.由 式(7)可以得出一个状态的信度更新时间为 OMS21O)这使得POMDP模型中的推理代价太大. 图7初始影响图 而在DD中.DBN表示的转移模型和观察模 Fig.7 Original ID 型的概率分布以局部的概率分布表示出来,己大大 根据射门球员所处位置对于射门的有利性,将 简化了系统的状态空间.DBN作为一种时序概率模 图7所示的Agent连续的观察值空间离散成图8所 型,已有许多较成功的概率推理算法,如联合树算 示的网格区域,其中白圆、黑圆、空白和叉号分别表 法、BK和粒子滤波算法等.在给定策略情况下,决 示有利较有利、一般、不好的区域;状态结点离散成 策节点的状态已知,除去效用节点(效用节点对信度 速度改变和方向改变的范围,其中方向可离散成周 更新没有影响),DD实质是一个DBN,因此,这样 围8个网格对应的方向.A、B球员的决策空间为 可以利用DBN强大的概率推理能力进行DD的信 (传球、跑位射门),C采用移向最强干扰区域的固 度更新计算.因此在信度更新的复杂性方面,DD和 定策略.其中每个Aget的状态是不可观察的,而 POMDP模型之间的关系可以类比于DBN和隐马 Agent所处的区域是可以观察的 1994-2008 China Academic Journal Electronic Publishing House.All rights reserved.http://www.cnki.net图 5 累加回报 : R(W , HC, W C) = U1 (W , HC) + U2 ( HC, W C) Fig. 5 Addictive rewards: R(W , HC, W C) = U1 (W , HC) + U2 ( HC, W C) 数通过特定的结点明确地表示出来 ,并且效用结点 只依赖对其影响的状态变量. 这样可以根据特定的 问题更改效用函数 ,而在 POMD P 模型中则是不行 的. 这个特点不仅可以容易进行系统的敏感性分析 , 而且可以根据环境的需要方便地更改效用函数 ,进 行验证和改进模型. 一个大型的 POMDP 模型可能有几百万个状 态和几十个行为 ,价值迭代或策略迭代算法在计算 各个状态效用时要考虑每一个状态和行为 ,实际上 并不是每个行为都影响系统所有的状态. 因此 ,DID 把系统的行为分解成一组决策变量 ,用决策节点表 示系统的每个行为. 每个决策节点都有几个状态 ,每 个状态表示系统的一个行动. 利用条件独立性 ,这样 决策节点只与部分状态变量相联系. 如图 3 ,决策节 点只影响状态变量 W ,在计算 t + 1 时刻 Dt 最优决 策时 ,只需要根据 W 、H C、W 等 3 个状态变量计算 不同的策略下的效用值 ,这样可大大简化策略空间 的搜索. 3. 3 模型的推理 每个时刻的信度更新计算是求解 POMDP 模型 最优策略的关键环节 ,但由于 POMDP 状态空间较 大 ,信度更新计算需要处理庞大的转移概率矩阵. 由 式 ( 7) 可 以 得 出 一 个 状 态 的 信 度 更 新 时 间 为 O(| S| 2 | O| )这使得 POMDP 模型中的推理代价太大. 而在 DID 中 ,DBN 表示的转移模型和观察模 型的概率分布以局部的概率分布表示出来 ,已大大 简化了系统的状态空间. DBN 作为一种时序概率模 型 ,已有许多较成功的概率推理算法 ,如联合树算 法、B K 和粒子滤波算法等. 在给定策略情况下 ,决 策节点的状态已知 ,除去效用节点(效用节点对信度 更新没有影响) ,DID 实质是一个 DBN ,因此 ,这样 可以利用 DBN 强大的概率推理能力进行 DID 的信 度更新计算. 因此在信度更新的复杂性方面 ,DID 和 POMDP 模型之间的关系可以类比于 DBN 和隐马 尔可夫模型之间的关系. 在一个给定策略下 ,图 6 是 把图 1 的 DID 去掉效用节点后转换成一个 DBN. 图 6 3 个时间片的 DBN Fig. 6 A DBN for three slices 另外 ,从模型的可学习能力来说 ,DID 的转移模 型和观察模型 ,可利用 DBN 的参数和结构学习算 法来学习它们的参数和结构. 而 POMDP 模型中的 转移概率是全联合分布 ,状态之间的关系是全连接 关系 ,学习如此巨大的参数是非常困难的. 4 Robocup 环境的 DID 模型及实验 动态影响图(DID) 的决策过程是 Agent 通过对 环境变化的推理和效用计算来选择具有最大期望效 用的行为. 本文以 Robocup 的训练器为平台 ,利用 DID 对禁区内的 2 个球员配合射门问题进行建模. 设 A 、B 球员为 2 个射门配合 Agents, C为守门 Agent ,当前球是被 A 控制. 在初始时间片中的 A 、B 球员配合射门模型可用图 7 所示的影响图进行表 示. B 和 C 结点各表示一个 Agent ,其中每个 Agent 又对应一个如图 1 结构的影响图. D 为 A 和 B 的联 合决策结点;U 为 A 和 B 的联合效用结点. 图 7 初始影响图 Fig. 7 Original ID 根据射门球员所处位置对于射门的有利性 ,将 图 7 所示的 Agent 连续的观察值空间离散成图 8 所 示的网格区域 ,其中白圆、黑圆、空白和叉号分别表 示有利、较有利、一般、不好的区域 ;状态结点离散成 速度改变和方向改变的范围 ,其中方向可离散成周 围 8 个网格对应的方向. A 、B 球员的决策空间为 (传球、跑位、射门) , C 采用移向最强干扰区域的固 定策略. 其中每个 Agent 的状态是不可观察的 ,而 Agent 所处的区域是可以观察的. · 461 · 智 能 系 统 学 报 第 3 卷